
Datos
Introducción a las probabilidades
Haciendo estimaciones
Tanto si te gusta o no te gusta ver deportes en televisión, es una excelente forma de ver las probabilidades en acción. Veamos un ejemplo.
Dos amigos están viendo un partido de fútbol en un bar. El amigo “A” nunca ha visto un partido de fútbol y no sabe nada de los equipos que juegan. Lo único que sabe es que un equipo tiene que ganar y que no es posible empatar. El amigo A, como no sabe nada de futbol estima que la probabilidad que el equipo azul gane es de un 50% al igual que el equipo rojo.
El amigo “B” ha oído que el equipo azul es el actual campeón de Europa y tiene una clasificación mundial más alta, mientras que al equipo rojo le faltan varios jugadores clave. El amigo “B” sabe más que el amigo “A” y por tanto, le da una probabilidad mayor de victoria al equipo azul por los antecedentes que el maneja.
El camarero también está viendo el partido y sabe una cosa que los otros dos no saben: El partido que se está viendo es una grabación. El partido real terminó hace unas horas y ganó el equipo rojo. Por esta información, el camarero le da un 100% de probabilidad al equipo rojo.
Los tres espectadores pueden estimar la probabilidad de cada resultado, y todas sus estimaciones tienen sentido en función de la información que disponen.
La probabilidad nos permite estimar la posibilidad de que se produzca un acontecimiento a partir de la información que disponemos.
Escuchando a los dos amigos, el camarero se da cuenta que ellos no han visto el partido y piensan que se está transmitiendo en vivo. Queriendo aprovecharse de la situación, el camarero apuesta 100.000 pesos a que gana el equipo rojo.
El amigo “A” no sabe nada de futbol, pero ahora si sabe algo. Alguien cree que el equipo rojo va a ganar. Esto debería hacer que las posibilidades de que el equipo rojo gane aumenten un poco para el amigo “A”.
Otros factores inciden en las probabilidades que tenga cada uno, como si un equipo mete un gol, el mejor jugador del equipo sale lesionado, etc. En el transcurso del partido las probabilidades pueden ir alterándose permanentemente.
Siempre que obtengamos nueva información, debemos estar dispuestos a cambiar nuestras estimaciones de probabilidad.
El partido que nos referimos es la final de la copa de mujeres entre España e Inglaterra del año 2023. España, de rojo, venció a Inglaterra, de azul, por 1 a 0. Examinando sus resultados en partidos anteriores, la probabilidad que España ganara el partido era de un 47% antes de comenzar el juego. Sin embargo, una vez que España hizo un gol, esa probabilidad se disparó a más del 75%. En un computador podemos tener una simulación que intente replicar varios partidos de estos dos equipos en la vida real. La probabilidad de que España gane sería la cantidad de veces que ganó en la simulación dividido por el total de partidos.
\(Probabilidad = \frac{\text{Cantidad de casos positivos}}{\text{Cantidad de casos totales}}\)
El pasado y el futuro
La Premier League inglesa es la liga deportiva más vista del mundo. Los jugadores no pueden oír a los miles de millones de telespectadores, pero sí sienten el clamor de las decenas de miles de personas presentes en el estadio, que en su mayoría animan al equipo local.Para entender bien como el clamor del público influye en el resultado, veamos la siguiente tabla:
| Resultado | Cuenta |
|---|---|
| Local Ganador | 163 |
| Visitante Ganador | 129 |
| Empate | 88 |
| Total | 380 |
La tabla muestra el número de victorias locales, victorias visitantes y empates en la temporada de la Premier League que finalizó en 2022. Hay 163 victorias para el equipo local, en comparación con 129 victorias para el equipo visitante, así que parece que jugar en casa ayuda al equipo local a ganar partidos, aproximadamente en 163/380 = 43%.
Si eliges un partido al azar de los juegos jugados en esta temporada, la probabilidad de que el equipo local gane es simplemente la proporción de victorias locales en la temporada. Sin embargo, ¿podríamos decir que la probabilidad de un nuevo partido que no hemos visto y que juega de local, tiene la misma probabilidad de ganar? Cuando las cosas aún no ocurren, debemos mirar al pasado y hacer conjeturas y un 43% de probabilidad de victoria es un número razonable.
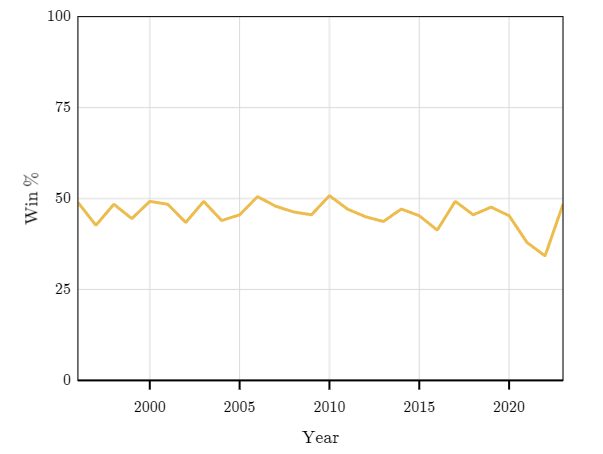
Este gráfico muestra la tasa de victorias de equipos locales en la Premier League desde 1995. El gráfico muestra variaciones año a año, pero el promedio se ha mantenido casi constante. Si la proporción media de partidos ganados por el equipo local no ha cambiado con el tiempo, podemos obtener una estimación más fiable utilizando datos de más años, ya que así se reducirá el efecto de la variación aleatoria.
Siempre y cuando no creamos que algo importante haya cambiado, el uso de más datos debería proporcionarnos una Victoria predicha más precisa del futuro. Sin embargo, no siempre es el caso. Más datos no siempre conducen a una mejor estimación de probabilidad. Consideremos el caso de un equipo individual, el campeón de la Premier League de Inglaterra en 2023, Manchester City. Desde que volvió a la Premier League en 2002, Manchester City ha ganado el 56% de los juegos, mientras que en la temporada 2023, ganaron el 74% de los juegos.
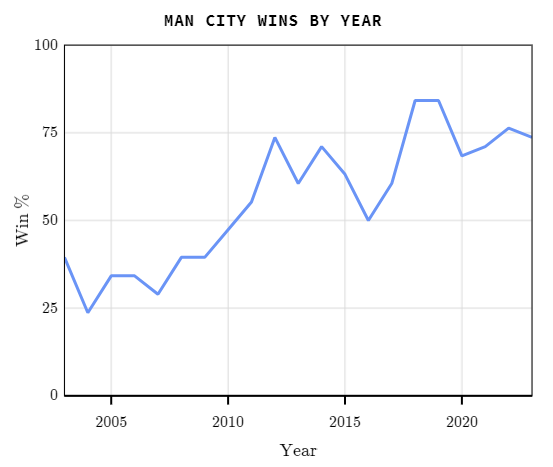
Con esta información vemos que es más dificil predecir como le irá al Manchester City en la temporada del 2024. Esto es porque, a diferencia del gráfico anterior, la tasa de victoria varia mucho en general. Lo que si sabemos es que el ratio de victorias ha aumentado en el tiempo y algo ocurrió en el equipo que comenzaron a obtener más victorias.
No tendría sentido utilizar datos de victorias del período en el que el equipo era mucho menos exitoso para predecir el futuro, ya que claramente algo ha cambiado desde entonces. Por ende, los últimos datos son mucho más relevantes a considerar para predecir de mejor manera como será la temporada del 2024.
Usualmente, utilizar más datos proporciona predicciones más confiables, pero cuando la situación cambia, los datos pasados pueden resultar engañosos. Entonces, ¿por qué han mejorado tanto los resultados del Manchester City desde 2003? Hay muchas razones posibles, pero su adquisición por parte del multimillonario Sheik Mansour en 2008 para convertirlos en uno de los equipos deportivos más ricos del mundo probablemente haya sido una gran ayuda.
Combinar probabilidades
¿Cuántos goles?
El fútbol es conocido por ser un juego con pocos goles. Antes de pasar 90 minutos viendo un partido, es posible que desees saber qué tan probable es que uno de los equipos anote cierta cantidad de goles. Utilizaremos una base de datos que recoge todos los partidos de la Premier League jugados entre 1993 y 2003. Son 12.026 partidos en total.
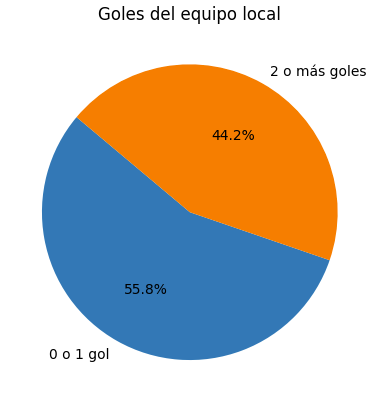
La probabilidad que el equipo local pueda hacer 0 o 1 gol es de un 56%. Si queremos saber la probabilidad que el equipo pueda hacer dos goles o más debemos restar el 100% con el 56%. Esto es lo que se llama probabilidad complementaria, dado que un evento no puede ocurrir si ocurre otro y viceversa, como la probabilidad que llueva o no llueva mañana o la probabilidad de ganar o perder dinero en el casino. Estos eventos son mutuamente excluyentes, por lo que, para su calculo, simplemente calculamos su complemento, como lo hicimos con los goles del equipo local. De manera similar, podemos calcular la probabilidad que un equipo haga X goles desde la base de datos antes mencionadas. Podemos filtrarla para llegar a estas probabilidades:
- Probabilidad que el equipo local haga 2 goles: 24.0%
- Probabilidad que el equipo local haga 3 goles: 12.0% Con estas dos probabilidades podemos calcular la probabilidad que un equipo local realice dos o tres goles.
\(24\% + 12\% = 36\%\)
Como ambos eventos son excluyentes entre sí (un equipo no puede meter dos y tres goles a la vez) podemos sumar las probabilidades, pero ojo, no siempre tendremos eventos que sean 100% excluyentes, asi que tenemos que poner atención en esos detalles.
Aquí la palabra clave es o, dado que cuando decimos que la probabilidad de que algo ocurra o que otro evento ocurra pensemos en la suma de probabilidades.
Goles de visitante
Si nos centramos en el entretenimiento en lugar de que el equipo local gane, entonces también debemos prestar atención a cuántos goles marca el equipo visitante.
- Probabilidad que el equipo local no haga goles: 23.0%
- Probabilidad que el equipo visitante no haga goles: 34.0%
Ahora sabemos que el equipo local no anota en el 23% de los juegos y el equipo visitante no anota en el 34%.
¿Con qué frecuencia crees que al menos un equipo no anote goles?
Podríamos pensar que la probabilidad que al menos un equipo no anote goles es de un 57%, resultado de la suma entre el 23% y el 34%. Sin embargo, debemos considerar que en probabilidades, debemos descartar los eventos que existan en común. En este caso, debemos calcular la probabilidad de que un equipo local tenga 0 goles, sumado a la probabilidad de que el equipo visitante tenga 0 goles y restamos la probabilidad de que ambos equipos tengan cero goles, porque de lo contrario, estariamos haciendo la suma dos veces. La probabilidad entonces debe ser menor al 57%.
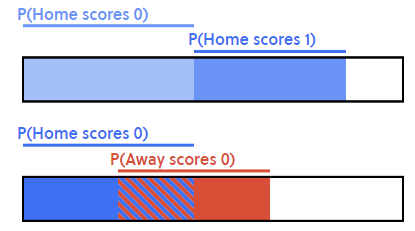
Cuando dos eventos no pueden ocurrir juntos, como el equipo local anotando tanto 0 goles como 1 gol, las probabilidades no se superponen.
Cuando dos eventos pueden ocurrir juntos, debemos filtrar la base de datos por cada evento y luego sumar esas probabilidades. Si realizamos ese procediimiento para calcular que el equipo local y visitante no hagan goles, nos dará un resultado del 8%.
\(P(\text{Equipo Local sin goles}) + P(\text{Equipo visitante sin goles}) = 8%\)
Donde \(P(A)\) es la probabilidad que ocurra un evento A Para calcular la probabilidad que al menos uno de los equipos no haga goles sumamos \(23\%\) con \(34\%\) y luego restamos el \(8\%\), dandonos una probabilidad total de \(49\%\). Debemos restar el 8%, porque ya está incluido dentro del 23% y 49%. Debemos restarlo para no duplicar conteos.
Esto nos deja la siguientes reglas de probabilidades:
Cuando dos eventos no pueden ocurrir simultáneamente, la probabilidad de que ocurra uno u otro es igual a la suma de las probabilidades de cada uno:
\(P(A o B) = P(A) + P(B).\)
Cuando ambos eventos pueden ocurrir simultáneamente, tenemos que restar la región de superposición, entonces:
\(P(A o B) = P(A) + P(B) - P(A y B).\)
Es genial que solo haya un 8% de probabilidad de no ver goles en un juego. ¿Pero qué tan probable es que veamos 2 o más goles de cualquiera de los equipos?
Para ello, primero debemos calcular la probabilidad que uno de los dos equipos hagan más de dos 0 más goles y luego restar la superposición.
- Probabilidad que el equipo local haga dos o más goles: 44%
- Probabilidad que el equipo visitante haga dos o más goles: 31%
- Probabilidad que ambos equipos hagan dos o más goles: 13%
Por lo tanto, como vimos, debemos restar la probabilidad superpuesta que es del 13%. Por lo tanto la respuesta es \(44\% + 31\% - 13\% = 62\%\) El fútbol puede tener pocos goles, pero en alrededor de dos tercios de los juegos al menos un equipo anota dos veces o más. Y para aquellos que sienten que eso no es suficiente, siempre está el baloncesto.
Probabilidad condicional
Ganando desde atrás
Cuando el equipo local va perdiendo a mitad de partido, todo el mundo en el estadio piensa lo mismo: ¿podrá recuperarse y ganar el partido? Cuando el equipo local está perdiendo en el medio tiempo, se recupera en el 2.5% de los casos ganando el partido. Por ejemplo, el 21-09-2014, Manchester United iba ganando en el medio tiempo a Lenchester por 2-1, pero terminó perdiendo por 5-3.Estos casos, a pesar que representan el 2.5% de los datos, no signfica que la probabilidad también sea de un 2.5%. Ahora veremos porque.
En este caso tenemos dos eventos distintos:
- El equipo local va perdiendo contra el visitante en el medio tiempo.
- El equipo visitante gana el partido.
Para que el equipo visitante gane el partido cuando está perdiendo deben ocurrir los eventos 1 y 2 al unísono, pero siempre para que ocurra el 2 debe ocurrir primero el 1. La probabilidad condicionada es aquella que ocurre cuando otro evento ya ocurrió. Por lo tanto, si solo queremos calcular la probabilidad de que el equipo visitante se recupere, debemos asumir que la probabilidad que el equipo local esté perdiendo en el medio tiempo ya ocurrió, vale decir, debemos asumir esa probabilidad como un 100%.
La probabilidad del evento 2 no es de un 2.5%, porque como asumimos que la probabilidad 1 ya ocurrió, la probabilidad es mayor.
Ahora sabemos que:
- El equipo local está detrás en el medio tiempo en el 25% de los partidos.
- El equipo local está detrás en el medio tiempo y gana el 2.5% de los partidos.
Esto significa que el equipo local puede esperar 2.5 victorias por cada 25 partidos en los que estén detrás en el medio tiempo.
2.5 victorias por cada 25 partidos corresponde a una probabilidad de \(\frac{2.5}{25} = 0.1\)
La probabilidad que el equipo local se recupere cuando está perdiendo en el medio tiempo es de un 10%. Sigue sin ser una gran posibilidad, pero no lo bastante baja como para perder la esperanza.
Cuando tenemos una probabilidad condicionada (que ocurra un Evento A cuando ya ocurrió otro evento B) la formula de calcularla es la siguiente:
\(P(A|B) = \frac{P(A \cap B)}{P(B)}\)
\(P(A \cap B)\) es lo mismo que \(P(A) x P(B)\) si y solo si A y B son eventos independientes entre sí. Sin embargo, para el caso de este ejemplo no lo son, porque hay superposición. Gráficamente podemos verlo así:

Vemos que la probabilidad en rojo es cuando el equipo de visita va ganando en el medio tiempo, la probabilidad en azul es cuando gana el equipo local. La superposición entre “Away Lead” (Ventaja del Visitante) y “Home Win” (Victoria Local) representa los partidos donde el equipo local gana después de ir perdiendo al medio tiempo.
Probabilidad total
Tarjetas rojas
Cuando un equipo de fútbol recibe una tarjeta roja, debe terminar el partido con diez jugadores en lugar de once. ¿Impactará en el resultado? Para obtener una respuesta revisaremos algo llamado probabilidad total. Para entenderlo, revisaremos el siguiente ejemplo:
Entre 2013 y 2023, el equipo local ganó el 45% de los partidos de la Premier League inglesa, mientras que el equipo visitante ganó el 32%.
¿Qué equipo crees que tiene más probabilidades de ganar el partido después de que alguien del equipo local reciba una tarjeta roja por juego sucio? Según datos extraidos de los partidos de la Premier League, la probabilidad de que uno o más jugadores reciban una tarjeta roja del equipo local y aún así ganen el partido es de un 1.2%. Sin embargo, para que eso pase necesitamos que saquen la tarjeta roja en primer lugar. Esto es una probabilidad condicionada. Por tanto tenemos:
- Probabilidad que el equipo local gane el partido con menos jugadores por tarjeta roja o \(P(A \cap B)\): 1.2%
- Probabilidad que al equipo local le saquen una o más tarjetas rojas o \(P(B)\): 5.1%
Por tanto, La información de que el equipo local ha recibido una tarjeta roja disminuye la probabilidad de que el equipo local gane del 0.45 al 0.24, y ahora es más probable una victoria visitante.
De la misma manera, podemos calcular la probabilidad de que el equipo local gane si no recibe tarjetas rojas. En esos casos, la probabilidad de ganar aumenta de 45%, que es la probabilidad de ganar antes que comience el juego, a 46%, pero baja a 24% si el arbitro echa a un jugador.
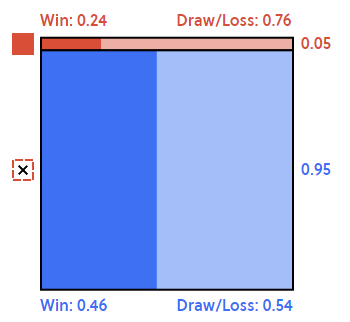
El cuadrado de la imagen tiene un área de uno, expresando la probabilidad total que pasen ciertos acontecimientos divididos por cuatro colores. El el área del color rojo, vemos un rojo fuerte que expresa la probabilidad que el equipo local gane con una tarjeta roja. Recordemos que esa probabilidad es considerando que el arbitro ya nos saco una roja. El área roja más opaca es si s si perdemos o empatamos, es decir, la probabilidad complementaria.
Para el área azul, representa el evento cuando el arbitro no nos ha sacado ninguna tarjeta roja, aumentando nuestra probabilidad a ganar a 46%, como mencionamos anteriormente. El área azul más opaca es la probabilidad complemtaria.
Para calcular la probabilidad que el equipo local gane y que tenga una tarjeta roja, sin condicionar nada, debemos calcular el área del rectangulo rojo oscuro, que es 0.05 * 0.24, que equivale a 0.012, que es lo mismo que \(P(A \cap B)\).
Para calcular la probabilidad que el equipo local gane, debemos sumar el área roja oscura por el área azul oscura.
- Área roja oscura: \(0.05 * 0.24 = 0.012\)
- Área azul oscura: \(0.46 * 0.95 = 0.437\)
La suma de ambas áreas es lo que se llama probabilidad total. En este ejemplo la probabilidad que el equipo local gane es de un \(0.012 + 0.437 = 0.449\).
La ley de la probabilidad total expresa la probabilidad de un evento como la suma de dos partes distintas:
\(P(A) = P(A \text{ y } B) + P(A \text{ y no } B).\)
Vamos a resolver algunos ejercicios que involucran la probabilidad total para familiarizarse un poco más.
Ejercicio 1: Una empresa ordena suministros a dos proveedores: 30% del Proveedor A y 70% del Proveedor B. Entre los suministros del Proveedor A, el 1% son defectuosos, mientras que entre los suministros del Proveedor B, el 2% son defectuosos. ¿Cuál es la probabilidad de que un artículo elegido al azar sea defectuoso?
Para calcular la probabilidad de que un artículo seleccionado al azar sea defectuoso, primero necesitamos calcular la probabilidad ponderada de que un artículo seleccionado al azar sea defectuoso desde cada proveedor y luego sumar estas probabilidades ponderadas.
Para el Proveedor A, la probabilidad de que un artículo seleccionado al azar sea defectuoso es del 1% (0.01), y dado que el 30% de los suministros provienen del Proveedor A, la probabilidad ponderada de que un artículo seleccionado al azar sea defectuoso del Proveedor A es:
\(0.30×0.01=0.003\)
Para el Proveedor B, la probabilidad de que un artículo seleccionado al azar sea defectuoso es del 2% (0.02), y dado que el 70% de los suministros provienen del Proveedor B, la probabilidad ponderada de que un artículo seleccionado al azar sea defectuoso del Proveedor B es:
\(0.70×0.02=0.014\)
Luego, sumamos estas probabilidades ponderadas:
\(0.003+0.014=0.017\)
Entonces, la probabilidad de que un artículo seleccionado al azar sea defectuoso es del 1.7%.
Ejercicio 2: En una escuela de idiomas, a los nuevos estudiantes de inglés se les asigna aleatoriamente a uno de tres profesores: 20% al profesor A, 40% al profesor B y 40% al profesor C. Entre los estudiantes del profesor A, el 90% pasa el examen de idiomas, al igual que el 70% de los estudiantes del profesor B y el 60% de los estudiantes del profesor C. ¿Qué probabilidades tiene un nuevo alumno elegido al azar de aprobar el examen?
Este ejercicio sigue la misma lógica del ejercicio anterior, donde debemos calcular la probabilidad ponderada de que un estudiante seleccionado al azar pase el examen para cada profesor y luego sumar estas probabilidades ponderadas.
La respuesta por tanto es
\(0.90⋅0.20+0.70⋅0.40+0.60⋅0.40 = 0.7\)
Actualización de probabilidades
El capitán y el jardinero
El equipo de fútbol londinense Fulham se prepara para la próxima temporada de la Premier League inglesa. ¿Cuál será su rendimiento este año?
Según los resultados del año pasado, la probabilidad de que Fulham gane el primer partido es de 0.39. Antes del primer partido de este año, el capitán del equipo predice una victoria.
¿Qué ocurre con el 0.39 después de la Victoria predicha del capitán?
Aumentará si podemos confiar en las predicciones del capitán y eso dependerá de su historial de predicciones. Cuanto más podamos confiar en la nueva información (la Victoria predicha del capitán), más podremos aumentar nuestra estimación de la probabilidad de que Fulham gane el partido.
El capitán presume que la temporada pasada, cada vez que el Fulham ganó, él predijo una victoria. Resulta que en la temporada anterior, el capitán había pronosticado una victoria del Fulham en todos los partidos. Así que no sólo
\(P(\text{Victoria Predicha} | \text{Victoria}) = 1.00\)
Si no que también
\(P(\text{Victoria Predicha}) = 1.00\)
Dado que el capitán no tiene más probabilidades de predecir una victoria cuando su equipo gana, su Victoria predicha es inútil y deberíamos ignorarla.
El jardinero del terreno del Fulham también ha estado haciendo predicciones. En la última temporada, predijo correctamente el 40% de las victorias y una victoria en el 20% de todos los partidos.
\(P(\text{Victoria Predicha} | \text{Victoria}) = 0.4\)
\(P(\text{Victoria Predicha}) = 0.2\)
Esto quiere decir que de todas las predicciones que hizo el jardinero, el 20% de ellas apostó a que Fullham ganaba el partido y el 40% de esas apuestas, Fullham ganó. Como la victoria del equipo es de 0.39% y la Victoria predicha de victoria del jardinero es de 40% cuando predice que el equipo gana, las probabilidades de victoria de Fullham son mayores con esta Victoria predicha (o nueva información).
Geometria de predicciones
Ahora calcularemos como va cambiando la probabilidad que un equipo gane cuando tenemos nuevas predicciones que aseguran su victoria. Tomemos esto como nueva información para poder predecir sucesos aleatorios.
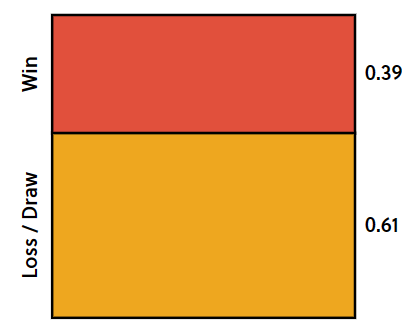
La cuadrícula muestra la probabilidad que Fulham gane el partido antes de que se haya realizado algún pronóstico. El área total de esta cuadrícula es 1 y la división muestra la probabilidad de que el equipo gane o pierda.
A modo de ejemplo, si queremos calcular la probabilidad que el equipo gane, debemos sumar el área roja y dividirla por la suma entre el área roja y la naranja.
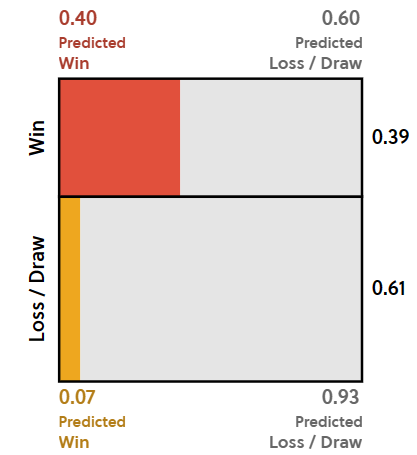
ESta cuadrícula representa las probabilidades del jardinero cuando predice una victoria. Vemos que ambas áreas se achican, pero la naranja, al comprimirse más que la roja, el ratio \(\frac{roja}{\text roja + naranja}\) aumenta, vale decir, aumenta la probabilidad de victoria de Fullham con la Victoria predicha de victoria del jardinero. Ahora, si queremos saber el valor del nuevo ratio, debemos calcular las nuevas áreas. El área roja disminuyo un 60%, siendo su nueva área \(0.39 * 0.4 = 0.156\). El área naranja tiene una nueva área que corresponde a \(0.07 * 0.61 = 0.0427\). Sumando ambos resultados, nos da que la nueva área total del rojo y del naranjo es de \(0.156 + 0.0427 = 0.1987\).
Calculando entonces el valor del nuevo ratio, tenemos que \(\frac{0.156}{0.1987} = 0.785\) Ya habiendo calculado el nuevo ratio, sabemos que con la Victoria predicha del jardinero por una victoria del equipo, la probabilidad que Fullham gane pasa de 0.39 a 0.785.
Lo que acabamos de hacer sin darnos cuenta es utilizar un famoso teorema en probabilidades llamado Teorema de Bayes, cuya formula esta dada por:
\(P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)}\)
Para ver como llegamos a eso, primero recordemos que la probabilidad de P(A|B) significa ¿cuál es la probabilidad de A si pasa B? En este caso nos preguntamos cuál es la probabilidad de que gane Fullham SI el jardinero predice una victoria. La probabilidad P(B|A) es al revés: ¿cuál es la probabilidad que el jardinero haya predecido una victoria SI gana Fullham?
P(A) sería entonces la probabilidad que gane el equipo y P(B) la probabilidad que el jardinero apueste por una victoria. Entonces tenemos:
\(P(\text{Victoria|Victoria predicha}) = \frac{P(\text{Victoria predicha|Victoria}) \cdot P(\text{Victoria})}{P(\text{Victoria predicha})}\) \(P(\text{Victoria|Victoria predicha}) = \frac{0.4 * 0.39}{0.1987} = 0.785\)
Llegamos al mismo resultado de antes, pero en vez de apoyarnos por la geometria de las probabilidades, nos apoyamos en la formula del teorema de bayes. Ahora, vamos a ver un par de ejemplos de uso para entender más en qué situaciones utilizar el teorema de Bayes.
Ejercicio 1: Este mes, el 35% de los pacientes de una clínica oftalmológica fueron niños y el 65% fueron adultos. Entre los niños, el 42% necesitaba anteojos, al igual que el 63% de los pacientes adultos. ¿Cuál es la probabilidad que un paciente que necesite anteojos sea un adulto?
En este ejercicio, la probabilidad que un adulto necesite anteojos es \(0.65 * 0.63 = 0.4095\), mientras que la probabilidad que un niño utilice anteojos es de un \(0.35 * 0.42 = 0.147\). Si queremos saber la probabilidad que un paciente que necesite anteojos sea un adulto debemos dividir 0.4095 en 0.4095 + 0.147. Esto da un resultado de 0.264.
Ejercicio 2: Un jugador de baloncesto está practicando lanzamientos. Para el primer lanzamiento tiene una probabilidad de que sea punto en el 63% de los casos y un 55% para el segundo lanzamiento. Si anota en el primer lanzamiento, anotará el segundo con una probabilidad del 75%. Si el jugador ha marcado el segundo lanzamiento, ¿cuál es la probabilidad de que también haya marcado el primero?
En este ejercicio debemos tener en consideración tres probabilidades distintas:
- \(P(\text{Segundo lanzamiento|Primer lanzamiento}) = 0.75\)
- \(P(\text{Primer lanzamiento}) = 0.63\)
- \(P(\text{Segundo lanzamiento}) = 0.55\)
En la pregunta nos están pidiendo \(P(\text{Primer lanzamiento|Segundo lanzamiento})\) por lo tanto tenemos que:
\(\frac{P(\text{Segundo lanzamiento|Primer lanzamiento}) \times P(\text{Primer lanzamiento})}{P(\text{Segundo lanzamiento})} = \frac{0.75}{0.55}x0.63\)
Lo que equivale a una probabilidad de 0.859.
Eventos dependientes e independientes
Eventos independientes
En agosto del 2023 ya estaba definido el cuadro de semifinales para el mundial de futbol femenino. Los partidos fueron:
- España vs Suecia
- Australia vs Inglaterra
Los fans australianos estaban muy orgullosos de su equipo cuando alcanzó las semifinales de la Copa Mundial Femenina. ¿Tendrían alguna posibilidad contra sus rivales?
Australia se enfrentó a Inglaterra en semifinales y, en caso de llegar a la final, se vería las caras con España o Suecia. Los analistas hicieron las siguientes predicciones:
- P(Australia vence a Inglaterra) = 0.43
- P(España vence a Suecia) = 0.6
Para calcular la probabilidad de que Australia y España se enfrenten en la final, multiplicamos las probabilidades de que Australia llegue a la final y España llegue a la final:
P(Australia en la final y españa en la final) = P(Australia en la final) * P(España en la final)
Como podemos suponer, el resultado de los dos equipos semifinalistas no dependen entre sí. El resultado del partido de España con Suecia no influye en el resultado del partido entre Australia e Inglaterra y viceversa.
Dos eventos A y B son independientes cuando
P(A y B) = P(A) * P(B)
Eventos dependientes
Por supuesto, el objetivo final de Australia no era llegar a la final, sino ganar el Mundial. ¿Qué posibilidades tenían de ganar?
Podemos expresar la probabilidad de que Australia gane la copa del mundo con la siguiente expresión:
P(Australia gana la final y Australia gana la semifinal)
Para que Australia gane la final primero debe ganar la semifinal, por tanto, ambos eventos son dependientes entre sí, por que para que pase uno debe pasar primero el otro. La formula para expresar cuando dos eventos son dependientes es la siguiente:
P(A y B) = P(A|B) * P(B)
Por lo tanto, para hallar la probabilidad de que Australia gane la Copa del Mundo, tenemos que calcular
P(Australia gana la final y Australia gana la semifinal)
P(Australia gana la final|Australia gana la semifinal) * P(Australia gana la semifinal)
Para calcular esto primero debemos de considerar todos los eventos posibles. Australia primero debe ganarle a Inglaterra, eso si o si. Luego, en la final, pueden ocurrir dos escenarios:
- España le gana a Suecia y por tanto Australia le debe ganar a España.
- Suecia le gana a España y por tanto Australia le debe ganar a Suecia.
En el escenario 1, los analistas estiman que la probabilidad que España le gane a Suecia es de un 0.6 y que Australia le gane a España es de un 0.37. Por otro lado, se estima que la probabilidad que Australia le gane a Inglaterra es de un 0.43. Por tanto, la probabilidad que el primer escenario ocurra es de un 0.6 * 0.37 * 0.43 = 0.09546.
En el escenario 2, los analistas estiman que la probabilidad que Suecia le gane a España es de un 0.4 y que Australia le gane a Suecia es de un 0.48. Por lo tanto, la probabilidad que el segundo escenario ocurra es de 0.4 * 0.48 * 0.43 = 0.08256
Sumando las probabilidades del escenario 1 con el escenario 2 nos dará la respuesta final de la probabilidad de Australia ganando la copa del mundo. Esta probabilidad es 0.09546 + 0.08256 = 0.17802
Predecir con probabilidades
Lidiar con la incertidumbre
El futuro es incierto, pero los datos pueden ayudarnos a anticipar lo que está por venir.
Aquí presentamos las ideas clave que están en el centro de las predicciones basadas en datos.
Domando lo impredecible
El 16 de abril de 2021, el vuelo 665 de American Airlines despegó de Dallas Ft. Worth, con destino a Charlotte. Una hora más tarde, se vio obligado a regresar.
¿Qué crees que causó la emergencia? ¡El vuelo 665 tuvo que regresar porque un rayo averió uno de sus motores y desactivó su radar meteorológico!
Sin embargo, los rayos no son necesariamente peligrosos. De hecho, un avión puede ser alcanzado y seguir adelante, como se muestra en estas imágenes.

En el año 2022, un rayo alcanzo a un total de 13 aviones. Esto es bajísimo pensando en que ese año hubieron 28 millones de vuelos. Esto nos da una probabilidad que nos caiga un rayo de 0.0000005%. Tan pocos vuelos en 2022 se vieron seriamente afectados por rayos que probablemente no tienes nada de qué preocuparte.
El uso de datos para inferir el futuro de esta manera se basa en una gran suposición:
El futuro se comportará como el pasado.
En el siguiente gráfico se muestran los rayos que cayeron sobre aviones desde el 2010.
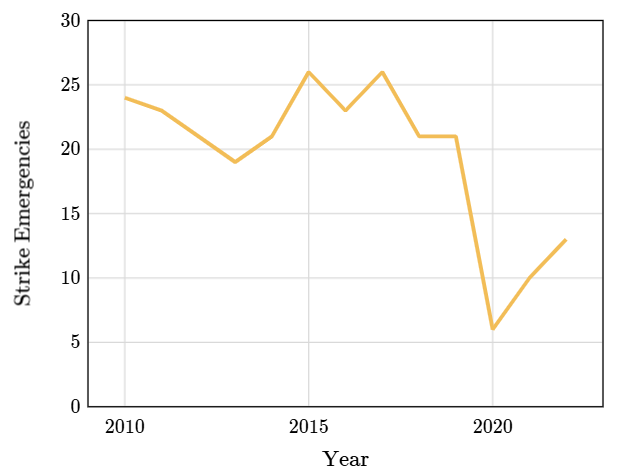
Este gráfico no muestra consistencia con el pasado, dado que hay una baja abrupta el año 2020. Si el futuro se comporta como el pasado, eso no habría sucedido. Entonces, ¿nos equivocamos al pensar que nuestro próximo vuelo probablemente esté a salvo de los rayos?
Miremos otro gráfico, el número de vuelos en millones desde el 2010.
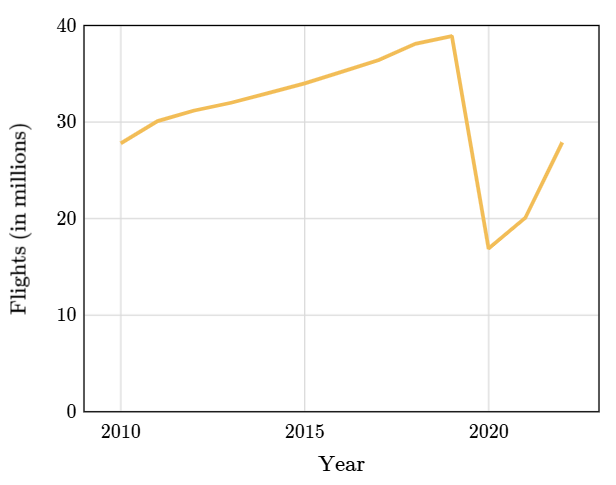
Los vuelos durante el 2020 bajaron abruptamente debido al COVID-19. A medida que disminuyeron los vuelos totales, también lo hicieron las situaciones de caída de rayos.
De hecho, los porcentajes son consistentemente pequeños a lo largo de los años, por lo que parece seguro asumir que seguirán siendo pequeños en el futuro previsible.
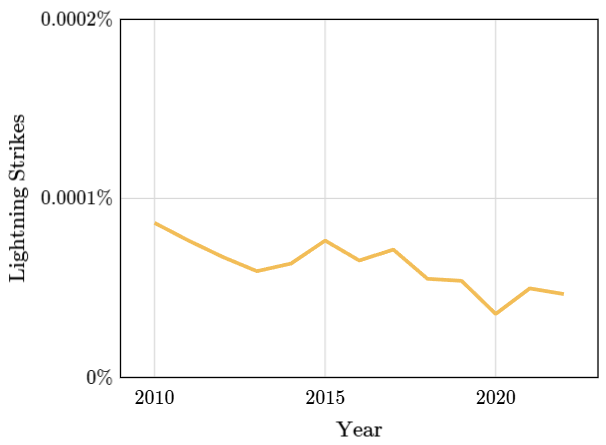
Lo importante entonces para el análisis es tomar porcentajes y saber el contexto de porque bajaron tanto los impactos de rayo. Un contexto mal definido nos puede llevar a malas conclusiones.
Existen más problemas que pueden surgir durante el vuelo además de los rayos. Por ejemplo, podemos tener colisiones, problemas de seguridad, medicos o mecánicos. Este último es el problema más reportado en la base de datos de situaciones de vuelo durante el 2008, con 14.887 casos. Sin embargo, incluso la mayor situación de peligro tiene muy poca frecuencia si lo comparamos con los millones de vuelo por año, por tanto, hay baja probabilidad que esto ocurra.
Estos problemas, por tanto, no deberían impedirnos de viajar. Cuando estemos con miedo de viajar, pensemos en la bajisima probabilidad de que algún problema aparezca durante el vuelo.
Además de una fe renovada en la seguridad de volar, esto es lo que hay que llevarse…
El número de veces que un resultado aparece en nuestro conjunto de datos está directamente relacionado con la probabilidad de que se repita en el futuro.
Estos datos de vuelo podemos extraerlos en The Aviation Herald.
De los datos a las probabilidades
Recuento de registros
A todos nos ha pasado alguna vez: una loca carrera hacia el aeropuerto sólo para encontrarnos con que nuestro vuelo se retrasa o, peor aún, se cancela.
No siempre podemos evitar estas situaciones, pero podemos gestionar el riesgo si sabemos hacer buenas predicciones a partir de los datos.
| Vuelos de United de LAX a JFK | Conteo |
|---|---|
| Cancelados | 21 |
| Tarde | 282 |
| Temprano/A tiempo | 767 |
Esta tabla tiene 1070 registros correspondientes a los vuelos desde los aeropuertos LAX (Los Angeles) a JFK (Nueva York) de la empresa United Flights. Vemos que lo más común es que los vuelos partan a tiempo.
United parece una buena opción, pero antes de comprar ese ticket, veamos si podemos hacerlo mejor.
Funciones de masa de probabilidad (PMF)
Comparemos United Airlines con un fuerte competidor, Delta Air Lines.
| Evento | United | Delta |
|---|---|---|
| Cancelados | 21 | 74 |
| Tarde | 282 | 2931 |
| Temprano/A tiempo | 767 | 2239 |
| Total | 1070 | 5244 |
A pesar que Delta tiene más vuelos que son antes o a tiempo del horario predefinido, no significa que sea la mejor opción. Debemos fijarnos en la fracción o probabilidad que los aviones de que Delta y United partan a la hora o antes.
En el caso de Delta, la probabilidad que sus aviones partan a tiempo es de 43%, bastante menos que 72% que tiene United.
Recordemos que una probabilidad es el número de veces que aparece un suceso en un conjunto de datos dividido por el número total de registros.
Calculando las probabilidades de cada evento para United nos da como resultado la siguiente tabla:
| Probabilidad | Valores PMF |
|---|---|
| P(Cancelado) | 2% |
| P(Tarde) | 26% |
| P(Temprano/A tiempo) | 72% |
Esta lista de probabilidades es la función de masa de probabilidad, o PMF por sus siglas en inglés.
Teniendo ahora las PMF de las dos aerolineas nos resulta en la siguiente tabla:
| Probabilidad | United | Delta |
|---|---|---|
| P(Cancelado) | 2% | 1% |
| P(Temprano/A tiempo) | 72% | 43% |
| P(Tarde) | 26% | 56% |
Nota: Estos datos fueron extraidos en el departamento de Estadísticas Estadounidense Pero, ¿por qué hay tanta distancia entre estas dos compañías aéreas? ¿Podríamos estar pasando por alto algo vital?
Visualizar probabilidades
Graficar una función de masa de probabilidad (PMF) es mucho más útil que verla como una lista de números.
Para realizar un gráfico de esta naturaleza debemos dividir la cantidad de casos en que un evento particular suceda por el número total de cosas para así obtener la probabilidad. Este proceso se llama normalización.
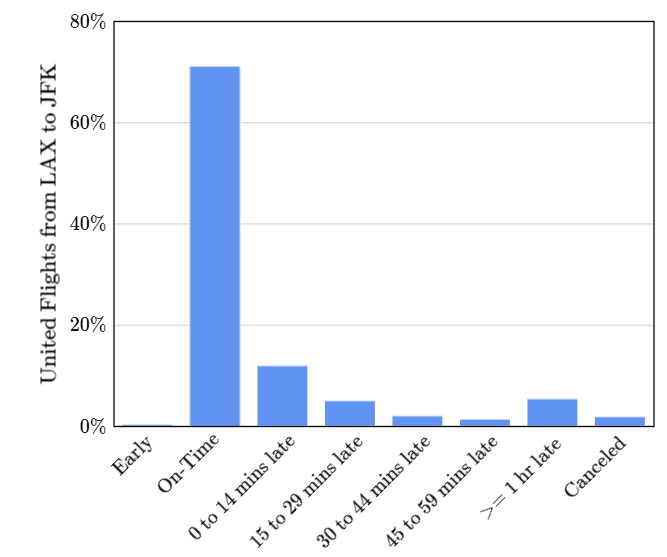
Los datos desplegados de esta manera son mucho más faciles de leer e interpretarlos para responder preguntas clave. Sin embargo, el verdadero potencial de una visluación de PMF es cuando lo comparamos con otros gráficos de la misma índole.
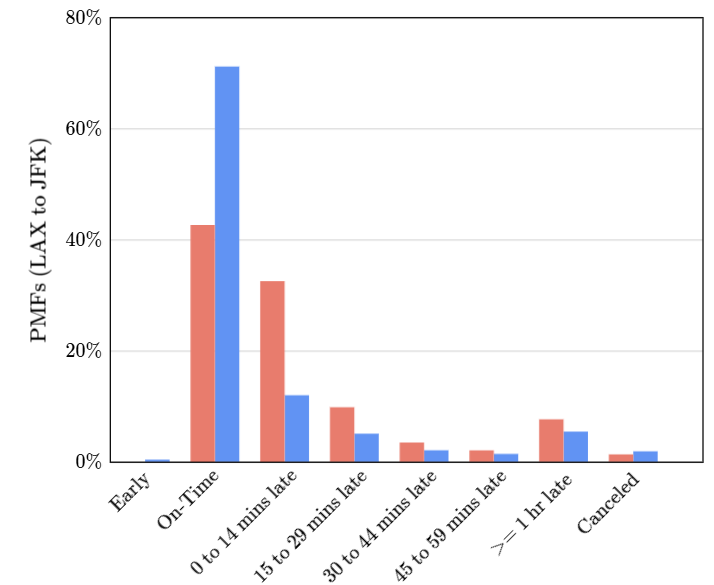
El gráfico azul corresponde a United y el rojo a Delta. Estos datos son solo los aviones que parten de LAX a JFK, por tanto no nos da un panorama general de ambas compañias para que nosotros podamos elegir con cuál quedarnos.
El siguiente gráfico muestra toda la data de todos los vuelos de United y Delta, no solo desde LAX a JFK.
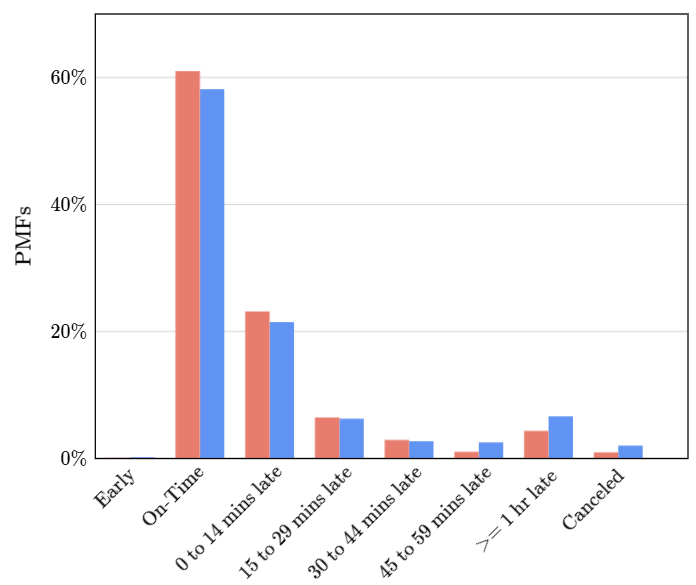
Todos los pares de barras tienen aproximadamente la misma altura, por lo que no hay mucha diferencia entre las dos aerolíneas.
Todos los vuelos corren algún riesgo de retraso o cancelación, pero ahora disponemos de herramientas que nos ayudan a comprender este riesgo.
Probabilidades con condiciones
Las probabilidades nos ayudan a navegar por un futuro incierto, pero no están escritas en piedra. Cuando cambian nuestros conocimientos sobre una situación, también tienen que cambiar la probabilidad de ocurriencia.
Por ejemplo, tomando los datos de despegue de aviones en Estados Unidos, la probabilidad que nos cancelen un vuelo es del 2%. Ahora, imaginemos que está nevando. ¿Crees la probabilidad de cancelación de vuelos se mantenga inamovible? La verdad que es no. De hecho, los días que está nevando la probabilidad de cancelación de un vuelo se dispara a más del 10%.
Cuando nos enteramos de algo nuevo, como el tiempo a la hora de salida, filtramos los datos para adaptarlos a las nuevas condiciones. Después, utilizamos la misma receta de siempre para obtener las probabilidades actualizadas: dividimos los recuentos por la longitud del conjunto de datos filtrados.
Para poder calcular la nueva probabilidad de que un vuelo sea cancelado cuando está nevando, debemos de realizar los siguientes pasos:
- En nuestra base de datos filtramos por un clima nevoso y vuelos cancelados. Esto nos da un total de 37 casos.
- Luego, filtramos solo por los días nevosos existentes. Esto nos da 294 casos.
- El resultado es la división entre los 37 y los 294 casos. Esto nos da una probabilidad de 0.12585 de que el vuelo sea cancelado.
Todas estas preguntas clave las podemos responder con probabilidades condicionadas. Antes vimos la formula, pero ahora detallo como poder extraer las probabilidades con tan solo filtrar los datos de la base de datos.
Sin embargo, que nieva no es la condición atmosférica que afecta la cancelación de vuelos, si no que los fuertes vientos con un 15% de probabilidad de cancelación, dado que los vientos fuertes pueden desviar un avión de su trayectoria de vuelo o poner en peligro al personal de tierra.
Hay otros eventos meteorológicos, como la niebla, que con la tecnología y equipo de navegación sorprendentemente no afecta en demasia a los vuelos cancelados, ni mucho menos a los vuelos que parten a tiempo o antes.
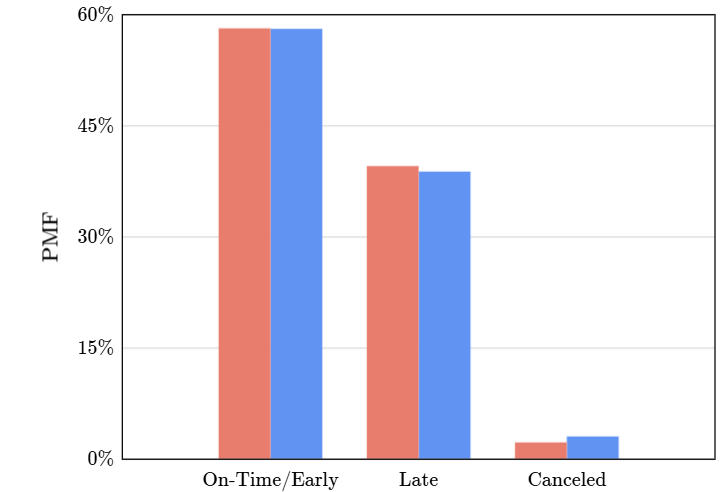
Las barreras rojas son todas los casos existentes, mientras que la azul son los casos que hay niebla. En este caso, no hay variaciones o dicho de otro modo, un vuelo que despega a tiempo es independiente de la niebla.
Un suceso ocurre independientemente de una condición si
\(P(evento|condición) = p(evento)\)
En resumen, diferentes condiciones pueden hacer que un acontecimiento sea más o menos probable o que no tenga ningún impacto.
Pero en todos los ejemplos que hemos visto, hemos dado por sentadas las condiciones. ¿Y si también son inciertas? A continuación veremos cómo resolverlo.
Probabilidades conjuntas
Sabemos cómo manejar un solo evento, pero ¿cuál es la probabilidad de que dos eventos sucedan juntos?
La respuesta nos lleva a una poderosa herramienta para actualizar probabilidades. La probabilidad conjunta P(A y B) mide la probabilidad de que dos eventos A y B ocurran juntos.
Por ejemplo, cuando queramos calcular la probabilidad de que al momento del despegue del avión no hayan precipitaciones y que vuele a tiempo son dos probabilidades conjuntas. Para su calculo debemos filtrar la base de datos con estas dos condiciones para que ambas se cumplan. Tenemos un 49% de posibilidades de que el buen tiempo llegue junto con un despegue a tiempo. A esto lo llamamos probabilidad conjunta.
Eso no quiere decir que si vamos al aeropuerto y vemos que hace buen tiempo, tenemos una probabilidad de 49% de que el avión parta a tiempo. La diferencia radica en que en ese 49% no estamos asumiendo ninguna probabilidad como certera, mientras que en el segundo caso, sabemos que el tiempo es bueno y por tanto ese evento es certero.
P(A tiempo|Buen tiempo) ≠ P(A tiempo y Buen tiempo)
De hecho, las probabilidades de cada evento son las siguientes:
- P(Buen tiempo) = 82%
- P(A tiempo y Buen tiempo) = 49%
- P(A tiempo|Buen tiempo) = 59%
Aunque no lo creas, estas probabilidades están relacionadas entre sí. Si nosotros multiplicamos el 82% por el 59% el resultado será 49%, por tanto:
P(A y B) = P(A|B) * P(B)
donde A es que el avión parta a tiempo y B es que haya un buen tiempo. Las probabilidades conjuntas y condicionales están conectadas por esa formula.
La ley de la probabilidad total
Cuando llegamos a la puerta de embarque, el agente nos da una mala noticia: un miembro de la tripulación aún no ha llegado y nadie sabe dónde está.
Si no aparece pronto, el vuelo se retrasará hasta que se encuentre un sustituto. Démosle al miembro de la tripulación un 50% de probabilidad de no presentarse. ¿Cuál es la probabilidad de que el miembro de la tripulación no se presente y haya un retraso en el vuelo?
\[ \mathbb{P}\text{(Atraso} \textbf{ y } \text{No aparece)} = 50\%\] Esto no quiere decir necesariamente que tenemos una probabilidad del 50% que el avión parta a tiempo. En realidad, el miembro de la tripulación puede presentarse antes de la salida, pero algo más podría causar un retraso. Necesitamos tener esto en cuenta.
Vamos a suponer que, incluso si se presentan, tenemos aproximadamente un 40% de probabilidad de un retraso.
Con esto ya podremos saber cuál es la probabilidad de que el avión parta a tiempo, dado que tenemos que calcular el P(Atraso y Si Aparece), o en otras palabras, P(Atraso|Si Aparece) * P(Si Aparece). Esto es lo mismo que 40% * 50% = 20%.
Hasta hora tenemos dos posibilidades:
- P(Atraso|No aparece) = 50%
- P(Atraso|Aparece) = 20%
Si nos fijamos bien, vemos que en ambas posibilidades tenemos dos probabilidades opuestas: si aparece el personal o si no aparece. Estas dos probabilidades en conjunto tienen un 100% de probabilidades de ocurrir, dado que no hay más eventos posibles: o aparece el personal o no aparece. Con esto en mente, podemos simplemente sumar ambas posibilidades para que nos de la probabilidad de que haya un atraso. Por tanto:
P(Atraso) = P(Atraso|No aparece) + P(Atraso|Aparece) = 70%
Los datos nos indican que tenemos un 40% de probabilidad de retraso en el vuelo, pero las noticias sobre el miembro de la tripulación desaparecido lo elevan al 70%.
Generalmente, cuando el evento A depende de si ocurre o no el evento B, P(A) es una combinación de P(A|B) y P(A|no B).
\(P(A)=P(A∣B)⋅P(B)+P(A∣no B)⋅P(no B)\)
Esta Ley de la Probabilidad Total nos permite actualizar nuestras probabilidades cuando el filtrado de datos no es una opción.
Teorema de Bayes
La Regla de Bayes actualiza las probabilidades existentes con nueva información, convirtiéndola en una herramienta indispensable para cualquier aspirante a analista de datos.
Estamos en invierno y necesitamos escapar del clima frío y sombrío de diciembre, así que reservemos un vuelo a la soleada Miami. Sería genial poder tomar el sol nada más aterrizar.
Según datos de diciembre del 2018 al 2021 durante diciembre, la probabilidad de que no llueva en Miami es de 67%. Un 67% de posibilidades no está mal, pero unos días antes del vuelo, consultamos el tiempo de tres días y vemos que los meteorólogos anuncian lluvia ¿Qué opinas de nuestra probabilidad de sol ahora?
Si los meteorólogos profesionales creen que va a llover, es lógico que baje la probabilidad de sol. Sin embargo, para estar seguro debemos de tener la data.
La data real acerca del clima de diciembre del 2021 y la predicción de los meteorologos nos puede decir que tan equivocadas han sido las predicciones.
Los datos nos dicen que la cantidad de días sin lluvia durante diciembre del 2021 son de 24 días y tan solo hay 2 casos en que los meteórologos pronosticaron lluvia y no hubo. Esto quiere decir que:
\(P(\text{Predicción de lluvia} ∣ \text{No llueve})= \frac{2}{24}\)
A nosotros lo que nos interesa es saber la probabilidad de que podamos evitar la lluvia en Miami siendo que el meteórologo nos anuncio lluvia. Esto es
\(P(\text{No llueve} ∣ \text{Predicción de lluvia}) = ??\)
Para responder a esta pregunta necesitamos utilizar la regla de Bayes.
\[ P(A \mid B) = \frac{P(B \mid A) \cdot P(A)}{P(B)} \]
Esta es la herramienta definitiva para actualizar las probabilidades a la luz de nuevas pruebas.
Para calcular ahoa la probabilidad de que podamos ecitar la lluvia en Miami siendoq ue el meteórologo anuncio lluvia, necesitamos tres probabilidades: 1. \(P(\text{Predicción de lluvia} ∣ \text{No llueve})\) 2. \(P(\text{Predicción de lluvia})\) 3. \(P(\text{No llueve})\) La primera ya sabemos que es 2/31
Viendo los datos, vemos que la probabilidad de predecir lluvia es 3/31, mientras que la probabilidad que no llueva es 125/186.
Con esos datos, ya podemos calcular la probabilidad que estamos buscando.
\(P(A|B) = \frac{\frac{2}{24}*\frac{125}{186}}{3/31}\)
Comenzamos con un 67% de probabilidad de sol. Pero la Regla de Bayes y el pronóstico del tiempo ahora sitúan la probabilidad en un 58%.
Quizás no deberíamos sacar la ropa de playa todavía.
NOTA: Podemos extraer los datos en NOAA
Acumular probabilidades
PMF no son las únicas herramientas que podemos utilizar para comprender las situaciones aleatorias. Aquí presentamos una nueva con algunas ventajas clave sobre el PMF.
Es la peor pesadilla de todo viajero: un aeropuerto lleno a rebosar de multitudes enfurecidas, varadas por largos retrasos y cancelaciones.
Como vimos, muchas cancelaciones se pueden deber a las condiciones climáticas. En Nueva York es normal ver días nevando en febrero y dias así aumentan considerablemente la probabilidad de vuelos cancelados.
Según datos acerca de los vuelos del aeropuerto JFK en Nueva York en febrero, tenemos la siguiente PMF para los vuelos cancelados:
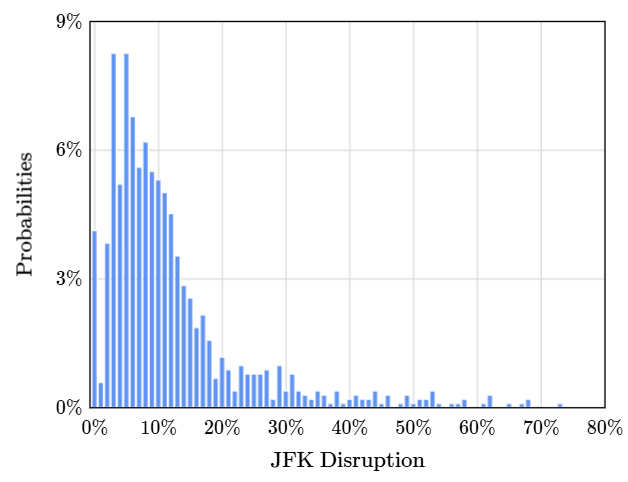
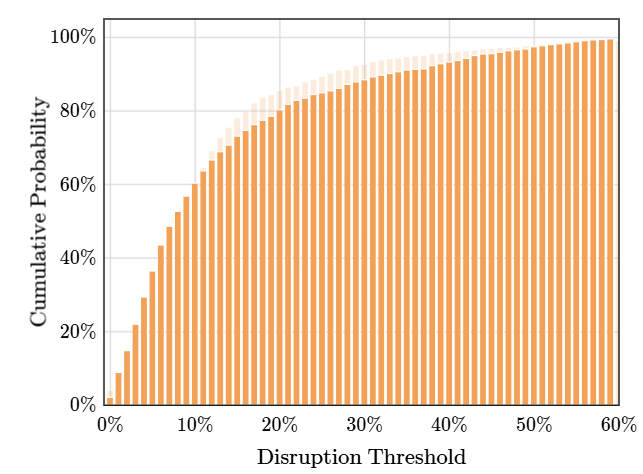
Este gráfico refleja la probabilidad que un vuelo sea cancelado en febrero. Sin embargo, si queremos calcular la probabilidad que nuestro vuelo tenga un 24% o menos de posibilidades de ser cancelado, debemos sumar la altura de todas las barras de la PMF desde el 0% al 24%. Para esa labor el PMF no nos serviría de mucho.
La Función de distribución acumulativa (CMF por sus siglas en inglés) es una gráfica que va sumando o acumulando las probabilidades pasadas. Por tanto es la herramienta perfecta si nos estamos preguntando la probabilidad que un valor sea menor o igual a cierto punto en la PMF o en otras palabras, \(P(X \leq x)\). Con esta herramienta, podemos saber que si vamos al aeropuerto de JFK en febrero, la probabilidad de que tengamos un 24% o menos de vuelos cancelados es de un 89%.
Si nosotros nos ponemos más exigentes con la experiencia de vuelo y queremos calcular la probabilidad de que los vuelos tengan una tasa de cancelación del 15% o menos, ¿el 89% que tenemos subirá o bajará con este nuevo umbral?
Cuando disminuimos nuestro valor de x, tenemos menos barras que contar en la PMF y por tanto la posibilidad de encontrar un 15% o menos de vuelos cancelados disminuye. Entre más bajo sea el umbral, más baja será la probabilidad acumulativa y viceversa. Esto es porque la CMF comienza en 0% y termina en 100%.
Comparación de distribuciones
Otra ventaja que tiene la CMF sobre la PMF es que esta última es mucho más tosca y ruidosa que la primera. Si comparamos dos aeropuertos para saber cuál tiene un porcentaje mayor de vuelos cancelados, es mucho mejor y más claro analizar la comparación desde la CMF que la PMF. No olvidemos ese detalle, porque de lo contrario sería muy dificil analizar gráficos con la PMF cuando comparamos información y podríamos llegar a conclusiones erroneas.
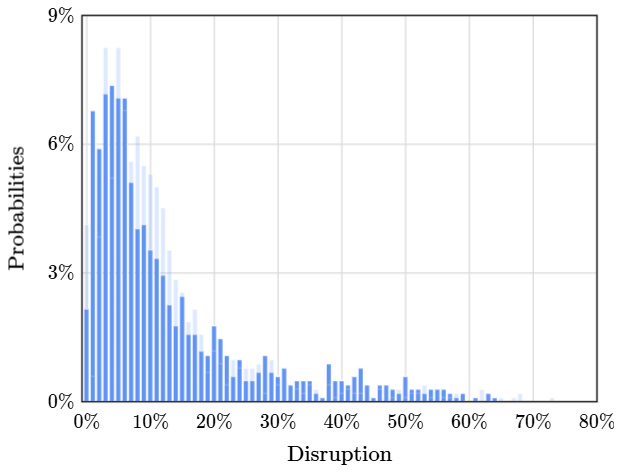
En la imagen anterior vemos un ejemplo, donde comparamos dos aeropuertos de Nueva York: La Guardia y JFK. La Guardia es el aeropuerto que no tiene transparencia en su color, mientras que JFK si tiene transparencia. Vemos que la CMF es mucho más suave que la PMF y esto es porque los saltos que hay entre las barras son mucho menores en la CMF que en la PMF. Esto se da porque la siguiente barra en la CMF o se mantiene o sube, no hay más direcciones posibles. En pocas palabras, el gráfico de la CMF parece suave porque el tamaño medio de los saltos es muy pequeño, mucho más pequeño que la PMF.
Creación de modelos de regresión
Correlación
Al cuantificar las relaciones entre mediciones, podemos utilizar una medición para predecir otra. Para demostrar este proceso, utilizaremos datos recogidos por investigadores de pingüinos.
¿Crees que puede existir una relación entre la longitud de las aletas de un pingüino y su peso?
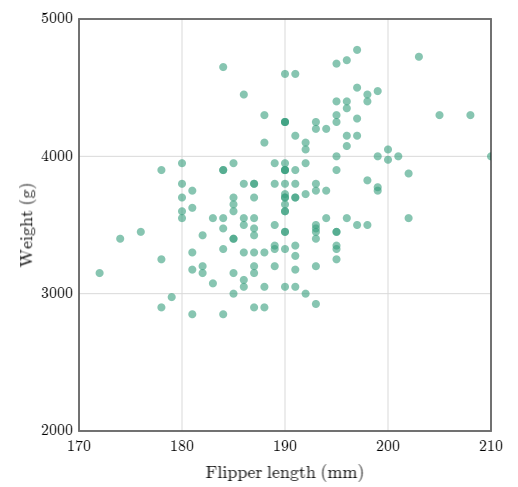
Como podemos ver en este diagrama de dispersión, en promedio, los pingüinos más pesados tienen las aletas más largas y los más ligeros, más cortas, lo que nos indica que existe una relación lineal entre estas dos medidas.
También podemos medir la profundidad del pico de un pingüino y relacionarla con su peso.
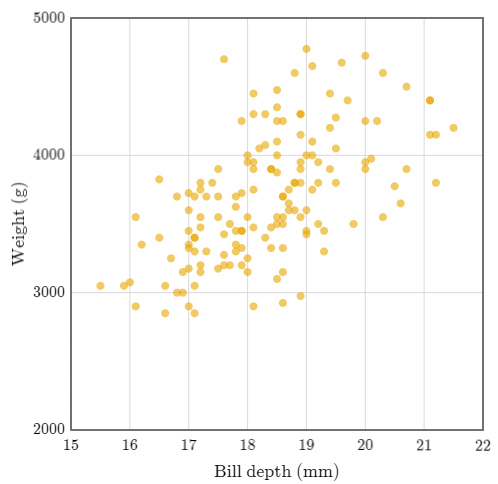
Entre estos dos gráficos, se ve que el pico del pinguino tiene más relación lineal que con la medida de las aletas y esto lo podemos notar en como sus puntos se dispersan: entre más dispersos estén los puntos, menos relacionados están y viceversa. Sin embargo, para estar seguros de cuál de estas medidas es mejor para predecir el peso de un pinguino, debemos de tomar una medida que nos ayude a cuantificar que tan relacionadas están dos variables linealmente. La correlación es una medida que justamente hace eso: cuantifica la fuerza de la relación lineal entre dos mediciones.
Entre más grande sea la correlación, más certera será la predicción de otra variable. Si la correlación es 1, la dispersión muestra una linea recta, dado que sus dos variables están relacionadas al 100%. Cuando la correlación es cero, significa que las variables no tienen absolutamenten ninguna relación lineal.
Tomando el ejemplo anterior, la longitud de las aletas de un pinguino tiene una correlación de 0.47 con su peso, mientras que la profundidad del pico del pinguino tiene una correlación de 0.58. Como el 0.58 es mayor que el 0.47, la profundidad del pico del pinguino está más relacionada con su peso que con la longitud de las aletas.
NOTA: Esta base de datos fue extraida desde el siguiente link
Las correlaciones que hemos visto hasta ahora son positivas. Esto quiere decir que si aumenta una variable, también aumenta la otra. La altura vs peso o el ingreso vs gasto son otras variables que también suelen tener relación positiva.
Las correlaciones negativas son aquellas que van en sentido opuesto. Cuando una variable sube, la otra tiende a bajar y viceversa. Ejemplos tipicos de esta relación podemos encontrar temperatura vs venta de abrigos, precio y demanda de un producto, horas de sueño y nivel de estrés o tasa de desempleo y crecimiento económico.
Cuando dos variables tienen una correlación perfecta positiva dijimos que el valor es 1. Cuando la correlación es negativa perfecta es -1, formando una linea recta con pendiente negativa. Esto quiere decir que entre más correlacionadas estén dos variables de manera negativa, más cerca estarán del -1. Sin embargo, este tipo de correlación perfecta rara vez se encuentra en el mundo real.
Por tanto, la correlación va desde los valores -1 a 1. Hay más correlación cuando los valores se aproximan a estos dos valores extremos, pero menos cuando se aproximan más al 0. Cuando la correlación no es igual a 0, podemos empezar a hacer predicciones matemáticas a partir de los datos. Para ello necesitaremos una nueva herramienta llamada regresión lineal.
Regresión Lineal Simple
Si no podemos pesar un pingüino, podríamos estimar su peso a partir de otras medidas?
El diagrama de dispersión nos sirve para ver qué tan relacionadas son dos variables distintas. También nos sirve para hacer predicciones sobre una variable respecto al valor de la otra.
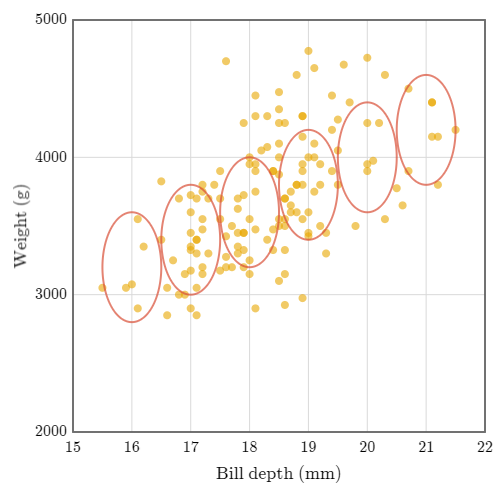
En esta imagen, vemos que a través de la profundidad del pico del pinguino podemos tener estimaciones de su peso. Estas estimaciones se encuentran encerradas en rojo por cada medida de profundidad en el eje X.
De estas estimaciones, podemos calcular un promedio para cada una y trazar una linea que conecte cada uno de estos promedios. Eso es a lo que llamamos una regresión lineal. Por ejemplo, si la profundidad del pico del pinguino es de 16mm, su peso se estima en unos 3200 gramos y si la profundidad es de 21mm se estima un peso de 42500 gramos. Con estos dos puntos, podemos trazar una linea para predecir los demás valores.
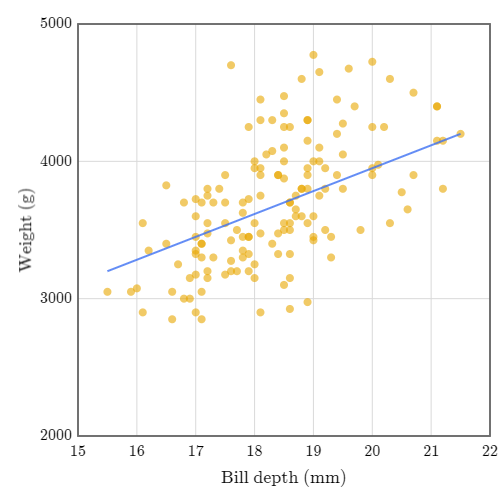
Esta línea representa «el peso en función de la profundidad» - para cada profundidad del pico del pingüino, podemos utilizar esta línea para calcular un peso estimado.
Ajustar una recta a los datos permite predecir valores mediante una función, que describe matemáticamente la relación entre dos variables. Es una forma sencilla y rápida de elegir una recta para ajustar los datos. La mayoría de lenguajes de programación y hojas de cálculo pueden calcularla automáticamente.
Como toda función lineal tenemos una formula para relacionar la variable dependiente de la independiente
\(y = mx + b\)
Donde m es la pendiente de la recta y b es el intercepto. El valor x es el valor de entrada e y es el valor que estamos estimando (valor de salida). Con esto en mente, podemos crear una función lineal para dos variables y con ello, hacer predicciones.
Consideremos que la pendiente significa en cuanto cambia una unidad de “y” si añadimos una unidad adicional de “x”. El intercepto es simplemente donde toca la curva en el Eje Y cuando el Eje X es cero.
Calcular errores
Si tomamos un nuevo pinguino donde la profundidad de su pico es de 17mm, podremos saber que su peso es de 3500 gramos, aproximadamente. A continuación, cuando pesamos el pingüino nos damos cuenta que su peso en realidad es de 2992 gramos. Esto es 508 gramos más abajo de lo que habiamos estimado.
Como todo modelo, la regresión lineal no es perfecta. Esta tendrá errores de estimación, en especial si la correlación no es tan alta. Estos errores del modelo se pueden cuantificar para saber a ciencia cierta qué tan bien nuestro modelo predice los datos.
Error cuadrático medio
El error cuadrático medio o MSE por sus siglas en inglés es una medida que mide el error de un modelo de regresión lineal. Este se calcula a partir de la diferencia de los puntos con la línea de la regresión lineal.
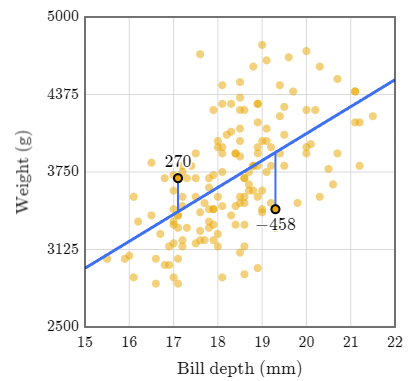
El problema con calcular estos errores de distancia es que si tengo un punto sobre la linea y un punto bajo la linea, estos al promediarlos, resultará en un número bajo cercano al cero y esto no representa el error que existe en el modelo. Para solucionarlo, podemos elevar al cuadrado todas las diferencias numéricas entre el punto y la línea para que siempre nos resulte en valores positivos.
El MSE es el promedio de todas las diferencias entre los puntos y la línea de regresión elevadas al cuadrado.
Tenemos que tener en cuenta que las líneas de regresión se crean con el principio de minimizar el MSE, por lo tanto, cuando veamos una línea de regresión entre dos variables, debemos saber que entre dos variables ya tenemos el mínimo MSE que podemos obtener. Dado que la recta de regresión minimiza los errores al cuadrado, la regresión lineal también se le denomina los mínimos cuadrados.
R Cuadrado
Supongamos que tenemos que hacer la misma estimación de peso para cada pinguino, es decir, estimar un peso fijo para todos los pinguinos.
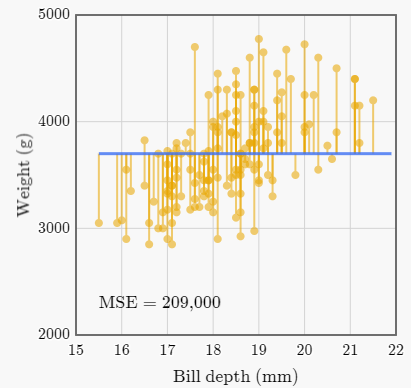
El valor que minimiza el MSE cuando predecimos el mismo peso para todos los pinguinos es de 209.000. La mejor estimación resulta ser el peso medio de todos los pingüinos, que se aproxima a 3.700 gramos. Si siempre adivinamos el peso medio, el error cuadrático medio (MSE) es de alrededor de 209.000. Sin embargo, si usamos la línea de regresión, el MSE es de alrededor de 140.000.
Usar la regresión redujo el error cuadrático medio (MSE) en aproximadamente un 33%. Esta reducción en el MSE se llama \(R^2\) y se expresa como un decimal, como 0,33. También podemos afirmar que la línea de mejor ajuste sólo explica el 33% de la variación de los datos.
\(R^2\), expresado como un decimal, es la reducción en el error cuadrático medio (MSE) entre la línea de promedio y la línea de regresión.
\(R^2\) no solo es la reducción en el error cuadrático medio (MSE), sino también el cuadrado de la correlación. La correlación entre el peso y la profundidad del pico es de 0,58. Al elevarlo al cuadrado, obtenemos 0,33, que es el valor de \(R^2\) que encontramos anteriormente.
Si tenemos medidas con correlación perfecta, podemos hacer suposiciones perfectas, lo que significa que podemos reducir el MSE en un 100%.
Error Medio Absoluto
El Error Medio Absoluto o MAE por sus siglas en inglés, también cuantifica el margen de error de un modelo de regresión lineal a través de las diferencias entre los puntos y la línea de regresión, pero en vez de elevar la diferencia al cuadrado para obtener un valor positivo, calcula su valor absoluto. El promedio del valor absoluta de todas estas diferencias es el MAE. Entre más bajo sea el valor de MAE, mejor el modelo.
El error absoluto es el valor absoluto del error, por lo que siempre es positivo. Como no elevamos el error al cuadrado, como hacemos con el MSE, el MAE no es tan sensible a los valores atípicos.
Podemos utilizar una línea de regresión basada en los datos actuales para hacer predicciones para el futuro y, a continuación, evaluar la precisión de las predicciones con el error medio absoluto (MAE).
Relaciones no lineales
La regresión lineal es una de las herramientas más útiles para cuantificar relaciones y hacer predicciones. Veamos qué ocurre cuando aplicamos las herramientas que hemos aprendido a las relaciones no lineales.
Aqui tenemos una relación ficticia entre dos variables: tamaño del pie y habilidad para el baile.

Si intentamos crear una linea de regresión para este diagrama de dispersión, la pendiente sería cercana a cero, siendo el intercepto cercana al promedio de los datos.
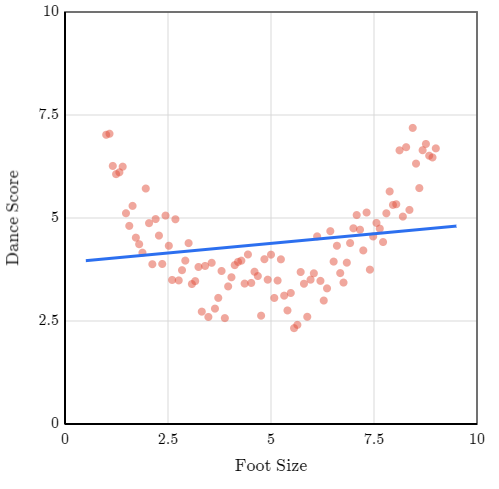
En este caso, el \(R^2\) es muy bajo (0.033), siendo que hay poca correlación lineal entre los datos, además que el intercepto está cerca de la media y la pendiente es cercana a cero, por lo que hay poca reducción del MSE entre el promedio y la regresión lineal. Utilizar la recta de regresión es casi lo mismo que adivinar la media cada vez. No reduce mucho el error cuadrático medio (MSE), por lo que \(R^2\) es cercano a cero.
Sin embargo, que tenga una correlación baja no significa que los datos no estén relacionados de algún modo. Recordemos que los la correlación mide la relación lineal entre los datos y en este caso, la relación claramente es cuadrática. En otras relaciones no lineales, la pendiente no siempre es 0, pero en general no es una buena representación de la relación.
Si la correlación es cercana a 0, podemos concluir que no existe una relación lineal, pero aún podría existir una relación no lineal. De todas formas, esta relación que no es lineal igual nos sirve para realizar predicciones. Como por ejemplo, saber aproximadamente el nivel de baile dada el tamaño de un pie.
La mejor forma posible de saber si la relación entre dos variables no es lineal es mirando el diagrama de dispersión. La correlación, \(R^2\) y la pendiente de la recta de regresión no nos dicen si existe una relación no lineal. Sólo pueden ayudarnos a concluir que no existe una relación lineal.
En vez de buscar la curva que mejor represente los datos, podríamos pensar en cambiar la escala de los ejes o uno de ellos a escala logarítmica para acercar los datos extremos a los datos promedio. Esto ayudará a que los datos tomen más una forma lineal. Transformando las variables podemos aplicar una regresión lineal incluso a relaciones no lineales.
Paradoja de Simpson
Un investigador está interesado en ver si existe una correlación entre la profundidad y la longitud del pico de los pingüinos.
Tras recoger mediciones de tres especies diferentes de pingüinos, elaboran este gráfico de dispersión y esta línea de regresión.
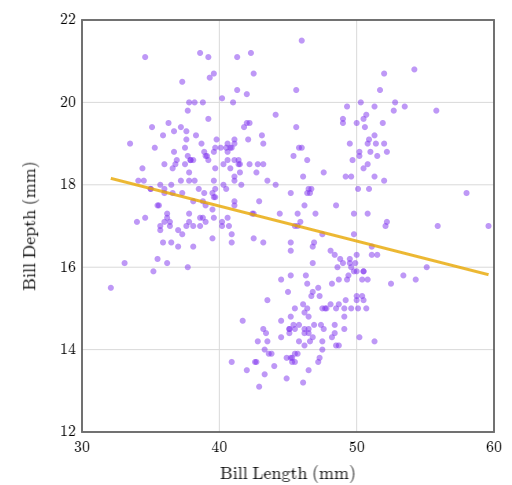
Sin embargo, su colega señala un problema con su método: han combinado datos de tres especies diferentes. Esto podría ser un problema, porque pueden haber diferentes tendencias dentro de las distintas especies de pingüinos.
Estos son los tres gráficos de dispersión de los pingüinos Adelia, Barbijo y Papúa.
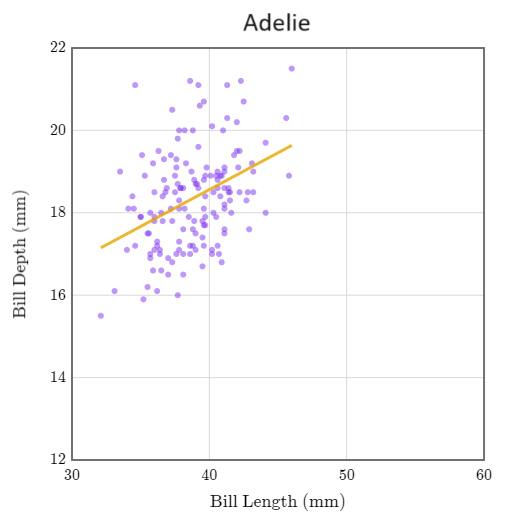
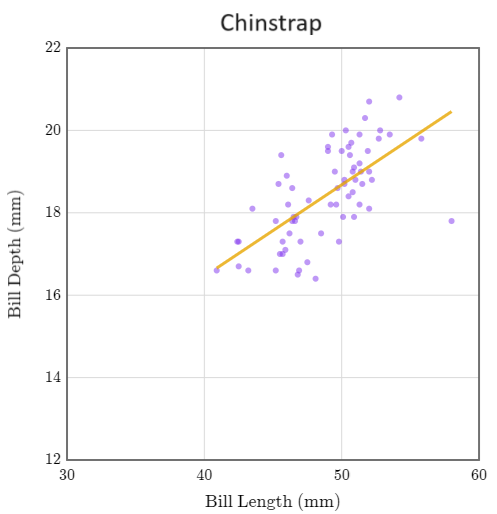
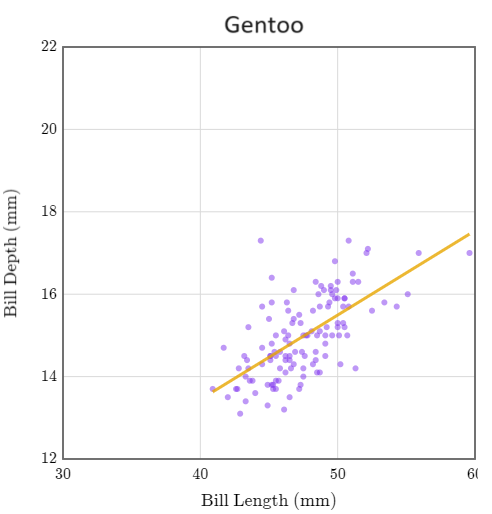
En los tres grupos, la pendiente es positiva. Pero cuando se juntaron, ¡la pendiente fue negativa! Este efecto se denomina paradoja de Simpson.
La paradoja de Simpson describe el efecto de combinar grupos de datos, provocando que las tendencias individuales de estos grupos posiblemente se inviertan o desaparezcan. En general, cuando combinamos grupos disímiles, la correlación y la regresión pueden inducir a error.
Modelización con múltiples variables
Precios de la vivienda
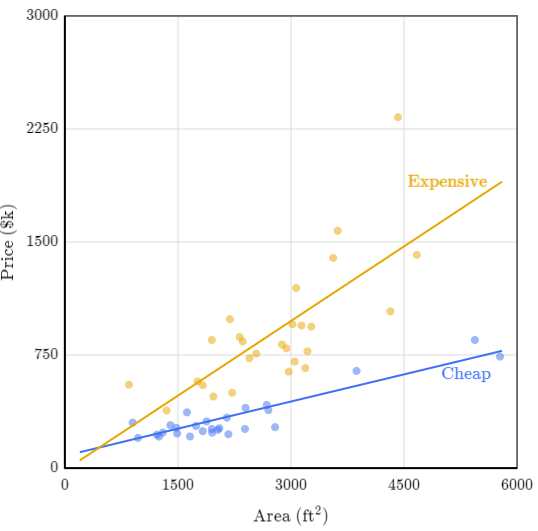
Comprar una casa es una decisión difícil. ¿Cómo saber si el precio es razonable? Si una casa vale USD 500000, ¿es caro o barato? Para saber si el precio de una casa es caro o barato siempre dependerá de varios factores, como la superficie, la ubicación, tipología, distribución, etc. Por supuesto que hay variables que afectan más el precio que otras, por ejemplo, la superficie es un factor que afecta muchísimo en el precio y asi también la ubicación.
Podemos realizar varias regresiones por cada variable que afecte el precio para saber que tanto inciden en el valor de la casa. En general, cuando la casa está en un barrio más caro, el precio tiende a subir más por cada metro cuadrado adicional, en comparación con los barrios más baratos. Hay otras conclusiones que podemos extraer de los datos y es interesante ver como estos van adectando el precio, que sería nuestra variable dependiente, mientras que los demás factores influyentes serian nuestras variables independientes. Las variables independientes (𝑥₁, 𝑥₂, …) se miden directamente para entender su impacto en la variable dependiente (𝑦).
La regresión lineal múltiple es una extensión de la regresión lineal simple que utiliza más de una variable independiente. Con la regresión lineal múltiple, podemos expresar las variables dependientes y en términos de las variables independientes x1, x2, … como
\(y = a_0 + a_1*x_1 + a_2*x_2 + …\)
Con la regresión lineal múltiple, podemos predecir un valor de una variable y explicar cómo influyen otras variables en ese valor. Por ejemplo, si tenemos dos valores independientes: la superficie y el barrio. Con una regresión lineal multiple, al tener varias variables independientes, podemos explicar el precio según como varien estas dos variables.
La mejor oferta
Para hacer una oferta ganadora por una casa es importante saber qué factores influyen en su precio y de qué manera.
Comencemos con una relación simple entre superficie y precio, donde la superficie es la variable independiente y el precio la dependiente. Según los datos extraidos por la venta de propiedades en King County, USA (2016) la mejor línea de regresión que minimiza el error es la siguiente:
\(y = -42 + 0.28x_1\)
Si estamos en un remate de una casa con 1200 \(ft^2\) una buena oferta según el modelo son 294000 dólares, pero este modelo no considera otros factores, como la vista.
Podríamos poner la calidad de vista como un número discreto del 0 al 4, donde 0 es que no hay vista y 4 una buena vista. En este caso, el modelo cambiaría al siguiente:
\(y = -15 + 0.26x_1 + 103x_2\)
Donde \(x_1\) es la superficie en pies cuadrados y \(x_2\) es la vista.
Cuando agregamos una nueva variable independiente, el intercepto y todos los coeficientes cambian para adaptarse a esta nueva variable. cambiando el modelo por completo. Sin embargo, con este nuevo modelo podemos responder preguntas claves, como ¿cuánto cambia la casa de precio si cambiamos la puntuación de la vista? Esta puede ser respondida poniendo la superficie de la casa como valor constante. Cuando la puntuación de vista, \(x_2\) aumenta en 1, el precio predicho aumenta en 103 si nada más ha cambiado.
Ojo que la vista la tenemos en una escala del 0 al 4, pero podriamos perfectamente tener la escala del 1 al 10. Cualquier cambio en los criterios de la evaluación de una variable cambia su coeficiente, pero no afecta a las demás variables. En consecuencia, un coeficiente mayor no significa necesariamente que la variable sea más importante.
En un modelo \(y = a_0 + a_1*x_1 + a_2*x_2 + a_3*x_3 + …\), un aumento de \(x_1\) en 1 cambia y en \(a_1\), manteniendo \(x_2\), \(x_3\), … constantes.
Podemos también saber qué factores reducir y en cuánto para disminuir el valor de una casa a nuestro presupuesto. Asi podremos saber qué caracteristicas buscar de una casa para llegar al presupuesto que nosotros estimamos.
Si aumentamos una variable independiente y mantenemos constantes las demás variables independientes, la variable dependiente aumenta si la variable independiente tiene un coeficiente positivo, y disminuye si la variable independiente tiene un coeficiente negativo.
Ajuste del modelo a los datos
Ya hemos visto cómo interpretar los coeficientes de un modelo de regresión. Pero, ¿de dónde proceden esos coeficientes? Los coeficientes se calculan para obtener el modelo que mejor se ajusta a los datos.
Ajustar los datos lo mejor posible significa acercar la línea lo más posible a todos los puntos de datos, para minimizar el error cuadrático medio (MSE). Ajustar la línea de mejor ajuste en un diagrama de dispersión funciona para una única variable x, pero no para una regresión múltiple con más variables. Cuando tenemos más de una variable independiente los coeficientes mueven los puntos, en vez de la línea para ajustar los datos. Cuando ajustamos el coeficiente los puntos se mueven por el eje de los puntos que estamos prediciendo. En resumen, los coeficientes son utilizados para predecir el precio o cualquier variable dependiente que estemos analizando, dentro del contexto de una regresión lineal multiple.
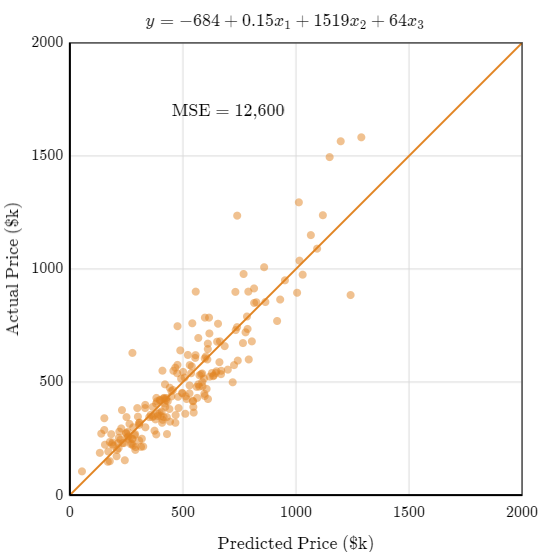
Cuando tenemos varias variables independientes (en este caso 3) cuesta más hacer un ajuste manual para que podamos ajustar de mejor manera los puntos. Una persona podría tardar horas en encontrar la ecuación de regresión múltiple óptima, pero una computadora puede encontrarla en menos de un segundo. Cuantos más coeficientes tengamos, más difícil será encontrar manualmente el mejor ajuste.
Evaluar el modelo
Ha llegado el momento de vender la propiedad, pero ¿cuál sería un precio razonable?
Entre más variables independientes agreguemos al modelo, tanto mejor, pero solo hasta cierto punto. El modelo tendrá más información para funcionar, pero si aprende mucho de los datos podriamos estar en una situación en donde funcione solo para esos datos y no para otros. Sin embargo, ante la ausencia de información adicional que aporte valor al modelo, siempre la mejor predicción será el valor medio.
A medida que vamos agregando más variables, vamos reduciendo el MSE. Esta reducción se le conoce como coeficiente de determinación o \(R^2\). La formula sería la siguiente:
\(1 - \left(\frac{\text{ECM del modelo}}{\text{ECM del modelo base}}\right)\)
Cuanto menor sea la distancia media entre los valores reales y los previstos, el más se acercará a 1 es el coeficiente de determinación.
Elegir las variables de evaluación
Para hacer predicciones precisas con la regresión, tenemos que incluir las variables adecuadas en el modelo. Primero nos conviene incluir la variable independiente que tiene más correlación con la variable dependiente. Podemos ver también que hay variables que tienen poca o nada de correlación, sin embargo, esto por poco intuitivo que parezca, la inclusión de estas variables con nula correlación pueden también contribuir información al modelo y mejorar su coeficiente de determinación.
Si por ejemplo, tenemos un modelo de regresión lineal simple que incluye los metros cuadrados de una casa y su precio. Tenemos que pensar que una variable mejora las predicciones cuando aporta información que no está ya en el modelo. Antes de añadir una segunda variable, el modelo ya “conoce” el tamaño de la vivienda.
Si tenemos un modelo donde en general las casas grandes se encuentran en barrios ricos y a medida que nos adentramos en barrios más pobres las casas son más pequeñas, la variable de la ubicación o zip no nos serviría de mucho, porque estaría colindando con el tamaño de las casas. En consecuencia no estaría aportando mucha información adicional al modelo. Esto quizás nos suceda con alguna ciudad que estamos evaluando, pero ciertamente no en todas sucede lo mismo y eso es lo que tenemos que ir evaluando. Lo importante es que la variable que nosotros agreguemos al modelo pueda brindar mucha información.
En general, sucede con la tipología, donde entre más grande sea la casa, más piezas y baños tendrá. Por lo mismo, si tenemos un modelo lineal simple con precio como variable independiente y tamaño con variable dependiente, dada la alta correlación entre cantidad de baños o piezas con el tamaño de la propiedad, agregarlas al modelo no produciría una mejora significativa en el coeficiente de determinación.
Las variables independientes tienden a producir mejores predicciones cuando están:
- Fuertemente correlacionadas con la cantidad que queremos predecir.
- Débilmente correlacionadas o no correlacionadas entre sí.
Evitar el sobreajuste
Para hacer buenas predicciones, queremos que nuestro modelo se ajuste bien a los datos. Pero, ¿puede ser demasiado bueno?
Imaginemos que por ahora tenemos un modelo de regresión lineal simple donde solo tenemos el precio y el área. Podríamos inventar nuevas variables de manera aleatoria y con baja correlación con el precio para incluirlas en el modelo y experimentar. Como estamos agregando más variables que podemos ir ajustandolo al modelo con el coeficiente, vamos a mejorar el modelo de todas formas a pesar que los datos sean inventados.
El proceso de inventar datos lo podemos hacerlo un montón de veces y cada vez que lo hagamos el \(R^2\) irá en aumento hasta llegar a casi 1. El modelo se ve increible, pero fue alimentado solo con datos inventados. Si se incluyen suficientes variables, un modelo de regresión acabará ajustándose perfectamente a los datos, sean o no significativas esas variables.Esto se denomina sobreajuste.
Podemos construir un modelo que puede “predecir” perfectamente el precio de las casas utilizadas para entrenarlo, pero ¿Cómo crees que será este modelo a la hora de predecir los precios de otras casas de la misma zona?
Como los datos fueron alimentados solo con datos que no tienen sentido, el modelo aprendió de esos datos, por lo que si le agregamos datos nuevos, el modelo no logrará predecir ni por cerca el precio de cada una de ellas. Incluso la regresión lineal simple donde tenemos área y precio, logrará tener mejores resultados de predicción que un modelo sobreajustado cuando incorporamos nuevos datos de predicción al modelo.
Al añadir más variables, nuestro modelo empeoraba sus predicciones sobre datos desconocidos, aunque se ajustaba cada vez mejor a los datos iniciales. El exceso de ajuste da lugar a modelos que parecen buenos al principio, pero que hacen malas predicciones.
Los sobreajustes los podemos evita utilizando grandes volumenes de datos y/o utilizando menos cantidad de variables en el modelo. Con un conjunto de datos más amplio, resulta más fácil saber qué variables merece la pena incluir y cuáles no.
Es posible sobreajustar un modelo con una variable que parece que podría ser relevante. Cuando una variable aumenta \(R^2\) sólo ligeramente, puede ser mejor omitirla. Introducir más variables en un modelo siempre hace que se ajuste más a los datos, pero no siempre da lugar a mejores predicciones. Un modelo más sencillo, con menos variables, suele ser más útil.
Interpretación del Modelo
Reformar una casa puede ser estresante y costoso. Merece la pena evaluar el efecto potencial sobre el valor de reventa antes de seguir adelante. Digamos que estamos pensando en añadir un dormitorio más.
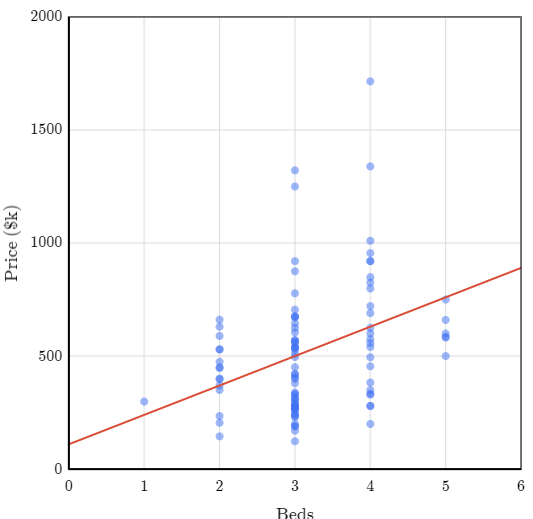
El gráfico de dispersión muestra el precio de venta y el número de dormitorios de una selección aleatoria de ventas de viviendas en el condado de King. Podemos ver en que general, entre más dormitorios tenemos, más caras son las propiedades.
La ecuación de la línea es \(y = 110 + 130x_1\). Esto nos quiere decir que por un dormitorio adicional la casa tendría un aumento en su coste de 130K dólares. Esto es bastante, pero tenemos que considerar que las casas con más dormitorios también suelen ser diferentes en otros aspectos, así que no es sólo el número de dormitorios lo que hace que el precio sea más alto. Por ejemplo, las casas de 4 dormitorios, además de agrandar la superficie de la casa, suelen estar acompañadas por más baños.
Como nosotros estamos solo añadiendo un dormitorio, dejando el mismo número de baños, tenemos que hacer otro tipo de análisis. Podemos controlar las variables “Superficie” y “Baños” comparando únicamente inmuebles de tamaño similar y con el mismo número de baños. Digamos que queremos revisar varios rangos de superficies de casas, como 1900-2000 \(ft^2\), 2000-2100 \(ft^2\), 2100-2200 \(ft^2\) y 2200-2300 \(ft^2\).
Para todas las casas evaluadas en esos segmentos, tenemos un coeficiente negativo para la cantidad de camas, es decir, al dejar la superficie y el número de baños constantes, un número de camas adicional disminuiria su precio. Quizás por que la razón entre dormitorios y baños se vería afectada y la gente no estaría dispuesta a comprar una propiedad con esas características. En resumen, para aislar el efecto de un dormitorio adicional:
- Seleccionamos un conjunto de casas con superficies similares y el mismo número de cuartos de baño.
- Realizamos una regresión simple con el precio en función de los dormitorios.
Pero esta no es la única forma de examinar el efecto de una sola variable en el precio de una casa.
Otra forma de ver el efecto de las camas en el precio controlando la zona y el baño es incluir todas estas variables en un modelo de regresión múltiple. De esta manera, trabajamos con una regresión lineal multiple y controlamos los coeficientes de cada variable para saber cuál es el mejor ajuste para el precio. Si agregamos las camas, los baños y el área de la casa en una misma regresión lineal la formula quedaría así:
\(y = 88-64x_1 + 9.3x_2 + 0.31x_3\)
Donde \(x_1\) representa el número de camas, \(x_2\) representa el número de baños y \(x_3\) representa el área. Parece que añadir un dormitorio más no suele aumentar el valor de una casa si todo lo demás permanece igual. Tal vez añadir un cuarto de baño sería una mejor inversión, porque tiene un coeficiente positivo de 9.3.
Sin embargo, esto no significa que efectivamente el valor de la casa aumente con un baño extra, porque quizás la correlación es muy pobre entre baño y precio. Para descubrirlo, debemos controlar las demás variables, como lo hicimos anteriormente y ver la correlación para cada segmento de área. Si controlamos por camas y superficie, la correlación entre precio y baño es débil, por lo que no podemos confiar en que un baño adicional aumente el precio de una casa.
Los coeficientes por sí solos pueden no contar toda la historia. Inspeccionar los datos visualmente es una forma de comprobar la fiabilidad de las predicciones.
Utilizar variables categóricas
Para los trabajadores a distancia, mudarse a un lugar barato es una forma viable de ahorrar costes de vivienda. ¿Cuánto se puede ahorrar mudándose de una zona urbana a una rural del condado de King, Washington?
Supongamos que sólo disponemos de tres datos sobre la venta de casas: El precio en miles de dólares, la superficie en metros cuadrados y si el entorno se considera “urbano”, “suburbano” o “rural”.
El problema con analizar una base de esas características es que los modelos matemáticos, como la regresión lineal, no soportan datos que sean de texto. Para convertir la variable “Entorno” en información numérica, podemos crear tres nuevas variables binarias, una para cada categoría.
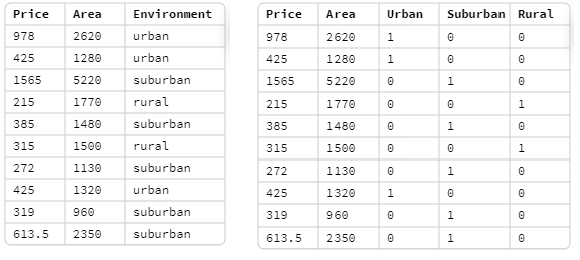
Si incorporamos las variables binarias por separado al modelo, veremos que mejora el \(R^2\), pero el rural mejora más que el urbano. Sin embargo, si juntamos dos variables al modelo, como el rural y el urbano, el suburbano y el rura, etc. no importa que conbinación hagamos porque siempre dará el mismo \(R^2\). Para entender porque ocurre este fenomeno debemos saber primero que el modelo mejorará siemore y cuando le demos más información que desconoce. Si le pasamos la tercera variable binaria al modelo, el \(R^2\) no aumentará, porque no estamos pasandole nueva información a la regresión. Dicho de otro modo, si ya tenemos dos variables incorporadas al modelo, por ejemplo urbano y rural, por descarte podemos saber también si es suburbano, dado que si no es ni urbano ni rural, entonces es suburbano. Esto significa que no necesitamos pasarle las tres variables “Entorno” al modelo, si no que solo dos.
Con el entorno en el modelo y de forma numérica ya podremos utilizarlo para mejorar nuestras predicciones y saber en cuánto el entorno puede afectar el precio de un inmueble.
Interacción de variables
Imaginemos ahora que tenemos una casa frente al mar vs otra que no está frente al mar.
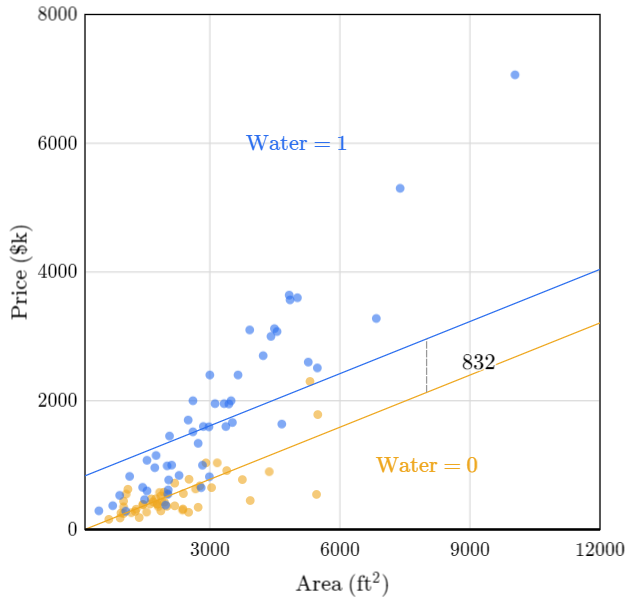
Como el gráfico lo sugiere, una casa frente al mar vale más que una casa que no lo está, especificamente 832K dólares más. Sin embargo, vemos que el modelo no funciona bien para las casas frente al mar. La línea que representa la relación entre el precio y la superficie debería ser más pronunciada para las casas con fachada al agua que para las que no la tienen. Esto sugiere que las dos variables independientes interactúan.
Dos variables independientes $ x_1 $ y \(x_2\) interactúan si el impacto de \(x_1\) sobre la variable dependiente \(y\) depende del valor de \(x_2\). El hecho que necesitemos más pendiente para las casas frente al mar en el modelo sugiere que cada metro cuadrado adicional cuesta más en las casas con fachada al agua que en las que no la tienen. Para estar seguros podríamos utilizar los modelos con interacción.
Modelos con interacción
Cuando tenemos un modelo con interacción no es mala idea multiplicar las variables independientes que interactuan entre sí y agregarlas al modelo.
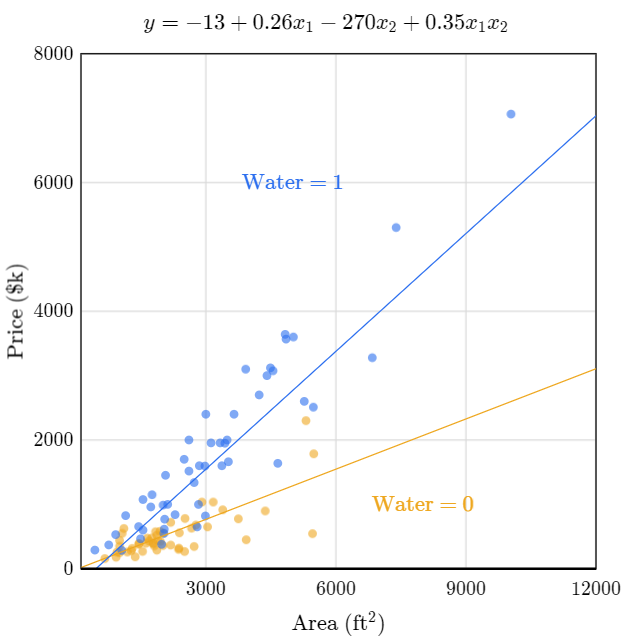
En la imagen anterior podemos ver que está incluida en la formula el \(x_1*x_2\). Esto es la variable área multiplicada por la variable “frente al mar” que puede ser uno (si está frente al mar) o cero (si no está frente al mar). Esta técnica es lo que se llama como modelo con interacción y fijemonos como mejora el modelo cuando agregamos esta interacción entre estas dos variables. Un término de interacción es el producto de dos o más variables independientes que tienen un efecto conjunto sobre la variable dependiente.
Ahora si por ejemplo queremos ver el efecto de un aumento en el área de un pie cuadrado adicional, este aumento siempre estará ligado a si la casa está o no frente al mar. Especificamente si aumentamos la casa en un pie cuadrado adicional, obtenemos un precio adicional de \(0.26 + 0.35*x_2\).
En este ejemplo, utilizamos una variable binaria, pero no siempre tiene que ser el caso. Podemos también tener interacción con dos variables continuas, como el precio medio del código postal, Zip y el área. El valor de cada pie cuadrado depende del código postal, pero es difícil darse cuenta de ello sin un término de interacción. Es por eso que es útil crear uno primero multiplicando ambas variables.
Deja un comentario