
Precio de Diamantes
Primera parte: Entendiendo el problema y propuesta de la solución
Contexto
Imaginemos que la empresa IDR (Intelligent Diamond Reseller) está interesado en el negocio de la compra y venta de diamantes. Ellos compran diamantes al precio más bajo posible y luego, lo venden a un mayor precio para obtener una ganancia.
La empresa necesita tener un modelo predictivo para definir un precio de compra para mejorar su competitividad en el mercado, disminuyendo sus costos.
La empresa le envia un dataset que contiene el precio y las caracteristicas de alrededor de 54.000 diamantes. En esta se pueden contemplar las siguientes caracteristicas:
- Dimensión: 53.940 observaciones y 10 variables.
- Unidad de observación: Diamantes
- Las variables son:
- price: Precio en dólares americanos.
- carat: Peso del diamante en quilates (un quilate son 0,2 gramos).
- cut: Calidad del corte (fair, good, very good, premium, ideal).
- color: El color del diamante desde J (lo peor) hasta D (lo mejor).
- clarity: Medida de claridad del diamante. De peor a mejor: I1, SI2, SI1, VS2, VS1, VVS2, VVS1, IF.
- x: Largo en milimetros.
- y: Ancho en milimetros.
- z: Profundidad en milimetros.
- depth: Porcentaje de la profundidad total (z/promedio entre x e y).
- table: Ancho de la parte superior del diamante en relación con el punto más ancho.
En base al sitio https://www.diamonds.pro/ los factores más importantes para definir el precio del diamante son el peso, el color, la claridad y el corte. Son buenas noticias, dado que tenemos todas esas caracteristicas en nuestro dataset.
Además de poner atención en lo que tenemos, es importante observar que información nos puede faltar. Para este dataset nos falta saber si los diamantes tienen una certificación o no. Los clientes están dispuestos a pagar más si el diamante tiene certificación y por eso es importante hablar con la empresa IDR para que nos dé información adicional. En este caso, todos los diamantes de la base de datos cuentan con certificación.
Es fundamental realizar reuniones con las personas involucradas de la empresa para definir expectativas, cuales son los datos importantes dentro de una persectiva de negocios, definir el impacto de la solución en terminos medibles (horas ahorradas, dinero, etc), conocer el contexto/negocio de la empresa, etc. Todo esto es para entender el problema en su totalidad y definir objetivos y metodologías para dar solución a este problema.
Objetivos
Los objetivos para este problema son los siguientes:
- Usar todas las columnas del dataset, excepto el precio.
- Construir un modelo que prediga el precio de diamantes lo más preciso posible, basado en los atributos.
- Predecir los precios de los diamantes ofrecidos por el proveedor para que IDR decida cuánto pagará por ellos.
Metodología
La variable objetivo a predecir es el precio del diamante, por lo que los atributos o columnas restantes serán 9. Como hablamos de precio la variable a predecir es una variable continua. El tipo de problema que abordaremos es un problema de regresión. Cuando la variable objetivo es continua, estamos dentro de una categoría de problemas llamado tareas de regresiones.
Para la evaluación del modelo, si la predicción está cerca de los valores reales es considerada buena y viceversa.
La forma en que los usuarios finales verán el modelo también se debe conversar en los primeros momentos. Es importante saber si el área comercial de IDR desea ver los resultados del modelo a través de una página web, aplicación, cloud computing, etc. Para este ejercicio, la producción del modelo será en una página web con Dash.
Segunda parte: Recolectar y preparar los datos
La recolección de los datos va dependiendo del proyecto. A veces tenemos que nosotros buscar los datos utilizando la tecnología ETL (extract, transform, load), pedir acceso a la base de datos de la compañia o conectarse a data externa como Bloomberg, Quandl o alguna API REST.
Para este caso, la data es extraida de Kaggle (https://www.kaggle.com/shivam2503/diamonds)
# importamos las librerías que necesitamos para esta segunda parte.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
# importamos el dataset.
diamonds = pd.read_csv('diamonds.csv')Ya con la base de datos importada, es buena práctica realizar una primera aproximación para corroborar que los datos hayan sido correctamente importados.
# Vemos las primeras 5 observaciones del dataframe
diamonds.head()| Unnamed: 0 | carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 2 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 3 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 4 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 5 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
Vemos que hay una columna llamada "Unnamed: 0". Nos podemos deshacer de ella usando otra forma de importar el dataframe
diamonds = pd.read_csv('diamonds.csv', index_col=0)
diamonds.head()| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 2 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 3 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 4 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 5 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
Ahora que vemos que la importación fue éxitosa, podemos seguir explorando...
# dimensión del dataframe
print('Cantidad de observaciones: {}.\nCantidad de atributos: {}.'.format(*diamonds.shape))
Cantidad de observaciones: 53940.
Cantidad de atributos: 10.
diamonds.describe()Cantidad de observaciones: 53940. Cantidad de atributos: 10.
diamonds.describe()| carat | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|
| count | 53940.000000 | 53940.000000 | 53940.000000 | 53940.000000 | 53940.000000 | 53940.000000 | 53940.000000 |
| mean | 0.797940 | 61.749405 | 57.457184 | 3932.799722 | 5.731157 | 5.734526 | 3.538734 |
| std | 0.474011 | 1.432621 | 2.234491 | 3989.439738 | 1.121761 | 1.142135 | 0.705699 |
| min | 0.200000 | 43.000000 | 43.000000 | 326.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 0.400000 | 61.000000 | 56.000000 | 950.000000 | 4.710000 | 4.720000 | 2.910000 |
| 50% | 0.700000 | 61.800000 | 57.000000 | 2401.000000 | 5.700000 | 5.710000 | 3.530000 |
| 75% | 1.040000 | 62.500000 | 59.000000 | 5324.250000 | 6.540000 | 6.540000 | 4.040000 |
| max | 5.010000 | 79.000000 | 95.000000 | 18823.000000 | 10.740000 | 58.900000 | 31.800000 |
El output anterior es muy util para un checkeo rápido de valores extraños, como por ejemplo valores negativos o ceros en la fila "min" que en este contexto no deberían existir.
Podemos ver que hay un valor que hace ruido: En el atributo carat o peso del diamante, encontramos que el máximo es 5,01, siendo demasiado alto. Sabemos que es alto considerando que el percentil 75 es 1,04 lo que es una gran diferencia. Es por tanto considerado como candidato a un valor atípico (outlier en inglés).
Aunque existan valores atípicos, no necesariamente significa que tendremos que deshacernos de ellos; nuevamente depende del contexto. Como en este caso, las demás variables se ven bien o dentro de un rango apropiado, no excluiremos ese valor.
En otros contextos, por ejemplo, en el análisis de ingresos generales de la población de USA, probablemente no incluiremos a Jeff Bezos en en análisis. Todo depende si lo consideramos apropiado o no según los objetivos propuestos.
Nota : Se considera valor atípico cuando el valor es mayor al percentil 75 en al menor 1,5 veces el rango intercuartílico o menor al percentil 25 en al menos 1,5 veces el rango intercuartílico.
Manejando los valores pérdidos
La limpieza de datos por lo general toma mucho esfuerzo y tiempo. No hay un estándar de como hacerlo, porque cada proceso es único para todos los datasets. Para este caso, no es tanto trabajo, pero no siempre tendremos esa suerte.
Vamos a comenzar analizando las variables x, y, z dado que llama la atención que el valor mínimo de estas variables sea 0, es decir, es como si se tratasen de diamantes 2D
diamonds.loc[diamonds.x==0]| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 11183 | 1.07 | Ideal | F | SI2 | 61.6 | 56.0 | 4954 | 0.0 | 6.62 | 0.0 |
| 11964 | 1.00 | Very Good | H | VS2 | 63.3 | 53.0 | 5139 | 0.0 | 0.00 | 0.0 |
| 15952 | 1.14 | Fair | G | VS1 | 57.5 | 67.0 | 6381 | 0.0 | 0.00 | 0.0 |
| 24521 | 1.56 | Ideal | G | VS2 | 62.2 | 54.0 | 12800 | 0.0 | 0.00 | 0.0 |
| 26244 | 1.20 | Premium | D | VVS1 | 62.1 | 59.0 | 15686 | 0.0 | 0.00 | 0.0 |
| 27430 | 2.25 | Premium | H | SI2 | 62.8 | 59.0 | 18034 | 0.0 | 0.00 | 0.0 |
| 49557 | 0.71 | Good | F | SI2 | 64.1 | 60.0 | 2130 | 0.0 | 0.00 | 0.0 |
| 49558 | 0.71 | Good | F | SI2 | 64.1 | 60.0 | 2130 | 0.0 | 0.00 | 0.0 |
Vemos que las variables de profundidad para z que son 0 también lo son para las variables x e y (excepto por uno). Tiene sentido entonces tratar estos valores 0 como datos pérdidos.
Hay muchas formas de tratar valores pérdidos, desde eliminando la observación completa a utilizar algoritmos de imputación que intentan adivinar el mejor valor para sustituir el valor pérdido, como por ejemplo, utilizar K-nearest neighbors.
Para mantener el ejercicio simple, excluiremos las observaciones donde x, y, z son datos pérdidos. Perderemos información, pero hay 53.940 observaciones, por lo que perder 7 no será un mayor problema.
diamonds = diamonds.loc[(diamonds.x > 0) | (diamonds.y > 0)]Ahora solo nos falta lidiar con un valor pérdido en la fila 11183, dado que el valor de "y" es mayor a cero.
diamonds.loc[11183]carat 1.07 cut Ideal color F clarity SI2 depth 61.6 table 56 price 4954 x 0 y 6.62 z 0 Name: 11183, dtype: object
Siendo que este diamante no está muy alejado del precio promedio o el peso promedio, podremos reemplar el valor pérdido de x con su mediana, porque al estar al medio de una distribución continua es un buen indicador de un valor tipico, además no está afecta a los valores atípicos, como si lo está el promedio.
diamonds.loc[11183, 'x'] = diamonds.x.median()
diamonds.loc[diamonds['x']==0].shape(0, 10)
Ahora vemos que no tenemos valores pérdidos para x. Vamos a repetir el mismo proceso para z, dado que ya lidiamos con los valores pérdidos de y.
diamonds.loc[diamonds.y==0]| carat | cut | color | clarity | depth | table | price | x | y | z |
|---|
diamonds.loc[diamonds.z==0]| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2208 | 1.00 | Premium | G | SI2 | 59.1 | 59.0 | 3142 | 6.55 | 6.48 | 0.0 |
| 2315 | 1.01 | Premium | H | I1 | 58.1 | 59.0 | 3167 | 6.66 | 6.60 | 0.0 |
| 4792 | 1.10 | Premium | G | SI2 | 63.0 | 59.0 | 3696 | 6.50 | 6.47 | 0.0 |
| 5472 | 1.01 | Premium | F | SI2 | 59.2 | 58.0 | 3837 | 6.50 | 6.47 | 0.0 |
| 10168 | 1.50 | Good | G | I1 | 64.0 | 61.0 | 4731 | 7.15 | 7.04 | 0.0 |
| 11183 | 1.07 | Ideal | F | SI2 | 61.6 | 56.0 | 4954 | 5.70 | 6.62 | 0.0 |
| 13602 | 1.15 | Ideal | G | VS2 | 59.2 | 56.0 | 5564 | 6.88 | 6.83 | 0.0 |
| 24395 | 2.18 | Premium | H | SI2 | 59.4 | 61.0 | 12631 | 8.49 | 8.45 | 0.0 |
| 26124 | 2.25 | Premium | I | SI1 | 61.3 | 58.0 | 15397 | 8.52 | 8.42 | 0.0 |
| 27113 | 2.20 | Premium | H | SI1 | 61.2 | 59.0 | 17265 | 8.42 | 8.37 | 0.0 |
| 27504 | 2.02 | Premium | H | VS2 | 62.7 | 53.0 | 18207 | 8.02 | 7.95 | 0.0 |
| 27740 | 2.80 | Good | G | SI2 | 63.8 | 58.0 | 18788 | 8.90 | 8.85 | 0.0 |
| 51507 | 1.12 | Premium | G | I1 | 60.4 | 59.0 | 2383 | 6.71 | 6.67 | 0.0 |
z_median = diamonds.z.median
for i in diamonds.loc[diamonds.z==0].index:
diamonds.loc[i, 'z'] = diamonds.z.median()Si observamos otra vez la tabla con las descripciones estadísticas, veremos que hay valores muy extremos para z e y. Es muy dificil encontrar un diamante de más de 3 centimetros en cualquiera de las dimensiones, por lo que, si vemos esos valores, podemos estar seguros que se trata de errores en las mediciones. Como solo hay tres, la manera más apropiada es removerla de nuestro análisis.
diamonds.loc[(diamonds.y > 30) | (diamonds.z > 30)]| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 24068 | 2.00 | Premium | H | SI2 | 58.9 | 57.0 | 12210 | 8.09 | 58.90 | 8.06 |
| 48411 | 0.51 | Very Good | E | VS1 | 61.8 | 54.7 | 1970 | 5.12 | 5.15 | 31.80 |
| 49190 | 0.51 | Ideal | E | VS1 | 61.8 | 55.0 | 2075 | 5.15 | 31.80 | 5.12 |
# removemos estos tres valores de nuestro dataset.
diamonds = diamonds.loc[~((diamonds.y > 30) | (diamonds.z > 30))]Analizando variables categóricas
One-hot encoding es una manera de representar los datos categóricos a valores binarios, indicando con un 1 si cierto atributo se encuentra dentro de la observación y 0 si no se encuentra. Pandas cuenta con el método get_dummies para este fin.
pd.get_dummies(diamonds['cut'], prefix='cut')| cut_Fair | cut_Good | cut_Ideal | cut_Premium | cut_Very Good | |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 0 | 0 |
| 2 | 0 | 0 | 0 | 1 | 0 |
| 3 | 0 | 1 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 1 | 0 |
| 5 | 0 | 1 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... |
| 53936 | 0 | 0 | 1 | 0 | 0 |
| 53937 | 0 | 1 | 0 | 0 | 0 |
| 53938 | 0 | 0 | 0 | 0 | 1 |
| 53939 | 0 | 0 | 0 | 1 | 0 |
| 53940 | 0 | 0 | 1 | 0 | 0 |
53930 rows × 5 columns
Esto genera un nuevo DataFrame que contiene 5 columnas correspondientes a las 5 categorías dentro del atributo cut. Sin embargo, nosotros no necesitamos 5 columnas para representar 5 categorías, sino que basta con 4: Cuando todos los atributos sean ceros significa que el quinto atributo es el que está presente dentro de la observación y de esta manera evitamos la colinealidad. El método get_dummies cuenta con un argumento llamado drop_first para generar K-1 columnas que es lo que estamos buscando.
pd.get_dummies(diamonds['cut'], prefix='cut', drop_first=True)| cut_Good | cut_Ideal | cut_Premium | cut_Very Good | |
|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 |
| 3 | 1 | 0 | 0 | 0 |
| 4 | 0 | 0 | 1 | 0 |
| 5 | 1 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... |
| 53936 | 0 | 1 | 0 | 0 |
| 53937 | 1 | 0 | 0 | 0 |
| 53938 | 0 | 0 | 0 | 1 |
| 53939 | 0 | 0 | 1 | 0 |
| 53940 | 0 | 1 | 0 | 0 |
53930 rows × 4 columns
La variable _cutFair será la categoría base (categoría que sirve como referencia cuando los indicadores son ceros). Ahora realizamos un one-hot encoding para las otras dos variables categóricas que nos quedan y las agregamos al dataset principal.
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['cut'], prefix='cut', drop_first=True)], axis=1)
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['color'], prefix='color', drop_first=True)], axis=1)
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['clarity'], prefix='clarity', drop_first=True)], axis=1)diamonds.shape(53930, 27)
Tercera parte: Explorando el Dataset
En esta sección realizaremos un analisis exploratorio de nuestro dataset conocido como EDA. EDA es una combinación de tecnicas numéricas y de visualización que nos permite entender diferentes caracteristicas del dataset. Una forma de clasificar el tipo de analisis depende del número de variables involucradas en el analisis, como por ejemplo, la tecnica de analisis univariado (explorar una variable), bivariado (explorar dos variables) o multivariado (explorar más de dos variables). El objetivo de esta sección no es realizar analisis estadístico, si no que nos enfocaremos en la visualización e interpretación.
El proceso general de exploración puede ser como sigue a continuación:
- Cuando el dataset está más o menos listo para el análisis, comenzamos aplicando técnicas estándares para tener un conocimiento básico de las variables.
- Comenzamos a formarnos una hipótesis acerca de ciertos aspectos del dataset, dentro del contexto del problema.
- Aplicamos técnicas EDA para comenzar a confirmar o rechazar nuestra hipótesis y preconcebir algunas ideas.
- Empezaras a comprender el dataset. Nuevas ideas comenzarán a surgir.
- Aplicamos EDA nuevamente para intentar responder a esas preguntas. Ganaremos más entendimiento y nuevas preguntas comenzarán a surgir.
- Repetimos los procesis 4 y 5 algunas veces y paramos cuando nos sintamos comodos del entendimiento que obtuvimos y estamos ya seguros que podemos seguir con la fase del modelamiento.
EDA Univariado
El EDA univariado se aplica a una variable o atributo. Realizar un análisis exploratorio para cada variable por separado es siempre el primer paso y es en casi todos los casos una actividad mandatoria. Nuestro objetivo es entender cada variable individualmente en términos de valores típicos, variación, distribución, etc.
# importamos seaborn que se complementa con matplotlib para la exploración
import seaborn as sns# separamos las variables numéricas con las categóricas
numerical_features = ['price', 'carat', 'depth', 'table', 'x', 'y', 'z']
categorical_features = ['cut', 'color', 'clarity']EDA para variables numéricas
La primera aproximación que utilizaremos es un EDA numérico. Una buena herramienta para determinar la distribución de las variables numéricas es utilizando un histograma. Imaginemos una recta numérica donde están todas nuestras observaciones. Lo que hace el histográma es separar esta recta numérica en intervalos iguales llamados bins o contenedores. La altura del histograma (eje y) representa la cantidad de valores que se observar en un bin y así saber si los datos están distribuidos de una manera simétrica o sesgada, entre otras conclusiones.
Como vamos a realizar un histograma para cada variable numérica, vamos a encapsular código en una función para hacer el proceso más eficiente.
def desc_num_feature(feature_name, bins=30, edgecolor='k', **kwargs):
describe = diamonds[feature_name].describe().round(2)
data1 = [i for i in describe.index]
data2 = [str(i) for i in describe]
text = ('\n'.join([ a +': '+ b for a,b in zip(data1, data2)]))
fig, ax = plt.subplots(figsize=(8, 4))
diamonds[feature_name].hist(bins=bins, edgecolor=edgecolor, ax=ax, **kwargs)
ax.set_title(feature_name, size=15)
plt.figtext(.95, 0.25, text , fontsize=15)desc_num_feature('price')
Creamos nuestro histograma con 30 bins, por lo que el tamaño de cada bin está dado por la resta entre el valor superior e inferior dividido por 30.
bin_size = (18823-326) / 30
bin_size16.5666666666667
Podemos observar que en el primer bin, va entre un precio de 326 (minimo) a 943 (326 + 617). Entre esos precios vemos que hay aproximadamente 13.200 diamantes siendo el bin con el mayor número de observaciones (24% del total de datos aprox). Podemos observar también que entre mayor sea el precio, menos diamantes veremos. Esta distribución se le conoce como distribución sesgada a la derecha. Hay otros tipos de distribuciones comunes, como la distribución simétrica, modal y bimodal. En la siguiente imagen vemos algunas de ellas.
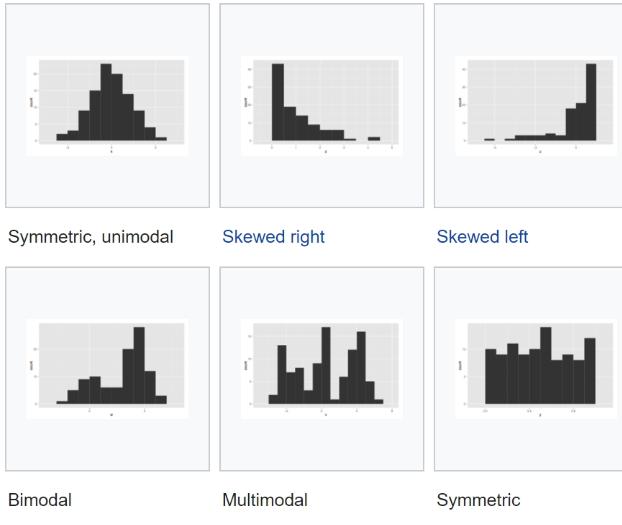
Un análisis numérico intenta explicar las distintas medidas de centralización, como la media, mediana y moda y las medidas de dispersión, como la desviación estándar, todo con el fin de entender más la distribución de los precios entre los distintos diamantes.
- Mientras el precio sube, se observan menos diamantes.
- Hay una alta variabilidad en los precios, reflejada en una desviación estándar de 4.000 dólares
- Por esta alta variabilidad en los precios y la larga cola de distribución, no hay tal cosa como un "diamante típico".
- En el primer cuarto de las observaciones el precio va entre 326 a 949,25, siendo un intervalo bien pequeño. No es raro por tanto encontrar diamantes menores a 1.000 dólares.
- Para un diamante que no es muy caro ni muy barato (25% a 75% de los datos) el rango de precio va entre los 950 y los 5.300 dólares.
- La mitad de los diamantes valen menos que 2.401 dólares.
- La distribución de los precios es distribución sesgada a la derecha. Esto tiene implicancias en la forma en que debemos realizar el modelado.
El mismo analisis se puede hacer para las demás variables. Veamos a continuación como se comportan.
for i in numerical_features:
desc_num_feature(i)





1) carat:
- El peso del diamante tiene una distribución multinominal para las primeras observaciones y va formando una cola luego que el peso supere el quilate, siendo más una distribución sesgada a la derecha.
- Hay 1/4 de posibilidad de encontrarse con un diamante superior a un quilate y es raro encontrar diamantes superiores a dos quilates
- Solo 0,2 quilates hay de intervalo en el primer cuartil.
- Un diamante no tan liviano, pero tampoco tan pesado (primer a tercer cuartil) se encuentra entre 0,2 y 1,04 quilates.
- La desviación es alta, por lo que no hay un peso que sea tipico entre los diamantes.
2) depth:
- El porcentaje de profundidad total del diamante sigue una distribución normal, siendo la media con la mediana muy cercanos.
- Los valores se concentran mucho en el centro, pudiendo existir muchos valores atípicos. Esto lo podemos ver además del gráfico en los percentiles: El mínimo es 43 y entre el primer y tercer cuartil solo hay una diferencia de 1,5. El máximo es 79 lo que también deja mucha diferencia entre el primer y tercer cuartil.
- La desviación estándar es baja: los datos se concentran mucho en un solo lugar.
3) table:
- El ancho de la parte superior del diamante en relación con el punto más ancho sigue una distribución parecida a la variable anterior, solo que su desviación no es tan baja
4) x:
- El largo en mm tiene una distribución más simétrica, en el sentido de que el rango entre el primer y el tercer cuartil tiene mucha amplitud, pero los datos no parecen seguir un patrón de distribución
- Se observan pocas observaciones para diamantes muy largos y en general, las mayores observaciones están en menores largos.
5) y:
- El ancho sigue una distribución muy parecida al largo, siendo la muestra de diamantes similar en su ancho y largo.
6) z:
- La profundidad en cambio comienza en números más bajos (minimo en 1,07 mm) siendo extraño encontrar diamantes que su profundidad sea mayor a su ancho y largo.
- Hay una gran amplitud entre el minimo y el primer cuartil, siendo común encontrar diamantes con menos de 2 mm de profundidad.
- El promedio del diamante y la media son casi iguales, lo que da cuenta de que un diamante común tiene una profundidad de 3,5 mm.
- Los datos son simétricos, tomando en cuenta que la desviación es baja.
EDA para variables categóricas
La exploración por variables categóricas suele ser más fácil. Por lo general lo primero que queremos ver es la cantidad de observaciones que tenemos en cada categoría. Esto es util expresarlo como una proporción con respecto al total.
Por otro lado, así como el histograma es una visualización por defecto para las variables numéricas, el gráfico de barras es el gráfico utilizado por defecto para las variables categóricas.
def desc_cat_feature(index):
feature = categorical_features[index]
count = diamonds[feature].value_counts()
percent = 100 * diamonds[feature].value_counts(normalize=True)
df = pd.DataFrame({'count':count, 'percent':percent.round(1)})
print(df)
count.plot(kind='bar', title=feature)Veamos primero como se ve la distribución de variables categóricas para el corte.
desc_cat_feature(0)count percent Ideal 21549 40.0 Premium 13788 25.6 Very Good 12080 22.4 Good 4904 9.1 Fair 1609 3.0

Ahora, veremos la distribución para el color y la claridad.
desc_cat_feature(1)count percent G 11290 20.9 E 9795 18.2 F 9540 17.7 H 8301 15.4 D 6774 12.6 I 5422 10.1 J 2808 5.2

desc_cat_feature(2)count percent SI1 13065 24.2 VS2 12256 22.7 SI2 9190 17.0 VS1 8168 15.1 VVS2 5066 9.4 VVS1 3654 6.8 IF 1790 3.3 I1 741 1.4

Los gráficos de barra ya explican muy bien la información para cada variable categórica. Ahora tenemos una imagen más clara de qué categorías de diamantes son más y menos comunes para cada corte, color y claridad. Estamos ganando más entendimiento acerca del dataset.
EDA Bivariado
El EDA bivariado es utilizado para estudiar la relación entre dos variables y entender como están relacionadas entre si. La cantidad de pares de relaciones que obtendremos es (k(k-1))/2. En nuestro dataset original tenemos 10 variables, por tanto, esto corresponde a 45 pares de variables a analizar.
De todas formas, no necesitamos analizar todos los pares, solo los que nos interesan o los que podrían contestar una pregunta específica que puedas tener dentro de tu dataset.
Para explorar estas relaciones primero necesitamos saber qué tipo de variables tenemos, dado que tenemos tres posibilidades de comparación:
- Dos variables numéricas
- Dos variables categóricas
- Una variable numérica y otra variable categórica.
Para cada una hay visualizaciones estándares y calculos numéricos, pero puedes también aplicar creativamente otras formas de análisis. Que sea estándar no significa que no puedas innovar, pero las siguientes formas entregan suficiente información que podemos explorar.
Dos variables numéricas
El gráfico por excelencia para visualizar la relación entre dos variables numéricas es el diagrama de dispersión. Este gráfico basicamente ubica en un plano cartesiano las observaciones de dos variables, una ubicada en el eje x y la otra en el eje y.
Hay ciertas características que debemos considerar para poder interpretar correctamente un diagrama de dispersión. Estas son:
- Tendencia: Generalmente, tendremos una tendencia entre la relación de dos variables. Esta tendencia puede seguir una linealidad, una curva, exponencial o patrones más complicados.
- Fuerza/Ruido: Esto tiene que ver con cuanta claridad vemos la tendencia en la relación o que tan cerca los puntos siguen cierto patrón. También observaremos ruido en la forma de la desviación o dispersión entre los puntos, alrededor de la tendencia o el patrón promedio. Tendencias más fuertes muestran menos ruido y viceversa.
- Dirección: Si hay una relación entre las variables, notaremos hacia qué dirección va la tendencia. Esta puede ser positiva o negativa.
- Positiva: Ambas variables se mueven en la misma dirección: Mientras una variable crece, la otra también tiende a crecer y viceversa. En este caso, la tendencia va hacia arriba.
- Negativa: Las variables se mueven en direcciones diferentes: Si una crece, la otra tiende a decrecer y viceversa. En este caso, las variables tienden a ir hacia abajo.
En algunos casos las relaciones pueden ser positivas en algunos rangos y negativas en otros.
Veamos ahora algunos ejemplos
diamonds.plot.scatter(x='carat', y='price', s=.6)
- Tendencia: Vemos que la relación sigue una tendencia no lineal, quizás una cuadrática o exponencial.
- Fuerza/Ruido: A pesar de que la tendencia se ve clara, hay mucho ruido en esta relación. Aunque podamos imaginar una curva que pasa entre medio de los puntos, hay mucha desviación en esa tendencia general.
- Dirección: A medida que el peso del diamante aumenta (carat), el precio también aumenta, por lo que podemos apreciar una relación directa.
La conclusión del gráfico es que carat definitivamente nos ayudará a predecir el precio del diamante, pero detectamos una tendencia no lineal, lo que será una importante consideración a la hora de crear el modelo.
Si no hubiese relación entre dos variables, el diagrama de dispersión podría verse como una nube de puntos: puro ruido sin una tendencia definida. Esto no siempre es así: también pueden existir otras formas además de una nube que no nos muestre relación alguna. A continuación un ejemplo de ello.
diamonds.plot.scatter(x='table', y='price', s=.6)
Entre el precio y table (ancho de la parte superior del diamante en relación con el punto más ancho) no se ve ninguna relación. Realizaremos un zoom donde se encuentran la mayoria de los datos para ver si detectamos algún patrón.
diamonds.plot.scatter(x='table', y='price', s=.6, xlim=(50, 70))
Nuevamente es dificil ver cualquier relación entre table y precio.
Estas relaciones de variables numéricas no es necesarias hacerlas una a una. Una forma eficiente de graficar todas las relaciones posibles es utilizando la librería seaborn para graficar lo que se conoce como una matriz de diagrama de dispersión, siendo posible visualizar muchas relaciones al mismo tiempo.
sns.pairplot(diamonds[numerical_features], plot_kws={'s':2})
Esto resulta ser muy bonito, informativo y poderoso con una sola linea de código. Seaborn permite personalizar la diagonal de la matriz, por ejemplo, configurando el parámetro _diagkind="kde" en vez del histograma. El valor "kde" se refiere a la función de densidad de probabilidad que es una aproximación de la probabilidad de distribución para la variable. Veamos como se ve:
sns.pairplot(diamonds[numerical_features], plot_kws={'s':2}, diag_kind='kde')
¿En qué atributos vemos una mayor relación con respecto al precio?
Con este método podemos apreciar de manera inmediata si hay un patrón o tendencia y que tan fuerte es.
- Precio con respecto a las dimensiones (x, y, z): Hay una relación más o menos logarítmica con las dimensiones de largo, ancho y profundidad, lo que significa que ha medida de que hay mayor longitud en una de las dimensiones, la derivada del precio va a un ritmo decreciente. Si el precio estuviese en el eje y, sería al revés (tendencia exponencial).
- Precio con table: Como vimos anteriormente, no se ve ninguna relación.
- Precio con depth: El porcentaje de la profundidad total tampoco muestra relación con el precio.
- Precio con peso del diamante: Se ve una relación exponencial si el precio está en el eje x o logaritmica si esta en el eje y.
Una forma de ver las relaciones entre todas las variables más rápidamente es a través de valores numéricos con el cálculo del coeficiente de correlación de Pearson. Hay otros coeficientes de correlación, pero este es el más popular. Este es un indicador numérico que indica que tan fuerte es la relación entre ellas. Los valores van entre 1 y -1.
- Si el coeficiente toma valores cercanos a -1 la correlación es fuerte e inversa y será tanto más fuerte cuanto más se aproxime a -1.
- Si el coeficiente toma valores cercanos a 1 la correlación es fuerte e directa y será tanto más fuerte cuanto más se aproxime a 1.
- Si el coeficiente toma valores cercanos a 0 la correlación es débil y será tanto más fuerte cuanto más se aproxime a 0.
Si es exactamente 1 o -1, los puntos de la nube están sobre la recta creciente o decreciente. Si es 0 no hay absolutamente ninguna relación.
Importante: Si no existe relación significa que no hay dependencia lineal, lo que no quiere decir de que pueda haber una dependencia en otro tipo de distribución que no sea lineal.
En Pandas existe un método llamado corr() que nos permite ver todas la relación entre todas las variables de una sola vez mostrandolas en una matriz de la siguiente manera:
diamonds[numerical_features].corr()| price | carat | depth | table | x | y | z | |
|---|---|---|---|---|---|---|---|
| price | 1.000000 | 0.921603 | -0.010595 | 0.127157 | 0.887216 | 0.888810 | 0.881682 |
| carat | 0.921603 | 1.000000 | 0.028317 | 0.181650 | 0.977761 | 0.976844 | 0.975969 |
| depth | -0.010595 | 0.028317 | 1.000000 | -0.295722 | -0.025020 | -0.028151 | 0.096719 |
| table | 0.127157 | 0.181650 | -0.295722 | 1.000000 | 0.196129 | 0.189964 | 0.155885 |
| x | 0.887216 | 0.977761 | -0.025020 | 0.196129 | 1.000000 | 0.998652 | 0.990743 |
| y | 0.888810 | 0.976844 | -0.028151 | 0.189964 | 0.998652 | 1.000000 | 0.990405 |
| z | 0.881682 | 0.975969 | 0.096719 | 0.155885 | 0.990743 | 0.990405 | 1.000000 |
Esto confirma lo que ya habiamos visto graficamente: el peso tiene una relación muy fuerte con el precio, mientras que table y depth tienen casi nula relación el precio. Esto quiere decir que estas variables no son muy informativas para indicarnos el precio del diamante.
Vemos por otro lado que las dimensiones (x, y, z) tienen una correlación muy alta con el precio (alrededor de 0,88). Esto quiere decir que entre más grande el diamante, hay altas posibilidades de que el diamante sea más caro. El peso es la que más relación tiene con el precio (0,92) como lo evidenciamos anteriormente.
Para una visión más agradable, podemos hacer un heatmap con seaborn. De esta forma con solo ver los colores podemos determinar que valores tienen una alta o una baja relación entre ellas.
plt.figure(figsize = (8, 6))
sns.heatmap(diamonds[numerical_features].corr(), annot=True, linewidths=.5)
Ahora bien, observaremos más de cerca las variables que tienen una correlación más alta.
dim_features = diamonds[['carat', 'x', 'y', 'z']]
sns.pairplot(dim_features, plot_kws={'s':3})
dim_features.corr()| carat | x | y | z | |
|---|---|---|---|---|
| carat | 1.000000 | 0.977761 | 0.976844 | 0.975969 |
| x | 0.977761 | 1.000000 | 0.998652 | 0.990743 |
| y | 0.976844 | 0.998652 | 1.000000 | 0.990405 |
| z | 0.975969 | 0.990743 | 0.990405 | 1.000000 |
Vemos que las correlaciones son extremadamente altas. Las dimensiones x, y, z se ven claramente lineales en los diagramas de dispersión. ¿Que quiere decir esto?
Básicamente, las tres variables contienen la misma información, en otras palabras, no son independientes. Sabiendo el valor de una podemos saber aproximandamente el valor de la otra. Este es un caso cercano a la colinealidad.
Por otro lado, la relación entre el peso (carat) se ve cuadrática y muy fuerte, que por supuesto tiene sentido: entre mayor sean sus medidas, mayor es su peso. Estas dependencias entre estas cuatro variables pueden ser muy problemáticas para algunos modelos, por lo que tendremos que hacer algo al respecto.
Dos variables categóricas
Para explorar las relaciones posibles entre dos variables categóricas también tenemos dos herramientas estándares: gráfico de barras y tablas cruzadas o tablas de contingencia
Tablas cruzadas
La tabla cruzada es simplemente una tabla con filas y columnas donde podemos ver el número de observaciones para cada combinación de categorías para dos variables categóricas. Podemos utilizar la función crosstab para lograr este cometido.
pd.crosstab(diamonds['cut'], diamonds['color'])| color | D | E | F | G | H | I | J |
|---|---|---|---|---|---|---|---|
| cut | |||||||
| Fair | 163 | 224 | 312 | 313 | 303 | 175 | 119 |
| Good | 662 | 933 | 907 | 871 | 702 | 522 | 307 |
| Ideal | 2834 | 3902 | 3826 | 4883 | 3115 | 2093 | 896 |
| Premium | 1602 | 2337 | 2331 | 2924 | 2358 | 1428 | 808 |
| Very Good | 1513 | 2399 | 2164 | 2299 | 1823 | 1204 | 678 |
Aqui vemos la cantidad que hay para cada una de las variables cruzadas, por ejemplo, vemos que hay 662 diamantes con cortes buenos y del mejor color. Sin embargo, con esta tabla por si sola es difícil detectar si hay alguna relación entre variables.
Probemos otra cosa: primero, calculemos los totales por cada columna y fila.
ct1 = pd.crosstab(diamonds['cut'], diamonds['color'], margins=True, margins_name='Total')
ct1| color | D | E | F | G | H | I | J | Total |
|---|---|---|---|---|---|---|---|---|
| cut | ||||||||
| Fair | 163 | 224 | 312 | 313 | 303 | 175 | 119 | 1609 |
| Good | 662 | 933 | 907 | 871 | 702 | 522 | 307 | 4904 |
| Ideal | 2834 | 3902 | 3826 | 4883 | 3115 | 2093 | 896 | 21549 |
| Premium | 1602 | 2337 | 2331 | 2924 | 2358 | 1428 | 808 | 13788 |
| Very Good | 1513 | 2399 | 2164 | 2299 | 1823 | 1204 | 678 | 12080 |
| Total | 6774 | 9795 | 9540 | 11290 | 8301 | 5422 | 2808 | 53930 |
Ahora, dividamos cada columna por el Total para ver como varía la proporción de cada diamante entre los colores y el corte. Si las proporciones son más o menos las mismas, podemos inferir de que no hay asociación entre estas variables. Esto significa que un diamante con buen corte, por ejemplo, no nos da información acerca de como será su color.
100 * ct1.div(ct1['Total'], axis=0).round(3)| color | D | E | F | G | H | I | J | Total |
|---|---|---|---|---|---|---|---|---|
| cut | ||||||||
| Fair | 10.1 | 13.9 | 19.4 | 19.5 | 18.8 | 10.9 | 7.4 | 100.0 |
| Good | 13.5 | 19.0 | 18.5 | 17.8 | 14.3 | 10.6 | 6.3 | 100.0 |
| Ideal | 13.2 | 18.1 | 17.8 | 22.7 | 14.5 | 9.7 | 4.2 | 100.0 |
| Premium | 11.6 | 16.9 | 16.9 | 21.2 | 17.1 | 10.4 | 5.9 | 100.0 |
| Very Good | 12.5 | 19.9 | 17.9 | 19.0 | 15.1 | 10.0 | 5.6 | 100.0 |
| Total | 12.6 | 18.2 | 17.7 | 20.9 | 15.4 | 10.1 | 5.2 | 100.0 |
La multiplicación por 100 fue solo hecha con la intensión de que sea más fácil la lectura de los números en porcentaje. La fila del Total indica la proporción promedio de los diferentes colores independiente del corte, por ejemplo, vemos que 12,6% de los colores son D. Esto se conoce como frecuencia marginal.
Estas frecuencias marginales nos dan una base comparativa con las frecuencias observadas para cada categoria de corte y así ver si hay desvaciones largas desde su frecuencia marginal.
Podemos ver desviaciones naturales, pero nada que se desvie mucho del promedio, lo que nos dice, por ejemplo, que un diamante de corte ideal no nos da información acerca de su color. Lo mismo pasa con las demás categorías de corte, lo que implica que hay poca o no hay asociación entre estas dos variables. Veamos las demás variables categóricas.
ct2 = pd.crosstab(diamonds['cut'], diamonds['clarity'], margins=True, margins_name='Total')
100 * ct2.div(ct2['Total'], axis=0).round(3)| clarity | I1 | IF | SI1 | SI2 | VS1 | VS2 | VVS1 | VVS2 | Total |
|---|---|---|---|---|---|---|---|---|---|
| cut | |||||||||
| Fair | 13.1 | 0.6 | 25.4 | 29.0 | 10.5 | 16.2 | 1.1 | 4.3 | 100.0 |
| Good | 2.0 | 1.4 | 31.8 | 22.0 | 13.2 | 19.9 | 3.8 | 5.8 | 100.0 |
| Ideal | 0.7 | 5.6 | 19.9 | 12.1 | 16.7 | 23.5 | 9.5 | 12.1 | 100.0 |
| Premium | 1.5 | 1.7 | 25.9 | 21.4 | 14.4 | 24.3 | 4.5 | 6.3 | 100.0 |
| Very Good | 0.7 | 2.2 | 26.8 | 17.4 | 14.7 | 21.4 | 6.5 | 10.2 | 100.0 |
| Total | 1.4 | 3.3 | 24.2 | 17.0 | 15.1 | 22.7 | 6.8 | 9.4 | 100.0 |
Aqui si vemos desvios importantes entre el corte y la frecuencia marginal de la claridad. Por ejemplo, para los cortes que son muy buenos, vemos más observaciones en la claridad a medida que vamos mejorando la calidad de esta misma, excepto por I1 que hay pocas observaciones quizás porque es dificil de llegar a esa calidad suprema de claridad. Veamos ahora que ocurre con las variables categóricas de claridad y color.
ct3 = pd.crosstab(diamonds['clarity'], diamonds['color'], margins=True, margins_name='Total')
100 * ct3.div(ct3['Total'], axis=0).round(3)| color | D | E | F | G | H | I | J | Total |
|---|---|---|---|---|---|---|---|---|
| clarity | ||||||||
| I1 | 5.7 | 13.8 | 19.3 | 20.2 | 21.9 | 12.4 | 6.7 | 100.0 |
| IF | 4.1 | 8.8 | 21.5 | 38.0 | 16.7 | 8.0 | 2.8 | 100.0 |
| SI1 | 15.9 | 18.6 | 16.3 | 15.1 | 17.4 | 10.9 | 5.7 | 100.0 |
| SI2 | 14.9 | 18.6 | 17.5 | 16.8 | 17.0 | 9.9 | 5.2 | 100.0 |
| VS1 | 8.6 | 15.7 | 16.7 | 26.3 | 14.3 | 11.8 | 6.6 | 100.0 |
| VS2 | 13.8 | 20.2 | 18.0 | 19.1 | 13.4 | 9.5 | 6.0 | 100.0 |
| VVS1 | 6.9 | 18.0 | 20.1 | 27.3 | 16.0 | 9.7 | 2.0 | 100.0 |
| VVS2 | 10.9 | 19.6 | 19.2 | 28.5 | 12.0 | 7.2 | 2.6 | 100.0 |
| Total | 12.6 | 18.2 | 17.7 | 20.9 | 15.4 | 10.1 | 5.2 | 100.0 |
En algunos colores la variación con respeto a la frecuencia marginal no es mucha, como por ejemplo, para el color E, F, H, I, J. Para los colores D y G se observa mayor variación, pero nada como para determinar una relación entre las variables de color y claridad.
Gráfico de barras
Puede resultar útil visualizar la cantidad proporcional entre dos categorías utilizando un gráfico de barras. Como vimos con las tablas cruzadas, hay algunas variaciones y podríamos tener una visión más clara viendolas en un gráfico que en una tabla.
basic_ct = pd.crosstab(diamonds['cut'], diamonds['color'])
basic_ct.plot(kind='bar')
Podemos hacer otro tipo de gráfico para ver el número de observaciones por cada categoría de cut, junto con la composición de los diferentes colores. Este tipo de gráfico que se presenta a continuación se llama gráfico de barras apiladas
basic_ct.plot(kind='bar', stacked=True)
Quizás para este caso, este tipo de gráfico no nos sea de mucha utilidad, dado que tenemos muchas categorías de colores. En otras ocasiones podría sernos de mayor utilidad.
Finalmente, veamos un gráfico de barras normalizado que es útil para comparar proporciones de colores, ignorando los números de diamantes en cada categoría de corte.
ct1.div(ct1['Total'], axis=0).iloc[:, :-1].plot(kind='bar', stacked=True)
Como podemos ver, cada barra se ve más o menos parecida indicando que entre las variables de corte y de colores, no hay variaciones significativas. Veamos ahora las otras dos parejas para ver como se comportan.
ct2.div(ct2['Total'], axis=0).iloc[:, :-1].plot(kind='bar', stacked=True)
Aqui podemos ver mayor variación, como habiamos mencionado anteriormente, en especial en la claridad SI2 y VS2. Al ver mayor variación, podriamos desarrollar la hipótesis que la claridad si nos puede brindar información acerca del color.
ct3.div(ct3['Total'], axis=0).iloc[:, :-1].plot(kind='bar', stacked=True)
Para este caso, vemos mayores variaciones que el color y el corte, pero no significativamente mayor. Aún vemos que las proporciones son parecidas entre el color y la claridad, lo que significa que la claridad no nos brindaría información acerca del color, o en otras palabras, podríamos desarrollar la hipótesis de que estas variables no están relacionadas entre sí.
Una variable categórica y una variable numérica
Una de las visualizaciones estándares que se utilizan cuando tenemos una variable numérica y la otra categórica es el diagrama de caja o diagrama de bigote (boxplot) para comparar los efectos que tiene la media/mediana de variables numéricas en variables categóricas o viceversa.
Un boxplot es un gráfico que muestra mucha información sobre una variable: los tres cuartiles (Q1, Mediana y Q3) están representados como una caja y los extremos mínimos y máximos están representados con una línea o bigote. Para más información, dar clic aquí.
A continuación un ejemplo de un boxplot.
sns.boxplot(x='y', data=diamonds)
Vamos a definir algunos conceptos importantes para entender un boxplot:
- Primer cuartil: Es el primer 25% de los datos. Es el costado izquierdo de la caja azul.
- Mediana o segundo cuartil: Es el 50% de los datos. Es la linea negra dentro de la caja azul.
- Tercer cuartil: Es el 75% de los datos. Es el costado derecho de la caja azul.
- Rango intercuartílico: Es la distancia de la caja azul, es decir, el tercer cuartil menos el primer cuartil.
- Barrera: Son las lineas verticales que están los extremos. La barrera superior es el tercer cuartil + 1,5 veces el rango intercuartílico y la barrera inferior es el primer cuartil - 1,5 veces el rango intercuartílico.
- Valores atípicos: Son aquellos puntos que están más allá de las barreras.
Considerar que los valores identificados en el boxplot como atípicos (outliers) son solo candidatos para ser atípicos. De hecho, el concepto de valores atipicos no está bien definido, dado que depende del contexto y de la distribución de las variables.
Si bien, los boxplot son utilizados para análisis de univariables, son mucho más utiles para análisis bivariables, porque ofrecen una manera simple de comparar distribuciones entre distintas variables categóricas. Veamos que sucede entre el corte del diamante y su precio.
sns.boxplot(x='cut', y='price', data=diamonds)
Los boxplots se ven más o menos similares. Como la medida de la caja es una medida de spread, podemos ver que hay mayor variación de precio en la categoría premium. Se presenta también muchos valores atípicos en todas las categorias, pero esto es en escencia por la distribución de los precios. Enfoquemonos por ahora solo en los diamantes que cuestan más de 10.000 dólares.
sns.boxplot(x='cut', y='price', data=diamonds.loc[diamonds['price'] < 10000])
Aqui podemos ver dos cosas claramente:
- La distribución del precio entre premium, good y very good son muy similares.
- La mayor diferencia entre la distribución de los precios se ve en las categorías fair e ideal. Para los diamantes con corte fair más de la mitad cuesta menos de USD 2.000, mientras que fair solo un 25% de los diamantes cuesta menos que USD 2.000.
Podemos concluir que defintivamente hay una relación entre los diferentes cortes y la distribución de precios.
Ahora, sabiendo que los precios tienen una distribución sesgada, veamos que tan diferentes son las medianas de los precios en cada categoría.
diamonds.groupby('cut')['price'].agg(np.median).sort_values()cut Ideal 1810 Very Good 2648 Good 3054 Premium 3183 Fair 3282 Name: price, dtype: int64
Efectivamente las medianas son muy distintas, en especial para las variables de ideal y fair. Realicemos el mismo ejercicio para la categoría clarity y utilizando las medianas en orden, graficaremos un boxplot para que podamos ver mejor las diferencias de la distribución del precio para cada categoría.
medians_by_clarity = diamonds.groupby('clarity')['price'].agg(np.median).sort_values()
print(medians_by_clarity)clarity IF 1080.0 VVS1 1092.5 VVS2 1311.0 VS1 2005.0 VS2 2053.0 SI1 2822.0 I1 3344.0 SI2 4072.0 Name: price, dtype: float64
sns.boxplot(x='clarity', y='price', data=diamonds.loc[diamonds['price']<10000], order=medians_by_clarity.index)
Aqui vemos una relación muy clara: Hay una mayor concentración de precio (menor distribución o varianza) en los cortes de menor calidad y mayor distribución en los mejores cortes. Además que el precio de los mejores cortes tiene una mediana mayor a los de peor corte. Esto quiere decir que la variable corte si tiene una influencia significativa en el precio.
Por último, veamos la relación entre el precio y el color.
medians_by_color = diamonds.groupby('color')['price'].agg(np.median).sort_values()
sns.boxplot(x='color', y='price', data=diamonds.loc[diamonds['price']<10000], order=medians_by_color.index)
Vemos que, al igual que el corte y precio, podemos ver dos grupos distintos que son parecidos entre si:
- Los colores E, D, G y F tienen precios muy similares. Ocurre lo mismo con los colores H, I y J solo que este último se encuentra un poco más alto.
- Vemos que los peores colores tienen más concentración en los precios, es decir, precios con menor distribución que los mejores colores.
En conclusión podemos decir que si hay influencia del color sobre el precio de un diamante.
EDA Multivariado
Una exploración multivariable explora más de dos variables. Al igual que los otros tipos de exploración, hay formas comunes de trabajar con multivariables, como por ejemplo:
- Colorear un scatterplot para representar una variable categórica.
- Utilizar otra variable categórica en los boxplot
- Utilizar gráficos de celosía para dividir el análisis en diferentes categorías
- Gráficos paralelos.
- Mapas de calor (heatmaps)
Cuarta parte: Implementación de modelos
Machine Learning es la tecnología utilizada para crear proyectos predictivos. Puede definirse como un subcampo de la ciencia de la computación y es el área de la inteligencia artifial que estudia los métodos para utilizar datos y entregar la habilidad al computador de aprender de esos datos y realizar tareas sin programarlo explicitamente. Tipicamente ML está dividida en tres grandes áreas:
1) Aprendizaje supervisado: Es cuando el computador tiene algunos inputs asociados a un output y el sistema aprende como esos inputs producen tal output. Eso quiere decir que tenemos que definir tanto el input como el output.
2) Aprendizaje no supervisado: En este caso, no hay señal de guia para que el sistema pueda aprender. Este tipo de aprendizaje están generalmente enfocados en aprender algún tipo de estructura en la data, es decir, descubrir patrones ocultos en los datos. Algunas aplicaciones para este tipo de aprendizaje son los clustering, reducción de dimensionalidad, sistemas de recomendación, etc.
3) Aprendizaje por refuerzo: En este tipo de tareas, el aprendizaje ocurre como consecuencia de un sistema de computación que en este contexto es llamado "agente" que interactua con el ambiente. Los feedback que el sistema recibe son frecuentemente dados en la forma de castigo o recompensa. Las aplicaciones que se utilizan para este tipo de aprendizaje incluyen autos autónomos, robótica, algoritmos de trading y mucho más.
Para predecir el precio del diamante utilizaremos un aprendizaje supervisado, dado que tenemos los inputs y definimos el output, que es el precio. En un aprendizaje supervisado tenemos dos tipos de tareas:
- Regresión: Es utilizada cuando la variable objetivo es numérica. Por ejemplo, predecir el precio de casas, número de personas realizando clic en un anuncio, proporción de crimenes, precios de acciones, etc.
- Clasificación: Es utilizada cuando la variable objetivo es categórica. Ejemplos de clasificación está en todas partes: Si un cliente compra o no, si un paciente está sano o no, etc. Hay principalmente tres tipos de problemas de clasificación:
- Clasificación binaria: La variable objetivo tiene solo dos categorías.
- Clasificación multiclase: La variable objetivo tiene más de dos categorías.
- Clasificación multietiqueta: El problema de asignar más de una categoría o etiqueta a una observación, por ejemplo, predecir el topico de un nuevo articulo basado en su contenido. Muchos articulos no caen en una sola categoría, porque un articulo puede ser simultaneamente acerca de noticias mundiales, politica y finanzas.
Técnicamente, un modelo de ML es una combinación de dos cosas:
1) Conjunto de hipótesis: Es una propuesta de como vamos a representar la conexión entre los valores de los atributos para producir los valores del vector objetivo. Es una función matemática que muestra la relación entre los inputs y el output.
2) Algoritmo de aprendizaje: Es un procedimiento que utiliza los datos para seleccionar un elemento de un conjunto de hipótesis. El elemento seleccionado es lo que las personas llaman un modelo. Entrenar un modelo significa usar el algoritmo de aprendizaje para seleccionar el modelo de un conjunto de hipótesis.
Conjunto de hipótesis
La propuesta de la relación entre los atributos y el vector objetivo será la siguiente para la data de diamantes.
price = w x carat donde w es cualquier número positivo.
Este modelo básicamente predice el precio multiplicando w por el valor de carat. Por ejemplo:
- price = 3 * carat
- price = 658.1 * carat
- price = 2535 * catat
Como w puede tomar cualquier valor, tenemos infinitos elementos en nuestro conjunto de hipótesis. ¿Como seleccionamos solo un elemento?
Algoritmo de aprendizaje
Para obtener un valor w de las infinitas posibilidades, dividiremos el precio por el carat correspondiente y promediaremos el resultado. Implementando este simple algoritmo es lo que nosotros llamaremos entrenar el modelo.
w = np.mean(diamonds['price']/diamonds['carat'])
w4008.0243030179727
Ya tenemos entonces el valor de nuestro w para utilizarlo en nuestro modelo propuesto, es decir, el modelo está dado por precio = 4008.024 carat. Ahora podremos usarlo para realizar predicciones de precio.
def first_ml_model(carat):
return 4008.024 * caratcarat_values = np.arange(0.5, 5.5, 0.5)
preds = first_ml_model(carat_values)
pd.DataFrame({'Carat':carat_values, 'Predicted price':preds})| Carat | Predicted price | |
|---|---|---|
| 0 | 0.5 | 2004.012 |
| 1 | 1.0 | 4008.024 |
| 2 | 1.5 | 6012.036 |
| 3 | 2.0 | 8016.048 |
| 4 | 2.5 | 10020.060 |
| 5 | 3.0 | 12024.072 |
| 6 | 3.5 | 14028.084 |
| 7 | 4.0 | 16032.096 |
| 8 | 4.5 | 18036.108 |
| 9 | 5.0 | 20040.120 |
Recordar que el proceso de análisis predictivo es utilizar métodos cuantitativos que utilizan los datos con el fin de realizar predicciones. Esto fue exactamente lo que hicimos, aunque solo fue una aproximación para hacer entender como es un modelo, porque en realidad el modelo que hicimos es horrible para predecir los precios de diamantes. Los modelos formalmente utilizados en ML llevan decadas de investigación y tienen un nivel de complejidad bastante alto, en contraste con el modelo que construimos. Muchos de estos modelos formales se encuentran ya implementados en una librería llamada scikit-learn.
Objetivos de un modelo ML
En el análisis predictivo, lo que nos gustaría hacer es predecir eventos desconocidos. Cuando utilizamos ML lo que hacemos es utilizar los datos y descubrir como las variables están relacionadas al vector objetivo. De hecho, eso es lo que los modelos ML intentan descubrir: suponemos que hay una función desconocida que toma las variables y realiza ciertos calculos para intentar imitar en lo posible el valor del vector objetivo. Si ya conocemos la función no tiene ningún sentido usar un modelo.
Una vez de que tengamos una función, podremos ingresar nuevos diamantes que estén fuera de los datos utilizados y podremos llegar a su precio aproximado.
Una vez que tengamos listo el modelo, sería poco productivo esperar a que nos llegue un diamante para ver qué precio predice nuestro modelo y luego esperar a que sea vendido de tal manera de descubrir que tan buena fue nuestra predicción. Lo que queremos hacer es simular esa situación: necesitamos dividir las partes para que uno haga el trabajo de descubrir la función matemática para llegar al precio (el modelo) y la otra pueda descubrir si los resultados nos permiten realizar buenos negocios (vendedor). La forma de simular este escenario es a través del cross-validation que es un método para dividir un dataset en diferentes subsets con el fin de dar una mejor estimación de como el modelo va a generar los datos fuera de la muestra. La forma más simple de un cross-validation es el método hold-out que consiste en dividir nuestros datos en dos muestras: entrenamiento (buscar la función) y el test (probar el modelo).
- Conjunto de entrenamiento: Aquí es donde ocurre el aprendizaje, donde intentamos llegar a una función matemática que pueda predecir correctamente el vector objetivo
- Conjunto de test: Aquí es donde ocurre la evaluación del modelo ya entrenado. Estos datos se prueban como si fuesen datos nuevos que están fuera del contexto del entrenamiento, es decir, los algoritmos de entrenamiento no vieron estos datos. Qué tan bien el modelo pudo predecir los precios en el conjunto de test es un indicador de qué tan bien lo hará con nuevos datos, que tan generalizado está el aprendizaje.
Sobreajuste (overfitting)
Muy conectado con el objetivo de que nuestro modelo sea generalizado, tenemos el concepto de overfitting. Esto es una situación donde el modelo se adapta tan bien al conjunto de entrenamiento que empieza a aprender del ruido que no está relacionado con la verdadera relación entre las variables y el vector objetivo. Hay distintos tipos de ajustes y estos son:
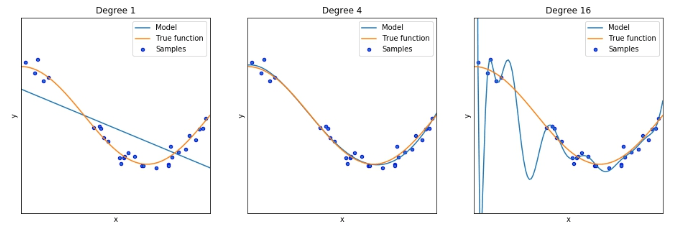
- Underfitting: Ilustrado en el lado izquierdo de la imagen, el underfitting es cuando intentamos utilizar un modelo muy simple para el problema, por ejemplo, un modelo lineal para capturar una relación o función no lineal entre una variable independiente y dependiente. Esta aproximación no permitirá predecir nuevas observaciones de manera precisa.
- Buen aprendizaje: Esta es la situación perfecta. Es cuando nuestro modelo tiene el mismo nivel de complejidad que el problema y da como resultado una buena aproximación a la verdadera función. Por ejemplo, en la imagen del centro el modelo para un polinomio con 4 grados lo hará muy bien.
- Overfitting: En esta situación implementamos un modelo muy complejo cuando el modelo no necesitaba tanta complejidad para ser resuelto (no matas a una mosca con una bazuca). Esto afecta la habilidad de aproximar bien la verdadera función y tendremos problemas con la generalidad de nuestro modelo, vale decir, que actue bien con nuevas observaciones. El principal síntoma del overfitting es que el rendimiento del modelo en el conjunto de entrenamiento es muy bueno, pero el rendimiento en el conjunto de testing es malo.
La regularización es una serie de técnicas que nos permitirán evitar el overfitting. Algunos modelos, como la regresión lasso o la regresión ridge son definidos como elementos regularizadores que intentarán evitar el overfitting.
Evaluación de la función y optimización
Todos los modelos ML tienen una función de evaluación que básicamente es una función matemática que asigna un número a cada elemento del conjunto de hipótesis. Esto con el fin de evaluar qué tan bueno es el modelo en predecir la variable objetivo. Esta función por tanto es usada para distinguir entre los buenos modelos y los malos modelos y además otorga información para buscar buenos modelos. La búsqueda de un buen modelo dentro del conjunto de hipótesis es usualmente realizado con la ayuda de técnicas de optimización.
Una buena técnica de optimización es vital para un eficiente aprendizaje del algoritmo. Por ejemplo, el algoritmo de aprendizaje puede escoger el modelo que minimize la función de evaluación. Nuestro primer modelo, sin embargo, no cuenta con una función de evaluación y una técnica de optimización.
Para tener estas variables en cuenta
Para tener en consideración todo lo anterior, utilizaremos una librería llamada scikit-learn. Esta librería es más que una librería para construir modelos ML. Es más bien un kit con un montón de herramientas útiles para la tarea de construir un modelo. Además de la implementación de los más variados y usados algoritmos de ML, ofrece herramientas para tareas relacionadas, como:
- Selección de modelos.
- Evaluación de modelos.
- Transformación de Datasets.
- Descarga de utilidades para los datasets.
Transformaciones
Recordar que diferentes modelos pueden verse afectados en diferentes maneras dependiente de como le entregamos la data al modelo. Las transformaciones son vitales en ese sentido. Las tranformaciones como suavizar la asimetría de los predictores u ocuparse de los datos atípicos pueden ser muy beneficios para que el modelo pueda aprender. Para obtener la data lista para el modelo hay dos aproximaciones:
- Preprocesamiento no supervisado involucra técnicas que no consideran al vector objetivo.
- Preprocesamiento supervisado que involucra técnicas que sí consideran al vector objetivo.
Algo importante a considerar es que scikit-learn no acepta variables categóricas. Dado que todo el cálculo para encontrar el mejor modelo es puramente matemático no podemos trabajar sin números. Esto es otra buena razón para utilizar one-hot encoding para no dejar atrás las variables categóricas que nos pueden brindar información muy importante para el modelo. Como la información de variables categóricas ya está realizada en nuevas columnas one-hot encoding, las columnas originales no serán incluidas al modelo.
Dejaremos una matriz llamada "x" para las variables input e "y" para la variable output o variable objetivo.
X = diamonds.drop(['cut', 'color', 'clarity', 'price'], axis=1)
y = diamonds['price']Train-Test Split
Esta etapa no es exactactamente una transformación de datos, pero es lo primero que debemos hacer antes de modelar. Aqui separaremos los datos en un conjunto de entrenamiento y de test. Recordar que el conjunto de test es como si fueran datos nuevos que están fuera de los datos de entrenamiento, por lo tanto cualquier transformación que hagamos antes de entrenar el modelo debe ser realizado al conjunto de entrenamiento y no al conjunto de test. Esta es la razón por la que debemos separar primero los datos.
La separación comunmente se hace con un 80% al conjunto de entrenamiento y 20% al conjunto de test. Esta participación más bien es como un hábito y tiene sentido cuando tenemos muestras pequeñas (menos de 1.000 observaciones) con el fin de tener datos suficientes para que el algoritmo aprenda. Sin embargo, si tenemos un dataset muy grande, es mejor pensar cuánto podría ser la mejor partición.
Entre más datos tenemos para entrenar, mejor. De hecho, algoritmos simples con muchos datos funcionan mejor que los algoritmos complejos con pocos datos, por lo que es importante mantener la mayor cantidad de datos que podamos en el conjunto de entrenamiento. Si por ejemplo, tenemos 5 millones de observaciones, no necesitamos el 20% para evaluarlo, porque un millón de observaciones es demasiado. En este caso, tener 1-2% en el conjunto de test tiene mucho más sentido.
Para el caso de este ejercicio, utilizaremos una separación de 90-10.
# importamos las librerías que necesitamos para esta cuarta parte.
from sklearn.model_selection import train_test_split# separamos la data en conjunto de entrenamiento y de test.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.1, random_state=123)Internamente, la función train_test_split realiza la repartición de datos de manera aleatoria. Con random_state podemos generar una repartición aleatoria que nos da las mismas observaciones para cada conjunto cada vez que ejecutamos la línea anterior.
Reducción de la dimensionalidad con PCA
La reducción de la dimensionalidad es un procedimiento que toma una lista de variables y las reduce. El fin de esto es preservar la mayor cantidad de información de la base original, pero quitando aquellas variables que producen colinealidad, como vimos con las variables x, y, z (escencialmente tienen la misma información). Extraemos más información, pero nos quedamos con la más importante para poder predecir el vector objetivo. Si le pasamos muchas variables al modelo, el rendimiento no suele ser tan buenos.
La técnica de reducción de dimensionalidad más popular es el análisis de componentes principales o PCA (principal component analysis). Este algoritmo utiliza el algebra lineal para transformar las variables originales a otro set de variables que están linealmente correlacionadas, lo que es llamado componentes principales (PC). El primer PC es el que captura la mayor información de todas las variables, el segundo PC captura la mayor información faltante después de considerar el primer PC, el tercer PC captura la mayor información faltante después de considerar el primer y segundo PC y así consecutivamente. Debemos decidir cuántos de estos PC utilizaremos para reducir la dimensionalidad del dataset original.
Antes de implementar esta reducción, denemos de introducir el concepto de transformadores (transformers en inglés) que son clases de scikit-learn para realizar preparaciones de datos. Para usar transformadores siempre debemos seguir estos pasos: 1) Importar la clase que vamos a utilizar. 2) Crear una instancia de la clase aplicando parámetros adicionales. 3) Utilizar el método fit en la instancia. Este método ejecutará los cálculos internos necesarios para el siguiente paso. 4) Utilizar el método transform para realizar las transformaciones.
La clase PCA es un transformador, por lo que apliquemos los pasos anteriores en código.
# Importar la clase que vamos a utilizar.
from sklearn.decomposition import PCA
# Crear una instancia de la clase.
pca = PCA(n_components=3, random_state=123)
# Utilizar el método fit en la instancia.
pca.fit(X_train[['x', 'y', 'z']])
# Utilizar el método transform para realizar las transformaciones.
princ_comp = pca.transform(X_train[['x', 'y', 'z']])Utilizando este método, podemos verificar, en términos de proporción, cuánta varianza (o información) es capturada en cada uno de los componentes producidos.
pca.explained_variance_ratio_.round(3)array([0.997, 0.002, 0.001])
99,7% de la varianza de los tres componentes originales es capturada por el primer componente principal, del resto, es capturado mayoritariamente por el segundo componente y el tercero no se lleva casi nada. Dado esos resultados, es buena idea preservar solo el primer PC. Antes de producir esta nueva variable, veamos como los tres principales componentes están en realidad no correlacionados entre sí.
princ_comp = pd.DataFrame(data=princ_comp, columns=['pc1', 'pc2', 'pc3'])
sns.pairplot(princ_comp, plot_kws={'s':3})
princ_comp.corr().round(4)| pc1 | pc2 | pc3 | |
|---|---|---|---|
| pc1 | 1.0 | -0.0 | 0.0 |
| pc2 | -0.0 | 1.0 | 0.0 |
| pc3 | 0.0 | 0.0 | 1.0 |
Como vemos, todas las correlaciones son 0, es decir, no hay absolutamente ninguna relación entre ellas. Como sabemos que vamos a preservar solo el primer componente, ejecutemos el mismo código, pero utilizamos n_components=1. Luego, añadiremos esta nueva variable en el dataset y eliminaremos las variables x, y, z.
# Obtenemos solo el primer componente principal
pca = PCA(n_components=1, random_state=123)
# Entrenamos el transformador pca
pca.fit(X_train.loc[:, ['x', 'y', 'z']])
# Añadimos la nueva variable al dataset
X_train['dim_index'] = pca.transform(X_train.loc[:, ['x', 'y', 'z']]).flatten()
# Eliminamos las variables x, y, z
X_train.drop(['x', 'y', 'z'], axis=1, inplace=True)Con esto pudimos reducir las tres variables x, y, z en una sola. Ahora estamos listos para el siguiente paso.
Unidad tipificada y ajuste
La estandarización es quizás la forma más común de transformación para preparar los datos al modelo. Aunque, muchos algoritmos pueden aprender igual de bien sin aplicar esta transformación, mejorará la estabilidad numérica y la velocidad de ejecución para la mayor parte de los algoritmos, y muchos de ellos, como KNN, requieren este paso para agregar respuestas sensibles. Hay distintas formas de realizar esta estandarización y una de ellas involucra a scikit-learn.
Por cada valor numérica substraemos el promedio (el nuevo promedio es cero) y dividimos cada valor por su desviación estándar. Después de eso, todas las variables tendrán un promedio de cero y una desviación estándar o varianza de 1, por lo que los datos estarán en la misma escala.
numerical_features = ['carat', 'depth', 'table', 'dim_index']
# Importamos la clase que utilizaremos
from sklearn.preprocessing import StandardScaler
# Creamos una instancia de la clase
scaler = StandardScaler()
# Utilizamos un método fit para la instancia
scaler.fit(X_train[numerical_features])
# Usamos el método transform para realizar la transformación
X_train.loc[:, numerical_features] = scaler.transform(X_train[numerical_features])X_train[numerical_features].head()| carat | depth | table | dim_index | |
|---|---|---|---|---|
| 30067 | -0.840293 | 1.429309 | -0.205642 | -0.918737 |
| 17609 | 0.677534 | 0.383359 | -2.001069 | 0.848778 |
| 42509 | -0.629484 | 0.034709 | -0.205642 | -0.568903 |
| 22843 | 0.719696 | -0.662591 | 0.243215 | 0.908909 |
| 25958 | 2.553737 | -1.987460 | 2.487499 | 2.147705 |
En este output vemos como las variables numéricas están estandarizadas, es decir, a la misma escala.
Finalmente, ejecutando la siguiente línea de código, podemos rapidamente notar que el promedio y la desviación estándar son practicamente 0 y 1, respectivamente.
X_train[numerical_features].describe().round(4)| carat | depth | table | dim_index | |
|---|---|---|---|---|
| count | 48537.0000 | 48537.0000 | 48537.0000 | 48537.0000 |
| mean | -0.0000 | -0.0000 | -0.0000 | 0.0000 |
| std | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| min | -1.2619 | -13.0745 | -6.4896 | -1.8152 |
| 25% | -0.8403 | -0.5231 | -0.6545 | -0.9077 |
| 50% | -0.2079 | 0.0347 | -0.2056 | -0.0236 |
| 75% | 0.5089 | 0.5228 | 0.6921 | 0.7114 |
| max | 8.8780 | 12.0283 | 9.6692 | 4.4959 |
A partir de este punto es importante no realizar nuevas transformaciones, porque de lo contrario, las variables no estarán estandarizadas. Es por esto que esta debe ser nuestra última transformación antes de comenzar con la implementación del modelo.
Modelos de regresión
En scikit-learn los modelos ML son implementados en clases conocidos como estimadores, donde incluyen objetos que aprender de los datos, principalmente modelos y transformadores. Todos los estimadores tienen un método fit que es utilizado para entrenar el estimador de la siguiente manera: estimador.fit(data).
Es importante considerar que el estimador tiene dos tipos de parámetros:
Parámetros del estimador: Todos los parámetros de un estimador pueden ser establecidos en una instancia. Algunos de estos parámetros corresponden a hiperparámetros.
Parámetros estimados: Cuando la data es "equipada" a un estimador, los parámetros son estimados desde los datos a mano. Todos los parámetros son atributos del objeto estimado y se reflejan terminando con un guión bajo.
Como sckikit-learn tiene un API muy consistente utilizando estimadores, es muy similar a usar transformaciones. Para usar estimadores siempre se siguien los siguientes cuatro pasos:
1) Importar la clase del estimador que usaremos.
2) Creamos una instancia de la clase. Aquí podremos incorporar algunos parámetros adicionales, algunos de ellos como hiperparámetros.
3) Usar el método fit de la instancia para entrenar el modelo.
4) Usar el método predit para obtener predicciones.
Regresión Líneal
Implementaremos primero un modelo de regresión lineal, siendo el modelo más simple de entender. Para este modelo lo que realiza el algoritmo de aprendizaje (llamado OLS o ordinary least squares) es identificar la mejor combinación de linealidad entre dos variables para que la suma residual de cuadrados (RSS) sea minima.
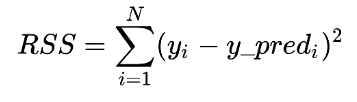
N es el número de puntos en el conjunto de entrenamineto, y_pred son los valores predichos e "y" representa el valor actual del vector objetivo. El algoritmo hace que el RSS sea el mínimo posible. Ahora si realizaremos la aplicación de una regresión lineal utilizando scikit-learn.
# Importamos las clases del estimador que usaremos.
from sklearn.linear_model import LinearRegression
# Creamos una instancia de la clase.
ml_reg = LinearRegression()
# Utilizaremos el método fit() en la instancia.
ml_reg.fit(X_train, y_train)
# Utilizaremos el método predict() para obtener las predicciones
y_pred_ml_reg = ml_reg.predict(X_train)El modelo ya fue entrenado en el conjunto de entrenamiento y las predicciones del conjunto de test han sido calculadas. Miremos primero como quedaron los coeficientes de la función lineal.
Recordar que la estructura básica de una regresión lineal es y = coeficiente*X +- constante
pd.Series(ml_reg.coef_, index=X_train.columns).sort_values(ascending=False).round(2)carat 5421.98 clarity_IF 5385.94 clarity_VVS1 5041.23 clarity_VVS2 4994.61 clarity_VS1 4617.94 clarity_VS2 4304.01 clarity_SI1 3705.83 clarity_SI2 2741.17 cut_Ideal 856.14 cut_Premium 756.61 cut_Very Good 756.06 cut_Good 609.45 table -59.00 depth -80.62 color_E -217.07 color_F -276.78 color_G -489.77 color_H -991.08 dim_index -1235.17 color_I -1480.43 color_J -2384.28 dtype: float64
Estos números son los coeficientes que se multiplican por cada variable en nuestro modelo. El hecho de que las variables estén en la misma escala, podemos interpretar los coeficientes como medida de variable de importancia. Por ejemplo, carat y clarity se ven como las variables que tienen una mayor influencia sobre el precio. El signo del coeficiente nos dice algo acerca de la dirección en la relación entre la variable y el precio: un signo positivo es un impacto positivo en el precio y un signo negativo es un impacto negativo.
El resultado e interpretación que estamos haciendo solo tiene sentido bajo el modelo que estamos implementando y bajo las variables que usamos. Si quitamos una variable obtendremos coeficientes diferentes.
from sklearn.base import clone
ml_reg1 = clone(ml_reg)
ml_reg1.fit(X_train.drop('carat', axis=1), y_train)
pd.Series(ml_reg1.coef_, index=X_train.drop('carat', axis=1).columns).sort_values(ascending=False).round(2)clarity_IF 5145.24 clarity_VVS1 4787.16 clarity_VVS2 4595.47 dim_index 4037.23 clarity_VS1 4002.79 clarity_VS2 3707.79 clarity_SI1 2972.60 clarity_SI2 2207.40 cut_Premium 935.20 cut_Ideal 923.39 cut_Very Good 812.14 cut_Good 608.70 depth 136.87 table -6.30 color_E -212.56 color_F -361.50 color_G -503.15 color_H -814.71 color_I -1112.21 color_J -1876.54 dtype: float64
Como podemos ver, el cambio más notorio es con _dimindex donde su coeficiente fue de positivo a negativo. Lo que ocurre aqui es que carat es extrechamente ligado a dim_index y cuando los dos están juntos en el modelo, la mejor forma que tiene el algoritmo de usar la información contenido en ambas variables fue asignar un coeficiente alto en carat y un pequeño coeficiente negativo en dim_index. Cuando carat es eliminado, la mejor forma de usar la información contenida dentro de dim_index fue asignarle un alto coeficiente positivo.
Ahora es tiempo de examinar qué tan bien le fue al modelo con las predicciones. Para esto, necesitamos una métrica, es decir, una función que tomará los valores predichos y los comparará con los verdaderos valores dentro del conjunto de test. La métrica más utilizada para este fin en los modelos de regresión es probablemente el error cuadrático medio (MSE en inglés).
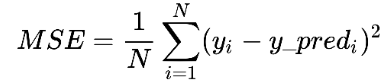
El MSE es el promedio de la diferencia al cuadrado entre el valor real y el predicho. Entre menor valor es el MSE, mejor es el modelo. A continuación evaluemos como nos fue.
from sklearn.metrics import mean_squared_error
mse_ml_reg = mean_squared_error(y_true=y_train, y_pred=y_pred_ml_reg)
print('{:0.2f} M'.format(mse_ml_reg/1e6))1.28 M
El resultado son 1.28 millones, pero ¿es este número grande o chico? Necesitamos un punto de referencia para poder compararlo. Para obtener este punto de referencia, tratemos de resolver la siguiente pregunta: En la ausencia de cualquier información acerca de las caracteristicas de los diamantes, ¿cuál sería tu mejor conjetura del precio?. La conjetura que minimiza el MSE es conjeturar el promedio. Prediciendo que todos los valores del vector objetivo son iguales al promedio es llamado el modelo nulo, un modelo sin predictores. El rendimiento de este modelo nulo es el primer punto de referencia que podemos usar para compararlo con el rendimiento del modelo. Calculemos entonces el MSE para un modelo nulo:
y_pred_null_model = np.full(y_train.shape, y_train.mean())
mse_null_model = mean_squared_error(y_true=y_train, y_pred=y_pred_null_model)
mse_null_model15923703.431632007
Notar que solo utilizamos los valores del conjunto de entrenamiento para obtener el promedio. Obtenemos un MSE de casi 16 millones por lo que, en ausencia de cualquier información, nuestra mejor conjetura (promedio) nos dará un MSE de 15.9 millones, mientras que nuestro modelo que utiliza información de las variables, nos da 1.28 millones. Ahora tenemos algo de perspectiva acerca de este número y podemos decir que al menos nuestro modelo funciona mucho mejor que si adivinaramos el promedio del precio, lo que es genial para nuestro primero modelo ML.
Regresión Lasso
Lasso es una modificación utilizada para multiples modelos de regresiones. Este algoritmo automáticamente excluye aquellas variables que aportan poco a la precisión (accuracy) del modelo. La ecuación que usa la regresión lasso para realizar predicciones es la misma que el caso de la regresión líneal: una combinación lineal de todas las variables, es decir, cada una de ellas multiplicadas por un coeficiente. La modificación es realizada por la cantidad que el algoritmo está intentando minimizar. Esto quiere decir que si tenemos un predictor P el problema es encontrar una combinación de coeficiente que minimizará la siguiente cantidad:
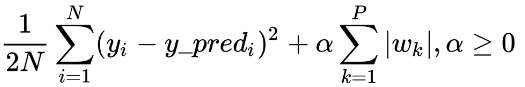
La primera parte de la formula es casi igual al MSE, salvo que lo multiplicamos por 1/2. El cambio clave es en el segundo termino, que es la sumatoria del valor absoluto entre los coeficientes multiplicados por un valor no-negativo que llamaremos alpha que vendría siendo el coeficiente de regularización.
La idea detrás de este modelo es que, añadiendo un "castigo" en el valor absoluto del coeficiente, el algoritmo de aprendizaje contrae algunos coeficientes para que su valor sea cero, por tanto, eliminando la variable correspondiente para que no sea considerada para la predicción. Para valores más largos de alpha, el modelo asignará ceros a más coeficientes y por tanto más variables quedarán fuera del modelo.
Este modelo es muy util cuando tenemos decenas o cientos de variables, pero nos interesa seleccionar solo algunas de ellas que si contribuyan a la predicción. Como en nuestro problema tenemos pocas variables, no es recomendable utilizar la regresión Lasso en este problema, pero veremos un ejemplo para saber como funciona:
# importamos la clase estimadora que utilizaremos
from sklearn.linear_model import Lasso
# Creamos una instancia de la clase.
lasso = Lasso(alpha=10)
# Utilizamos un método fit en la instancia
lasso.fit(X_train, y_train)
# Obtenemos las predicciones con el método predict
y_pred_lasso = lasso.predict(X_train)# Calcular el MSE
mse_lasso = mean_squared_error(y_true=y_train, y_pred=y_pred_lasso)
print('{:0.2f}M'.format(mse_lasso/1e6))1.52M
El modelo Lasso nos arrojó un MSE de 1,52 millones, lo que no es mejor que el modelo de regresión lineal que utilizamos anteriormente. Esto prueba de que este modelo no es conveniente para el problema que estamos enfrentando. Sin embargo, veamos los coeficientes que arroja este modelo de todas formas.
pd.Series(lasso.coef_, index=X_train.columns).sort_values(ascending=False).round(2)carat 4765.54 clarity_IF 1349.00 clarity_VVS2 1213.60 clarity_VVS1 1195.38 clarity_VS1 860.80 clarity_VS2 617.38 cut_Ideal 169.17 cut_Very Good 89.07 cut_Premium 55.09 clarity_SI1 34.43 cut_Good -0.00 color_F -0.00 color_E 0.00 table -103.96 color_G -124.86 depth -145.86 color_H -609.90 dim_index -707.77 clarity_SI2 -767.78 color_I -1001.45 color_J -1780.36 dtype: float64
Como podemos ver, tres variables tienen coeficiente cero. Las demás variables fueron las seleccionadas para el modelo. Como los ceros fueron establecidos para las variables dummy, podemos interpretar que el color (originalmente una variable categórica) donde la base categórica es D (la que no se muestra) y por el hecho de que los colores que tienen coeficientes cero son el F y E, nos dice que para este modelo, un diamante con esos colores es lo mismo a que si tuviesen el color D: básicamente no añaden o quitan ningún valor al precio. Por otro lado, el color J tiene un impacto negativo en el precio por 1.780 dólares en promedio.
KNN
El método KNN es utilizado tanto para problemas de regresión como de clasificación. Pertenece al grupo de los modelos no paramétricos, porque el predictor no está basado en el calculo de ningún parámetro. Aunque sea un modelo simple, produce muy buenos resultados incluso comparables con aquellos modelos más complejos. Su implementación más básica es fácil entender: Para un número fijo K, que es el número de vecinos y en una observación dada, el vector objetivo que queremos predecir hace lo siguiente:
- Encuentra los puntos K más cercanos entre sus valores de atributo y el punto dado.
- Calcula el promedio del vector objetivo para esos puntos K.
- Ese promedio calculado es la predicción para el punto dado.
Para entender como KNN funciona un poco mejor y porque tiene sentido, veamos como este procedimiento funciona con los diamantes. Digamos que K=12. Para predecir el valor de un diamante dado "d", haremos lo siguiente:
- Encontramos los 12 diamantes que son más similares a "d" en terminos de sus caracteristicas: carat, color, size, etc.
- Calculamos el promedio del precio donde estos 12 diamantes fueron vendidos.
- Este promedio es la predicción para nuestro diamante "d".
Este procedimiento tiene mucho sentido, dado que predice el precio de un diamante en base a diamantes que son similares al diamante seleccionado. Este procedimiento es un KNN en su forma más básica; hay muchas variaciones de este algoritmo, como por ejemplo utilizar distintas ponderaciones para calcular el promedio.
El KNN en la regresión utiliza un promedio simple, es decir, cada punto contribuye de igual manera para la predicción. En algunos casos conviene tener una ponderación como fijar una mayor contribución o ponderación a aquellos puntos más cercanos en comparación con los más lejanos. Para lograr esto, podemos utilizar el parámetro weight='uniform' para hacer una ponderación equitativa o weight='distance' para hacer una ponderación de acuerdo a su distancia.
La forma más común de medir la distancia entre dos puntos es utilizando la distancia de Minkowski que es también la más conocida y es la que utiliza scikit-learn por defecto.
# importamos la clase estimadora que utilizaremos
from sklearn.neighbors import KNeighborsRegressor
# Creamos una instancia de la clase.
knn = KNeighborsRegressor(n_neighbors=12)
# Utilizamos un método fit en la instancia
knn.fit(X_train, y_train)
# Obtenemos las predicciones con el método predict
y_pred_knn = knn.predict(X_train)# Calcular el MSE
mse_knn = mean_squared_error(y_true=y_train, y_pred=y_pred_knn)
print('{:0.2f}M'.format(mse_knn/1e6))0.67M
Obtenemos 0,67 millones que es mucho mejor que nuestros dos modelos anteriores. Pero OJO que hemos estado utilizando los mismos datos para entrenar y evaluar. Debemos usar X_test e y_text para evaluar.
Aunque KNN es un algoritmo fácil de entender y de usar, es una victima de un problema tecnico conocido como la maldición de la dimensionalidad, donde el modelo le cuesta aprender más a medida que aumentamos el número de variables. En este caso, tenemos pocas variables por lo que no tuvimos problemas al utilizarlo.
Entrenar vs testear
Ahora tenemos que poner atención en que el modelo no esté en estado "overfitting". Si tenemos buen rendimiento del modelo en el conjunto de entrenamiento, pero mal rendimiento en el conjunto de test podriamos estar ante un caso de overfitting. El modelo estaría bien ajustado si tanto para el conjunto de test como para el conjunto de entrenamiento nos da buenos resultados. En general se ven mejores rendimientos en el conjunto de entrenamiento que en el conjunto de test, porque estamos evaluando los datos con los mismos datos que usamos para realizar un modelo.
Es por ello que es al evaluar un modelo es util evaluar las métricas en el conjunto de entrenamiento, solo para ver que tan ajustado está nuestro modelo al compararlo con el conjunto de test. Sin embargo, debemos saber que no podemos confiar estos indicadores de rendimiento como reales. Veamos un ejemplo extremo.
perfect_knn = KNeighborsRegressor(n_neighbors=1)
perfect_knn.fit(X_train, y_train)
perfect_mse = mean_squared_error(y_true=y_train, y_pred=perfect_knn.predict(X_train))
print('{:0.2f}M'.format(perfect_mse/1e6))0.00M
Obtuvimos un MSE de 0. ¡Un rendimiento excelente!...
Bueno, no tan rápido. Utilizamos solo un vecino y evaluamos el modelo en el mismo conjunto de entrenamiento. Por esa razón nos da un rendimiento increíble. Es hora de evaluar este modelo en un conjunto de test como debe ser, pero antes, todas las transformaciones que realizamos en el conjunto de entrenamiento también las tenemos que hacer en el conjunto de test.
# reemplazamos x, y, z con dim_index utilizando PCA
X_test['dim_index'] = pca.transform(X_test[['x', 'y', 'z']]).flatten()
# Removemos x, y, z del dataset.
X_test.drop(['x', 'y', 'z'], axis=1, inplace=True)
# Escalamos los datos numéricos de tal manera que tengan promedio 0 y varianza 1.
X_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])Ahora que el conjunto de test ya fue transformado, estamos listos para utilizarlos para realizar predicciones y evaluar aquellas predicciones. Para ello crearemos un pequeño DataFrame y lo utilizaremos para almacenar distintos MSE para el conjunto de entrenamiento y de test.
mse = pd.DataFrame(columns=['train', 'test'], index=['MLR', 'Lasso', 'KNN'])
model_dict = {'MLR':ml_reg, 'Lasso': lasso, 'KNN': knn}
for name, model in model_dict.items():
mse.loc[name, 'train'] = mean_squared_error(y_train, model.predict(X_train))/1e6
mse.loc[name, 'test'] = mean_squared_error(y_test, model.predict(X_test))/1e6
mse| train | test | |
|---|---|---|
| MLR | 1.28099 | 1.20728 |
| Lasso | 1.52063 | 1.40896 |
| KNN | 0.670217 | 0.780877 |
fig, ax = plt.subplots()
mse.sort_values(by='test', ascending=False).plot(kind='barh', ax=ax, zorder=3)
ax.grid(zorder=0)
Juzgando por el rendimiento en el conjunto de test, el KNN es el mejor modelo. Notar que el rendimiento es mejor en el conjunto de test en comparación con el conjunto de train, como es de esperar. Para lasso y la regresión multiple, la situación es la contraria, lo que es poco común, pero posible. Lo que ocurre aquí es que como hemos dedicado solo el 10% de la data para evaluarla, la mayoría de los errores extremos en la predicción son encontrados en el conjunto de entrenamiento. Como MSE es un promedio de los errores al cuadrado, los errores grandes tienen a afectar mucho ese promedio
Esto comprueba de que no siempre es verdad que el conjunto de entrenamiento entrega mejores rendimientos que el conjunto de test, por lo que no es un teorema matemático que siempre es verdadero.
Cuando realizamos estas pruebas de testing pueden producirse las siguientes situaciones:
- Las diferencias no son muy grandes como en este caso, lo que nos dice que el modelo o los modelos están bien.
- Cuando hay una gran diferencia entre el conjunto de test y el de entrenamiento, siendo este último de mejor rendimiento, podriamos estar ante un escenario de overfitting.
- Cuando hay mucha diferencia entre el conjunto de entrenamiento y de test, siendo este último de mejor rendimiento tendriamos que replantearnos el procedimiento de separación de los datos y los pasos de preprocesamiento. Si
Finalmente, para hacer esto un poco más concreto, veamos algunas predicciones y la comparación con su precio real.
demo_pred = X_test.iloc[:10].copy()
pred_dict = {'y_true':y_test[:10]}
for name, model in model_dict.items():
pred_dict['pred_'+name] = model.predict(demo_pred).round(1)
pd.DataFrame(pred_dict)| y_true | pred_MLR | pred_Lasso | pred_KNN | |
|---|---|---|---|---|
| 8550 | 4434 | 4637.9 | 4993.5 | 4172.9 |
| 27124 | 17313 | 15503.1 | 14917.8 | 14771.3 |
| 40908 | 1179 | 1603.1 | 1611.8 | 1092.5 |
| 1376 | 2966 | 3063.1 | 3299.3 | 2915.8 |
| 41674 | 1240 | 1859.7 | 1567.6 | 978.0 |
| 35462 | 901 | 1700.2 | 1329.0 | 1158.1 |
| 30656 | 736 | 1086.5 | 689.5 | 754.6 |
| 10272 | 4752 | 6010.8 | 6042.7 | 4970.2 |
| 28929 | 684 | 904.1 | 762.1 | 753.5 |
| 26352 | 645 | 704.7 | 651.3 | 722.9 |
¿Qué piensas de estas predicciones? ¿Pueden ser mejoradas? ¿Es MSE una métrica suficiente para medir el rendimiento o necesitamos una métrica más entendible? ¿Que hay del sesgo del vector objetivo? ¿Qué podemos hacer con eso? ¿Por qué elegimos k=12? ¿Por qué no 10 o 15? Siempre es bueno cuestionarnos y ver como podemos mejorar el modelo aún más.
Introducción a las redes neuronales para el análisis predictivo.
Las redes neuronales forman parte del área de deep learning o lenguaje profundo. Son utilizados en general para resolver problemas complejos como autos autónomos, traductor, reconocimiento de voz, visión de computación, nivel sobrehumano en distintos juegos, etc. Para comenzar, veremos un tipo básivo de red neuronal llamado MLP (multilayer perceptron) para realizar predicciones.
Deep Learning es una subárea de Machine Learning basados en modelos llamados redes neuronales. Estos modelos son construidos en una serie de capas dónde cada capa recoge un input que equivale a un output de la capa anterior. Cada capa exitosa en una red neuronal puede ser vista como una representación cada vez más significativa de las variables. La palabra "deep" en deep learning tiene relación con el número de capas que son utilizadas en una red neuronal. Algunos modelos arquitectónicos requieren decenas o incluso cientos de capas y son capaces de aprender tareas muy complejas, como las que mencionamos anteriormente. El éxito de estos modelos viene de la habilidad de aprender autompaticamente representaciones útiles de datos no estructurados, como videos, audios, imagenenes, textos, entre otros.
No hay un concenso para definir cuántas capas se necesitan para que un modelo pueda ser considerado como deep learning, pero como referencia, 24 capas o más puede ser considerado para muchas personas como un modelo de deep learning.
Las redes neuronales son inspiradas por la estructura del cerebro. Al igual que las neuronas del cerebro que están conectadas entre si para realizar ciertas tareas, las neuronas de un modelo de machine learning también están conectadas y también realizan calculos, formando una red interconectada de neuronas llamada unidad. La comparación termina aquí, dado que el cerebro tiene una complicada estructura y hay muchas cosas del cerebro que aún no sabemos, por lo tanto el funcionamiento de un modelo de deep learning y el funcionamiento del cerebro estám a muchísimos kilometros de distancia.
Como nuestra base de datos es relativamente pequeña, no construiremos un modelo de deep learning muy complejo, si no que tendrá pocas capas. La idea es representar los conceptos fundamentales y aprender como entrenar el tipo más fundamental de una red neuronal: Las MLP.
Anatomía de los elementos en un MLP
Hay muchos términos que hay que conocer para entender el funcionamiento de una red neuronal. Algunos de estos elementos tienen que ver con los modelos de redes neuronales y otros con el proceso de entrenamiento. Comencemos describiendo la jerarquía que define un modelo: Las redes neuronales están hechas de capas y las capas están hechas de neuronas.
Neuronas
Las neuronas o neuronas artificiales son la unidad computacional de una red neuronal. Estas neuronas son funciones matemáticas que reciben n inputs o un vector y retorna un output.
$output = g(W_1X_1 + W_2X_2 + W_3X_3 + W_nX_n + b) = g(\sum_{i=1}^{n} W_iX_i + b)$
La visualización de una neurona con dos inputs se ve de esta manera:
Estos tipos de neuronaes tienen tres elementos:
1) Peso: Son el set de las W que están en la formula y que están multiplicando a cada input.
2) Sesgo (bias): Es la letra "b" en la ecuación que es añadida a la suma. Hay una razón técnica de porque esta constante hará mejor el modelo.
3) Función de activación: En la formula es la "g" y es el componente que introduce la no-linealidad en el modelo. Hay activaciones estándares como la sigmoide, la tangente hiperbólica o el ReLu. A continuación podemos ver como se ven cada una de estas funciones de activación.
x = np.linspace(-5, 5, 200)
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(10, 4))
ax[0].plot(x, 1/(1+np.exp(-x)))
ax[0].set_title('Sigmoide')
ax[1].plot(x, np.tanh(x))
ax[1].set_title('Tangente Hiperbólica')
ax[2].plot(x, np.maximum(0, x))
ax[2].set_title('ReLu')
for p in ax:
p.grid()
Capas
Las capas son hechas de neuronas. Una capa es como un modulo de procesamiento de datos del modelo: este recibe un inputs y produce outputs. Matemáticamente, una capa puede ser considerada como una función que recibe k inputs y retorna m outputs. Las capas son los componentes que extraen representaciones útiles de los datos. Hay distintos tipos de capas y nosotros veremos el tipo de capa densa o totalmente conectada.
Red Neuronal
Este es el modelo que consiste en un número de capas exitosas. Dependiendo de su posición, las capas se definen de la siguiente manera:
- Capa de entrada: Esta es la capa que consiste en nuestros atributos del dataset.
- Capa oculta: Son las capas internas de una red neuronal. Aqui es donde el procesamiento y el aprendizaje se lleva a cabo.
- Capa de salida: Es la capa que produce el resultado. En el caso de una regresión, esta capa sería la predicción y en el caso de una clasificación sería usualmente la probabilidad de pertenecer a cada categoría.
Como aprender los MLPs
Los MPL pueden ser considerados como los modelos paramétricos, asi como la regresión multiple, entrenar un MLP significa encontrar el conjunto correcto de pesos (W) y sesgos (b) de tal manera que el modelo aprenda a utilizar los atributos del dataset para producir el valor objetivo. En un modelo de regresión multiple, el conjunto de pesos hará que no haya otra combinación que minimice la sumatoria del error cuadrático. Con un modelo MLP intentamos hacer algo similar: encontrar la mejor combinación de peso para realizar buenas predicciones. Sin embargo, hay razones técnicas de porque no es posible encontrar el mejor conjunto de pesos, por lo que entrenar un modelo MLP significa encontrar el conjunto de pesos y sesgo que sea "suficientemente bueno" para que el modelor realice buenas predicciones.
El proceso de entrenamiento de un MLP comienza con definir aleatoriamente el conjunto de pesos. El sesgo generalmente comienza con 1. Hay algunas reglas y mejores prácticas para una inicialización aleatoria y estas mejores prácticas están construidas dentro de las librerías de deep learning. Luego de realizar esta inicialización aleatoria, podemos comenzar el entrenamiento que consta de los siguientes pasos:
1) Conseguir un lote: Conseguir un lote de muestras de entrenamiento y sus objetivos correspondientes. Generalmente, las redes neuronales trabajan con datasets muy grandes y por la forma en que son entrenados, no procesan todo el conjunto de entrenamiento de una sola vez. En vez de eso, los datos son divididos en lotes y los datos van pasando por la red neuronal uno a la vez. El tamaño del lote es el monto de muestras en el lote. Por convención, los lotes son en general en exponentes de dos, como 32, 64, 128, 256 o 512. Sin embargo, puedes usar cualquier valor, como 100. Hay una buena evidencia que es mejor utilizar números pequeños y no grandes como 512 (Sirish et al., 2017)
2) Pasar hacia adelante: Consiste en pasar el lote al MLP y obtener predicciones.
3) Calcular las pérdidas: Las perdidas se calculan con la función de pérdida una vez que ya tenemos las predicciones. Esta función mide que tan buenas son las predicciones realizadas. Esta produce la señal que le dira al modelo que tan cerca está la predicción al vector objetivo. Esta función tomará las predicciones y el vector objetivo y arrojará un número llamado la pérdida. En otras palabras, en este paso calculamos la pérdida del lote que corresponde a una medida de discordancia entre lo predicho y lo observado. Por ejemplo, en problemas de regresión, la función de pérdida más común es el MSE y es la que utilizaremos para este ejercicio.
4) Actualizar los pesos: Actualizar todos los pesos y los sesgos de la red de manera simultánea de una manera tal que reduzca la pérdida del lote actual. Este es un trabajo del optimizador. Este elemento del modelo está a cargo de tomar la señal de la función de pérdida y ajustar o actualizar los pesos para reducir esa pérdida. El mecanismo usual en que está tarea es realizada se llama propagación hacia atrás o backpropagation. Hay muchas elecciones para elegir un optimizador y los investigadores continuan realizando progresos en esta área, pero escencialmente todos los optimizadores son variaciones del algoritmo de gradiente descendiente. Para el presente problema de predicción de precios de diamantes, utilizaremos el optimizador Adam que se ha convertido muy popular, porque ha demostrado buenos resultados en una variedad de problemas.
El bucle de entrenamiento está complete en un epoch que es un ciclo completo sobre el conjunto de entrenamiento. Por ejemplo, supongamos que nuestro dataset tiene un tamaño de 6.400 y el lote tiene un tamaño de 64. El bucle de entrenamiento que describimos correrá 100 iteraciones para completar un epoch. Usualmente, se necesitan muchos epochs para entrenar una red neuronal. En este ejemplo la red neuronal es entrenado en 10 epochs, por lo que el peso inicial será actualizado 100 veces por epoch lo que nos da 1.000 actualizaciones de peso.
Hay que tener cuidado, porque si hay pocos epoch, la red no aprenderá muy bien y por el contrario, si hay muchos epoch, la red ocasionará un overfit a nuestro conjunto de entrenamiento.
Introducción a TensorFlow y Keras
Usualmente, los modelos de redes neuronales necesitan grandes cantidades de datos, superando a otros algoritmos de machine learning. Una gran ventaja es que el proceso de entrenamiento en una red neuronal puede hacer un trabajo paralelo en el hardware como en la unidad de proceso gráfico o graphical processing unit (GPU). La GPU entrena una red neuronal más rápida que una CPU tradicional y por lo mismo algunos frameworks han desarrollado la capacidad de utilizar las GPUs. Algunos de estos frameworks son Theano, Caffe y TensorFlow.Estos frameworks han permitido que los modelos de deep learning puedan ser utilizados por profesionales fuera del cículo académico.
TensorFlow
TensorFlow es una librería de Google especializada en aprendizaje profundo que permite el desarrollo a través de distintas plataformas, como en CPU, GPU y TPU. Hay dos versiones para TensorFlow: una versión para GPU y la otra para CPU.
TensorFlow solo para CPU: Si tu equipo no tiene una GPU NVIDIA debieses instalar esta versión. Esta versión es más fácil de instalar, por lo que, aunque tengas una GPU NVIDIA se recomienda instalar esta versión primero.
TensorFlow solo para GPU: Como mencionamos, los programas tipicamente corren más rápido en una GPU, por lo que, si cumples los requisitos computacionales y necesitas correr aplicaciones donde el rendimiento sea critico, deberías instalar esta versión, es especial si trabajas con grandes cantidades de datos.
En caso de que no tengas una GPU hay alternativas como FloydHub y PaperSpace que basicamente te arriendan el hardware necesario para que puedas entrenar tus modelos de aprendizaje profundo. De lo contrario, puedes instalar la versión GPU aunque su instalación es dificil. Para revisar los requisitos para la instalación de la versión con GPU la puedes revisar aquí.
Para instalar TensorFlow podemos utilizar el comando pip install --ignore-installed --upgrade tensorflow en un terminal.
TensorFlow incluye muchas capacidades computacionales avanzadas y esta basado en un paradigma llamado dataflow, lo que quiere decir que TensorFlow trabaja primero en construir grafos y luego correr el algoritmo realizado por los grafos dentro de objetos especializados llamados sesiones, que están a cargo de ubicar los algoritmos de los grafos a distintos dispositivos, como la CPU o la GPU. Este paradigma no es tan sencillo de usar y entender, por lo tanto, no utilizaremos TensorFlow directamente, sino como backend y será el que realice todos los calculos detrás del telón. La librería que utilizaremos como interfaz para construir una red neuronal se llama Keras.
Keras
Keras es una librería amigable que sirve como Front-End de TensorFlow u otras librerías de aprendizaje profundo, como Theano. El objetivo principal de Keras es acercar o democratizar la creación de modelos en aprendizaje profundo a las personas que no tienen mucho acercamiento a la informática. Como se explica en su sitio oficial, Keras es una API de alto nivel escrita en Python y capaz de ejecutarse sobre TensorFlow, CNTK y Theano. Fue desarrollado en un enfoque de la experimentación rápida para que desde la idea a la ejecución se pueda hacer en el menor tiempo posible, lo que ayuda a realizar buenas investigaciones.
Para instalar Keras, primero se debe instalar exitosamente TensorFlow. Con correr el siguiente comando en la terminal ya estaríamos listos: pip install keras
Regresión con redes neuronales
Aunque MLP es un modelo muy comlicado para este problema y el dataset es pequeño, no hay razones para no utilizar MLP con el fin de resolverlo. Recordemos que los stakeholders quieren un modelo lo más preciso posible en realizar las predicciones, entonces veamos a qué tanta precisión podemos llegar utilizando MLP.
Como los modelos de redes neuronales consisten en una secuencia de capas, Keras tiene una clase llamada Sequential que podemos usar para instanciar un modelo de red neuronal.
from keras.models import Sequential
nn_reg = Sequential()Con esto creamos una red neuronal vacia llamada nn_reg. Ahora, tenemos que agregarle capas. Utilizaremos lo que se llama una conexión completa o capas densa (dense layers). Estas son capas hechas por neuronas que están conectadas a todas las neuronas de la capa anterior. En otras palabras, cada neurona en una capa densa recibe el output de todas las neuronas de la capa anterior. Como nuestra red neuronal estará hecha de capas densas, importamos la clase Dense.
from keras.layers import DenseComo se menciono anteriormente, la primera capa de un MLP es siempre la capa de entrada y es la que recibe los datos de los atributos y se los pasa a la primera capa oculta. Sin embargo, en Keras no hay necesidad de crear la capa de entrada, porque esta capa son basicamente los atributos. Por lo tanto explicitamente no veras la primera capa en el código, pero conceptualmente está. Dicho esto, la primera capa que añadiremos a nuestra red neuronal vacia es la primera capa oculta. Esta es una capa especial, porque tenemos que especificar con un tuple la forma del input. Desde la documentación de Keras, podemos leer que solo la primera capa en un modelo secuencial necesita recibir la información acerca del tamaño de la matriz.
n_input = X_train.shape[1]
n_hidden1 = 32
# añadimos la primera capa oculta
nn_reg.add(Dense(units=n_hidden1, activation='relu', input_shape=(n_input,)))Veamos que significa cada uno de los parámetros:
- units: Corresponde al número de neuronas en la capa. Estamos utilizando 32.
- activation: Esta corresponde a la función de activación que utilizaremos en cada neurona. Estamos utilizando relu como función de activación.
- input_shape: Este es el número de inputs que la red va a recibir que es equivalente al núimero de atributos en nuestro dataset. No necesitamos especificar el núimero de muestras que la red va a recibir, dado que puede trabajar con cualquier cantidad de muestra.
Ahora nuestra red neuronal tiene una capa oculta. Como este problema es simple y tenemos un dataset relativamente pequeño, añadiremos dos capas ocultas más. Pocas personas considerarían esto un aprendizaje profundo, dado que solo tenemos tres capas, pero el proceso de construcción y entrenamiento es escencialmente el mismo con 3 o 300 capas. Añadiremos ahora dos capas ocultas más.
n_hidden2 = 16
n_hidden3 = 8
# añadimos una segunda capa oculta
nn_reg.add(Dense(units=n_hidden2, activation='relu'))
# añadimos una tercera capa oculta
nn_reg.add(Dense(units=n_hidden3, activation='relu'))Note que la cantidad de unidades que estamos utilizando en cada capa son 32, 16 y 8, respectivamente. Es una práctica común utilizar una potencia de dos para la creación de unidades y también notese que la forma de esta red neuronal es como un embudo, porque estamos reduciendo la cantidad de neuronas a medida que avanzamos en capas. No hay nada de especial con esta forma, pero empiricamente, a veces funciona muy bien. Otra aproximación es utilizar el mismo número de neuronas en cada capa oculta.
Para terminar nuestra red neuronal tenemos que añadir una capa de salida. Como este es un problema de regresión para cada muestra, queremos solo un output que es la predicción del precio. Necesitamos por tanto, una capa que conecte los 8 outputs de la capa anterior a un output que nos dará la predicción del precio. En esta última capa no hay necesidad de una función de activación, dado que estamos obteniendo la predicción final.
# capa de salida
nn_reg.add(Dense(units=1, activation=None))La arquitectura de nuestra red neuronal ha finalizado. Como los modelos que utilizamos anteriormente, esta red neuronal es una función que toma los valores de 21 atributos y produce un número como output. A continuación, veremos la predicción de los primeros 5 diamantes en el conjunto de entrenamiento.
nn_reg.predict(X_train.iloc[:5, :])array([[ 0.06229285],
[-0.10458608],
[ 0.0490252 ],
[ 0.00462438],
[-0.03860806]], dtype=float32)
Estas son las predicciones y como podemos ver son muy malas predicciones. Esto ocurrió porque cada neurona en nuestra red inicio con un peso aleatorio. Los sesgos por defecto inician con 1. Este proceso de iniciación se llama Glorot uniform initializer también llamado Xavier uniform initializer (Glorot & Bengio, 2010) que es uno de las formas más populares para iniciar redes neuronales y ha demostrado ser muy util en la practica. Hay otras formas de iniciado, pero solo veremos la que mencioné.
Ahora tendremos que comenzar a modificar estos pesos y sesgos aleatorios de a poco utilizando nuestro conjunto de entrenamiento en un bucle de entrenamiento.
Entrenando con MLP
Una vez de que nos hayamos decidido las cuatro caracteristicas que va a tener nuestra red neuronal (cantidad de lotes, número de epochs, función de pérdida y el optimizador) podemos compilar el modelo diciendole a Keras la función de pérdida y optimizar que vamos a utilizar.
nn_reg.compile(loss='mean_squared_error', optimizer='adam')Si queremos mirar la arquitectura y el número de parámetros en el modelo, podemos utilizar el método summary.
nn_reg.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 32) 704
dense_1 (Dense) (None, 16) 528
dense_2 (Dense) (None, 8) 136
dense_3 (Dense) (None, 1) 9
=================================================================
Total params: 1,377
Trainable params: 1,377
Non-trainable params: 0
_________________________________________________________________
Tenemos un total de 1.377 pesos y sesgos en nuestro modelo. Ahora, estamos listos para entrenar nuestro modelo utilizando el método fit.
batch_size = 64
n_epochs = 50
nn_reg.fit(X_train, y_train, epochs=n_epochs, batch_size=batch_size)Epoch 1/50 759/759 [==============================] - 1s 949us/step - loss: 16341780.0000 Epoch 2/50 759/759 [==============================] - 1s 1ms/step - loss: 1917740.8750 Epoch 3/50 759/759 [==============================] - 1s 1ms/step - loss: 1271546.8750A: 0s - los Epoch 4/50 759/759 [==============================] - 1s 878us/step - loss: 1041337.9375 Epoch 5/50 759/759 [==============================] - 1s 939us/step - loss: 904617.7500 Epoch 6/50 759/759 [==============================] - 1s 899us/step - loss: 813572.2500 Epoch 7/50 759/759 [==============================] - 1s 950us/step - loss: 759096.3125 Epoch 8/50 759/759 [==============================] - 1s 919us/step - loss: 723737.8125 Epoch 9/50 759/759 [==============================] - 1s 965us/step - loss: 694418.5000 Epoch 10/50 759/759 [==============================] - 1s 986us/step - loss: 668318.8125 Epoch 11/50 759/759 [==============================] - 1s 938us/step - loss: 646594.5000 Epoch 12/50 759/759 [==============================] - 1s 969us/step - loss: 626925.3750 Epoch 13/50 759/759 [==============================] - 1s 1ms/step - loss: 608489.9375 Epoch 14/50 759/759 [==============================] - 1s 1ms/step - loss: 591479.4375 Epoch 15/50 759/759 [==============================] - 1s 968us/step - loss: 573256.3125 Epoch 16/50 759/759 [==============================] - 1s 1ms/step - loss: 558243.1250 Epoch 17/50 759/759 [==============================] - 1s 925us/step - loss: 544210.3750 Epoch 18/50 759/759 [==============================] - 1s 996us/step - loss: 530760.8125 Epoch 19/50 759/759 [==============================] - 1s 1ms/step - loss: 515659.4688 Epoch 20/50 759/759 [==============================] - 1s 953us/step - loss: 502315.0625 Epoch 21/50 759/759 [==============================] - 1s 991us/step - loss: 488250.2500 Epoch 22/50 759/759 [==============================] - 1s 1ms/step - loss: 476416.1875 Epoch 23/50 759/759 [==============================] - 1s 958us/step - loss: 463782.2188 Epoch 24/50 759/759 [==============================] - 1s 1ms/step - loss: 452431.7812 Epoch 25/50 759/759 [==============================] - 1s 976us/step - loss: 442091.4062 Epoch 26/50 759/759 [==============================] - 1s 962us/step - loss: 431119.7500 Epoch 27/50 759/759 [==============================] - 1s 938us/step - loss: 421290.0938 Epoch 28/50 759/759 [==============================] - 1s 964us/step - loss: 413771.4062 Epoch 29/50 759/759 [==============================] - 1s 1ms/step - loss: 405679.2188 Epoch 30/50 759/759 [==============================] - 1s 1ms/step - loss: 398222.2188 Epoch 31/50 759/759 [==============================] - 1s 1ms/step - loss: 392156.5625 Epoch 32/50 759/759 [==============================] - 1s 994us/step - loss: 386106.2812 Epoch 33/50 759/759 [==============================] - 1s 1ms/step - loss: 380575.0312 Epoch 34/50 759/759 [==============================] - 1s 947us/step - loss: 376328.6562 Epoch 35/50 759/759 [==============================] - 1s 948us/step - loss: 371615.3125 Epoch 36/50 759/759 [==============================] - 1s 908us/step - loss: 366925.4688 Epoch 37/50 759/759 [==============================] - 1s 955us/step - loss: 363162.1562 Epoch 38/50 759/759 [==============================] - 1s 1ms/step - loss: 359395.0625 Epoch 39/50 759/759 [==============================] - 1s 1ms/step - loss: 356251.6562 Epoch 40/50 759/759 [==============================] - 1s 1ms/step - loss: 353012.3750 Epoch 41/50 759/759 [==============================] - 1s 1ms/step - loss: 350507.6562 Epoch 42/50 759/759 [==============================] - 1s 1ms/step - loss: 347549.1562 Epoch 43/50 759/759 [==============================] - 1s 1ms/step - loss: 345233.0938 Epoch 44/50 759/759 [==============================] - 1s 1ms/step - loss: 343015.2812 Epoch 45/50 759/759 [==============================] - 1s 938us/step - loss: 341124.6250 Epoch 46/50 759/759 [==============================] - 1s 935us/step - loss: 339445.9688 Epoch 47/50 759/759 [==============================] - 1s 938us/step - loss: 337315.0938 Epoch 48/50 759/759 [==============================] - 1s 913us/step - loss: 336572.9688 Epoch 49/50 759/759 [==============================] - 1s 1ms/step - loss: 334389.6875 Epoch 50/50 759/759 [==============================] - 1s 1ms/step - loss: 332505.4688
Lo anterior muestra, con cada epoch, como la pérdida de entrenamiento se va viendo reducida. Recordar que el bucle de entrenamiento fue realizado anteriormente en cada epoch, en nuestro caso, 50 veces. Con esto ya hemos entrenado nuestra primera red neuronal.
Ahora, es momento de evaluar que tan bien fueron las predicciones, comparando el conjunto de entrenamiento y de test utilizando MSE.
y_pred_train = nn_reg.predict(X_train)
y_pred_test = nn_reg.predict(X_test)
train_mse = mean_squared_error(y_true=y_train, y_pred=y_pred_train)
test_mse = mean_squared_error(y_true=y_test, y_pred=y_pred_test)
print('Train MSE: {:0.3f} \nTest MSE: {:0.3f}'.format(train_mse / 1e6, test_mse / 1e6))Train MSE: 0.328
Test MSE: 0.336Con estos resultados hemos reducido bastante los valores MSE de los otros modelos que vimos. Podemos notar lo poderoso que son las redes neuronales, donde en muchos casos podemos obtener mejores resultados.
Regularización de redes neuronales.
Existen dos métodos que nos pueden ayudar a evitar el sobreajuste en MLP. El primero tiene que ver con la cantidad de epochs que utilizamos. Recordar que con cada epoch estamos actualizando el peso y disminuyendo la pérdida y cuando tenemos muchos epochs, la predicción estará también ajustandose al ruido del conjunto de entrenamiento. Una forma de enfrentar este problema es entrenar la red neuronal hasta que la pérdida u otra métrica de rendimiento deje de mejorar. Tenemos que tener cuidado con esto, dado que la pérdida casi siempre (por no decir siempre) va decreciendo y en ese sentido debemos monitorear otra cantidad: pérdida de validación o validation loss. Esta pérdida es calculada en el conjunto de validación que es un pequeño subconjunto dentro del conjunto de entrenamiento. Esto no es utilizado para entrenar, sino que es utilizado para el ajuste de hiperparámetros. Las validaciones las vamos a monitorear en este conjunto que es independiente al conjunto de entrenamiento.
Muchas decisiones en tan poco tiempo.
Este es el principal problema de utilizar redes neuronales en el análisis predictivo. Hay muchas decisiones que tomar donde es muy dificil adivinar una buena configuración cuando resolvemos un problema. Uno tiene que tomar decisiones en la arquitectura del modelo, como las siguientes:
1) Número de capas.
2) Número de unidades en cada capa.
3) La función de activación en cada capa.
4) El método utilizado para obtener el peso inicial.
Para el paso de compilación debemos tomar las siguientes decisiones:
1) La función de pérdida.
2) El optimizador.
3) Los parámetros del optimizador.
Para el paso de compilación debemos tomar las siguientes decisiones:
1) El tamaño del lote.
2) El número de epochs.
Finalmente, como las redes neuronales son muy susceptibles a sobreajustarse, casi siempre vamos a tener que realizar una regularización. Por lo tanto, tenemos que decidir sobre:
1) El tipo de regularización.
2) Los parámetros de regularización.
Para dimensionar más o menos lo complicado que es tomar en total 11 decisiones, imahinemos que tenemos tres opciones para cada decisión. El número total de combinaciones es $3^{11}$ lo que equivale a 117.147 posibles configuraciones para nuestro modelo. Digamos que solo considera el 10% de todas estas combinaciones, incluso si la red se demora un segundo en entrenar y evaluar (una asunción muy irrealista) sería muy impráctico probar muchas configuraciones uno a uno para encontrar la mejor connfiguración y puede incluso que la mejor condiguración, si es que la encontramos, no de buenos resultados. Las buenas noticias es que hay muchos tips prácticos, teóricos y resultados empiricos que disminuirían la dimensión de búsqueda y permitirá que eligas buenos valores de configuración para tu red neuronal. La mala noticia es que para entender algunos de estos resultados y como utilizarlos de manera efectiva requiere conocimientos técnicos avanzados e incluso de haber adquirido esos conocimientos aún existirá mucha prueba y error en el proceso.
Regularización de redes neuronales.
Existen dos métodos que nos pueden ayudar a evitar el sobreajuste en MLP. El primero tiene que ver con la cantidad de epochs que utilizamos. Recordar que con cada epoch estamos actualizando el peso y disminuyendo la pérdida y cuando tenemos muchos epochs, la predicción estará también ajustandose al ruido del conjunto de entrenamiento. Una forma de enfrentar este problema es entrenar la red neuronal hasta que la pérdida u otra métrica de rendimiento deje de mejorar. Tenemos que tener cuidado con esto, dado que la pérdida casi siempre (por no decir siempre) va decreciendo y en ese sentido debemos monitorear otra cantidad: pérdida de validación o validation loss. Esta pérdida es calculada en el conjunto de validación que es un pequeño subconjunto dentro del conjunto de entrenamiento. Esto no es utilizado para entrenar, sino que es utilizado para el ajuste de hiperparámetros. Las validaciones las vamos a monitorear en este conjunto que es independiente al conjunto de entrenamiento.
Antes de implementar un break vamos a crear otra red neuronal para implementar este monitoreo de pérdida de validación.
nn_reg2 = Sequential()
n_hidden = 64
# capas ocultas
nn_reg2.add(Dense(units=n_hidden, activation='relu', input_shape=(n_input,)))
nn_reg2.add(Dense(units=n_hidden, activation='relu'))
nn_reg2.add(Dense(units=n_hidden, activation='relu'))
nn_reg2.add(Dense(units=n_hidden, activation='relu'))
nn_reg2.add(Dense(units=n_hidden, activation='relu'))
nn_reg2.add(Dense(units=n_hidden, activation='relu'))
nn_reg2.add(Dense(units=1, activation=None))
nn_reg2.compile(loss='mean_squared_error', optimizer='adam', metrics=['mse', 'mae'])
nn_reg2.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 64) 1408
dense_5 (Dense) (None, 64) 4160
dense_6 (Dense) (None, 64) 4160
dense_7 (Dense) (None, 64) 4160
dense_8 (Dense) (None, 64) 4160
dense_9 (Dense) (None, 64) 4160
dense_10 (Dense) (None, 1) 65
=================================================================
Total params: 22,273
Trainable params: 22,273
Non-trainable params: 0
_________________________________________________________________
Para utilizar un dataset de validación simplemente tenemos que usar el parámetro validation_split cuando entrenamos el modelo con fit. Esto es para indicar que una fracción del conjunto de entrenamiento sea utilizado para validación, por lo que, el modelo no aprenderá de este conjunto. En Keras el conjunto de validación es seleccionado desde las últimas muestras de los datos en X_train e y_train antes de ser distribuidos aleatoriamente. Utilicemos el 10% del conjunto de entrenamiento para validar.
Al momento de entrenar con el argumento validation_split, Keras mostrará las métricas y las pérdidas del conjunto de entrenamiento y validación.
batch_size = 64
n_epochs = 300
history = nn_reg2.fit(X_train, y_train,
epochs = n_epochs,
batch_size = batch_size,
validation_split = 0.1)Epoch 1/300 683/683 [==============================] - 2s 2ms/step - loss: 4110144.0000 - mse: 4110144.0000 - mae: 972.2050 - val_loss: 846573.8125 - val_mse: 846573.8125 - val_mae: 472.6755 Epoch 2/300 683/683 [==============================] - 1s 1ms/step - loss: 666911.1250 - mse: 666911.1250 - mae: 428.4597 - val_loss: 610728.0625 - val_mse: 610728.0625 - val_mae: 408.0857 Epoch 3/300 683/683 [==============================] - 1s 1ms/step - loss: 531972.4375 - mse: 531972.4375 - mae: 389.8846 - val_loss: 521315.9375 - val_mse: 521315.9375 - val_mae: 381.8714 Epoch 4/300 683/683 [==============================] - 1s 1ms/step - loss: 445180.9062 - mse: 445180.9062 - mae: 365.5223 - val_loss: 430147.3438 - val_mse: 430147.3438 - val_mae: 353.4983 Epoch 5/300 683/683 [==============================] - 1s 2ms/step - loss: 400019.9375 - mse: 400019.9375 - mae: 350.0450 - val_loss: 447040.2812 - val_mse: 447040.2812 - val_mae: 372.8147 Epoch 6/300 683/683 [==============================] - 1s 1ms/step - loss: 380871.3750 - mse: 380871.3750 - mae: 342.4088 - val_loss: 409936.8125 - val_mse: 409936.8125 - val_mae: 353.0484 Epoch 7/300 683/683 [==============================] - 1s 1ms/step - loss: 355959.8438 - mse: 355959.8438 - mae: 330.2881 - val_loss: 365546.8125 - val_mse: 365546.8125 - val_mae: 330.4814 Epoch 8/300 683/683 [==============================] - 1s 1ms/step - loss: 348276.5938 - mse: 348276.5938 - mae: 326.5658 - val_loss: 384777.0312 - val_mse: 384777.0312 - val_mae: 337.6023 Epoch 9/300 683/683 [==============================] - 1s 2ms/step - loss: 342481.8750 - mse: 342481.8750 - mae: 323.3396 - val_loss: 370043.6250 - val_mse: 370043.6250 - val_mae: 342.3851 Epoch 10/300 683/683 [==============================] - 1s 2ms/step - loss: 342761.8125 - mse: 342761.8125 - mae: 323.0008 - val_loss: 413371.8750 - val_mse: 413371.8750 - val_mae: 340.9081 Epoch 11/300 683/683 [==============================] - 1s 1ms/step - loss: 332616.7812 - mse: 332616.7812 - mae: 317.3040 - val_loss: 365676.5625 - val_mse: 365676.5625 - val_mae: 330.0479 Epoch 12/300 683/683 [==============================] - 1s 1ms/step - loss: 333060.4062 - mse: 333060.4062 - mae: 319.6696 - val_loss: 395839.7500 - val_mse: 395839.7500 - val_mae: 343.7286 Epoch 13/300 683/683 [==============================] - 1s 1ms/step - loss: 332715.3438 - mse: 332715.3438 - mae: 318.8621 - val_loss: 375085.3750 - val_mse: 375085.3750 - val_mae: 343.5143 Epoch 14/300 683/683 [==============================] - 1s 1ms/step - loss: 326913.0938 - mse: 326913.0938 - mae: 313.9753 - val_loss: 371269.7812 - val_mse: 371269.7812 - val_mae: 327.2059 Epoch 15/300 683/683 [==============================] - 1s 1ms/step - loss: 318062.5312 - mse: 318062.5312 - mae: 309.0157 - val_loss: 327081.5312 - val_mse: 327081.5312 - val_mae: 307.8188 Epoch 16/300 683/683 [==============================] - 1s 1ms/step - loss: 321983.4375 - mse: 321983.4375 - mae: 312.4886 - val_loss: 335946.2188 - val_mse: 335946.2188 - val_mae: 304.3987 Epoch 17/300 683/683 [==============================] - 1s 2ms/step - loss: 314937.9688 - mse: 314937.9688 - mae: 308.1271 - val_loss: 346777.4688 - val_mse: 346777.4688 - val_mae: 330.3415 Epoch 18/300 683/683 [==============================] - 1s 2ms/step - loss: 322493.4375 - mse: 322493.4375 - mae: 312.4295 - val_loss: 339780.7812 - val_mse: 339780.7812 - val_mae: 313.3246 Epoch 19/300 683/683 [==============================] - 1s 2ms/step - loss: 310780.8438 - mse: 310780.8438 - mae: 306.1622 - val_loss: 344086.7500 - val_mse: 344086.7500 - val_mae: 302.8790 Epoch 20/300 683/683 [==============================] - 1s 2ms/step - loss: 311339.0938 - mse: 311339.0938 - mae: 305.9838 - val_loss: 323221.3125 - val_mse: 323221.3125 - val_mae: 306.7384 Epoch 21/300 683/683 [==============================] - 1s 1ms/step - loss: 307553.1875 - mse: 307553.1875 - mae: 303.9490 - val_loss: 315093.9688 - val_mse: 315093.9688 - val_mae: 297.5452 Epoch 22/300 683/683 [==============================] - 1s 1ms/step - loss: 298680.2812 - mse: 298680.2812 - mae: 299.4886 - val_loss: 323316.1562 - val_mse: 323316.1562 - val_mae: 305.8676 Epoch 23/300 683/683 [==============================] - 1s 1ms/step - loss: 305931.6875 - mse: 305931.6875 - mae: 303.5507 - val_loss: 333968.0312 - val_mse: 333968.0312 - val_mae: 310.8946 Epoch 24/300 683/683 [==============================] - 1s 1ms/step - loss: 309532.1562 - mse: 309532.1562 - mae: 304.3712 - val_loss: 484495.0938 - val_mse: 484495.0938 - val_mae: 414.0930 Epoch 25/300 683/683 [==============================] - 1s 1ms/step - loss: 299196.0312 - mse: 299196.0312 - mae: 299.1362 - val_loss: 321228.4688 - val_mse: 321228.4688 - val_mae: 305.0326 Epoch 26/300 683/683 [==============================] - 1s 1ms/step - loss: 306326.4688 - mse: 306326.4688 - mae: 305.1649 - val_loss: 351033.1562 - val_mse: 351033.1562 - val_mae: 334.3490 Epoch 27/300 683/683 [==============================] - 1s 1ms/step - loss: 300237.8750 - mse: 300237.8750 - mae: 300.1953 - val_loss: 367840.0000 - val_mse: 367840.0000 - val_mae: 325.3371 Epoch 28/300 683/683 [==============================] - 1s 1ms/step - loss: 308489.5000 - mse: 308489.5000 - mae: 303.3566 - val_loss: 315912.4062 - val_mse: 315912.4062 - val_mae: 303.9028 Epoch 29/300 683/683 [==============================] - 1s 1ms/step - loss: 298547.7188 - mse: 298547.7188 - mae: 299.8148 - val_loss: 355533.9375 - val_mse: 355533.9375 - val_mae: 329.1841 Epoch 30/300 683/683 [==============================] - 1s 1ms/step - loss: 301146.9375 - mse: 301146.9375 - mae: 299.8732 - val_loss: 316516.2188 - val_mse: 316516.2188 - val_mae: 299.6931 Epoch 31/300 683/683 [==============================] - 1s 1ms/step - loss: 298857.5312 - mse: 298857.5312 - mae: 298.0338 - val_loss: 325877.5312 - val_mse: 325877.5312 - val_mae: 298.8047 Epoch 32/300 683/683 [==============================] - 1s 1ms/step - loss: 297155.0625 - mse: 297155.0625 - mae: 299.2212 - val_loss: 329297.4688 - val_mse: 329297.4688 - val_mae: 300.0470 Epoch 33/300 683/683 [==============================] - 1s 1ms/step - loss: 290766.5938 - mse: 290766.5938 - mae: 295.9052 - val_loss: 351034.0000 - val_mse: 351034.0000 - val_mae: 337.1364 Epoch 34/300 683/683 [==============================] - 1s 1ms/step - loss: 293371.7500 - mse: 293371.7500 - mae: 295.6051 - val_loss: 344589.7500 - val_mse: 344589.7500 - val_mae: 333.7206 Epoch 35/300 683/683 [==============================] - 1s 2ms/step - loss: 294623.0000 - mse: 294623.0000 - mae: 297.4287 - val_loss: 315424.9688 - val_mse: 315424.9688 - val_mae: 296.1031 Epoch 36/300 683/683 [==============================] - 1s 1ms/step - loss: 289918.7188 - mse: 289918.7188 - mae: 295.1229 - val_loss: 315652.5000 - val_mse: 315652.5000 - val_mae: 303.5361 Epoch 37/300 683/683 [==============================] - 1s 1ms/step - loss: 289704.8750 - mse: 289704.8750 - mae: 293.5007 - val_loss: 306913.8438 - val_mse: 306913.8438 - val_mae: 291.8254 Epoch 38/300 683/683 [==============================] - 1s 1ms/step - loss: 290605.8125 - mse: 290605.8125 - mae: 295.2700 - val_loss: 329519.1875 - val_mse: 329519.1875 - val_mae: 310.5802 Epoch 39/300 683/683 [==============================] - 1s 1ms/step - loss: 286870.1250 - mse: 286870.1250 - mae: 291.9943 - val_loss: 344125.8125 - val_mse: 344125.8125 - val_mae: 315.4880 Epoch 40/300 683/683 [==============================] - 1s 1ms/step - loss: 291127.4688 - mse: 291127.4688 - mae: 294.3441 - val_loss: 320502.6562 - val_mse: 320502.6562 - val_mae: 301.0160 Epoch 41/300 683/683 [==============================] - 1s 1ms/step - loss: 286188.6875 - mse: 286188.6875 - mae: 291.7709 - val_loss: 314985.6875 - val_mse: 314985.6875 - val_mae: 291.7123 Epoch 42/300 683/683 [==============================] - 1s 1ms/step - loss: 288730.1250 - mse: 288730.1250 - mae: 293.9915 - val_loss: 341286.9375 - val_mse: 341286.9375 - val_mae: 330.4237 Epoch 43/300 683/683 [==============================] - 1s 1ms/step - loss: 289723.3438 - mse: 289723.3438 - mae: 293.1997 - val_loss: 313220.5312 - val_mse: 313220.5312 - val_mae: 296.8589 Epoch 44/300 683/683 [==============================] - 1s 1ms/step - loss: 282607.0938 - mse: 282607.0938 - mae: 289.0887 - val_loss: 313030.8125 - val_mse: 313030.8125 - val_mae: 298.3552 Epoch 45/300 683/683 [==============================] - 1s 1ms/step - loss: 284330.5625 - mse: 284330.5625 - mae: 290.8234 - val_loss: 334714.0000 - val_mse: 334714.0000 - val_mae: 308.0622 Epoch 46/300 683/683 [==============================] - 1s 1ms/step - loss: 288558.4375 - mse: 288558.4375 - mae: 294.5950 - val_loss: 316805.8750 - val_mse: 316805.8750 - val_mae: 296.9297 Epoch 47/300 683/683 [==============================] - 1s 1ms/step - loss: 284542.0938 - mse: 284542.0938 - mae: 292.2316 - val_loss: 320787.5000 - val_mse: 320787.5000 - val_mae: 300.9547 Epoch 48/300 683/683 [==============================] - 1s 1ms/step - loss: 294496.0625 - mse: 294496.0625 - mae: 296.9925 - val_loss: 304271.1875 - val_mse: 304271.1875 - val_mae: 288.5434 Epoch 49/300 683/683 [==============================] - 1s 1ms/step - loss: 292454.5625 - mse: 292454.5625 - mae: 296.0242 - val_loss: 342059.0000 - val_mse: 342059.0000 - val_mae: 304.1660 Epoch 50/300 683/683 [==============================] - 2s 2ms/step - loss: 282441.8438 - mse: 282441.8438 - mae: 289.8557 - val_loss: 310732.9375 - val_mse: 310732.9375 - val_mae: 302.0936 Epoch 51/300 683/683 [==============================] - 1s 2ms/step - loss: 285312.7812 - mse: 285312.7812 - mae: 291.9749 - val_loss: 317987.0625 - val_mse: 317987.0625 - val_mae: 297.7876 Epoch 52/300 683/683 [==============================] - 1s 2ms/step - loss: 284396.6875 - mse: 284396.6875 - mae: 292.4357 - val_loss: 327482.7188 - val_mse: 327482.7188 - val_mae: 306.0574 Epoch 53/300 683/683 [==============================] - 1s 2ms/step - loss: 281768.0625 - mse: 281768.0625 - mae: 289.5538 - val_loss: 321527.1875 - val_mse: 321527.1875 - val_mae: 297.4506 Epoch 54/300 683/683 [==============================] - 1s 2ms/step - loss: 279115.9375 - mse: 279115.9375 - mae: 288.4869 - val_loss: 319366.6562 - val_mse: 319366.6562 - val_mae: 297.8071 Epoch 55/300 683/683 [==============================] - 1s 2ms/step - loss: 279112.4688 - mse: 279112.4688 - mae: 287.9507 - val_loss: 316937.1562 - val_mse: 316937.1562 - val_mae: 293.0276 Epoch 56/300 683/683 [==============================] - 1s 2ms/step - loss: 286491.5312 - mse: 286491.5312 - mae: 293.2480 - val_loss: 332806.1875 - val_mse: 332806.1875 - val_mae: 318.3580 Epoch 57/300 683/683 [==============================] - 2s 3ms/step - loss: 280061.3750 - mse: 280061.3750 - mae: 287.6654 - val_loss: 329261.1562 - val_mse: 329261.1562 - val_mae: 318.5715 Epoch 58/300 683/683 [==============================] - 2s 2ms/step - loss: 279346.6875 - mse: 279346.6875 - mae: 287.9843 - val_loss: 322791.0625 - val_mse: 322791.0625 - val_mae: 304.2646 Epoch 59/300 683/683 [==============================] - 1s 1ms/step - loss: 277226.9062 - mse: 277226.9062 - mae: 288.8268 - val_loss: 308399.3438 - val_mse: 308399.3438 - val_mae: 295.8825 Epoch 60/300 683/683 [==============================] - 1s 1ms/step - loss: 281537.0938 - mse: 281537.0938 - mae: 290.3742 - val_loss: 319008.2812 - val_mse: 319008.2812 - val_mae: 296.8935 Epoch 61/300 683/683 [==============================] - 1s 1ms/step - loss: 272761.4062 - mse: 272761.4062 - mae: 284.3610 - val_loss: 328812.4062 - val_mse: 328812.4062 - val_mae: 305.5536 Epoch 62/300 683/683 [==============================] - 1s 1ms/step - loss: 277943.7812 - mse: 277943.7812 - mae: 287.7747 - val_loss: 316225.2812 - val_mse: 316225.2812 - val_mae: 291.9639 Epoch 63/300 683/683 [==============================] - 1s 1ms/step - loss: 276075.5625 - mse: 276075.5625 - mae: 287.9879 - val_loss: 312163.7188 - val_mse: 312163.7188 - val_mae: 295.3241 Epoch 64/300 683/683 [==============================] - 1s 1ms/step - loss: 274020.7500 - mse: 274020.7500 - mae: 286.1445 - val_loss: 324910.5312 - val_mse: 324910.5312 - val_mae: 304.3439 Epoch 65/300 683/683 [==============================] - 1s 1ms/step - loss: 277923.4062 - mse: 277923.4062 - mae: 288.0095 - val_loss: 349651.5000 - val_mse: 349651.5000 - val_mae: 320.5126 Epoch 66/300 683/683 [==============================] - 1s 1ms/step - loss: 269940.3750 - mse: 269940.3750 - mae: 282.5667 - val_loss: 311994.9062 - val_mse: 311994.9062 - val_mae: 297.3724 Epoch 67/300 683/683 [==============================] - 1s 1ms/step - loss: 278894.5000 - mse: 278894.5000 - mae: 287.4659 - val_loss: 330203.3125 - val_mse: 330203.3125 - val_mae: 305.2542 Epoch 68/300 683/683 [==============================] - 1s 1ms/step - loss: 280284.3438 - mse: 280284.3438 - mae: 288.9728 - val_loss: 323699.1875 - val_mse: 323699.1875 - val_mae: 306.4860 Epoch 69/300 683/683 [==============================] - 1s 1ms/step - loss: 273178.7500 - mse: 273178.7500 - mae: 285.8852 - val_loss: 326502.9375 - val_mse: 326502.9375 - val_mae: 311.9245 Epoch 70/300 683/683 [==============================] - 1s 1ms/step - loss: 278605.7188 - mse: 278605.7188 - mae: 287.3660 - val_loss: 313157.2500 - val_mse: 313157.2500 - val_mae: 293.0947 Epoch 71/300 683/683 [==============================] - 1s 1ms/step - loss: 287290.2500 - mse: 287290.2500 - mae: 294.6635 - val_loss: 322531.0312 - val_mse: 322531.0312 - val_mae: 292.4030 Epoch 72/300 683/683 [==============================] - 1s 2ms/step - loss: 272290.5000 - mse: 272290.5000 - mae: 282.9309 - val_loss: 325711.1562 - val_mse: 325711.1562 - val_mae: 292.3778 Epoch 73/300 683/683 [==============================] - 1s 2ms/step - loss: 269544.2500 - mse: 269544.2500 - mae: 283.8782 - val_loss: 345394.0625 - val_mse: 345394.0625 - val_mae: 325.0208 Epoch 74/300 683/683 [==============================] - 1s 1ms/step - loss: 270954.9375 - mse: 270954.9375 - mae: 284.6069 - val_loss: 403827.7500 - val_mse: 403827.7500 - val_mae: 359.8029 Epoch 75/300 683/683 [==============================] - 1s 1ms/step - loss: 270770.3750 - mse: 270770.3750 - mae: 285.0913 - val_loss: 305054.9375 - val_mse: 305054.9375 - val_mae: 296.5639 Epoch 76/300 683/683 [==============================] - 1s 1ms/step - loss: 275294.0938 - mse: 275294.0938 - mae: 287.3680 - val_loss: 330735.0312 - val_mse: 330735.0312 - val_mae: 307.1149 Epoch 77/300 683/683 [==============================] - 1s 2ms/step - loss: 273049.0625 - mse: 273049.0625 - mae: 285.5243 - val_loss: 320459.5625 - val_mse: 320459.5625 - val_mae: 309.4525 Epoch 78/300 683/683 [==============================] - 1s 1ms/step - loss: 272176.9375 - mse: 272176.9375 - mae: 284.7318 - val_loss: 308825.4062 - val_mse: 308825.4062 - val_mae: 298.0270 Epoch 79/300 683/683 [==============================] - 1s 1ms/step - loss: 268285.0625 - mse: 268285.0625 - mae: 282.5182 - val_loss: 317563.2500 - val_mse: 317563.2500 - val_mae: 301.1711 Epoch 80/300 683/683 [==============================] - 1s 1ms/step - loss: 266639.3438 - mse: 266639.3438 - mae: 281.6710 - val_loss: 316584.4062 - val_mse: 316584.4062 - val_mae: 302.7773 Epoch 81/300 683/683 [==============================] - 1s 1ms/step - loss: 268432.2812 - mse: 268432.2812 - mae: 283.7995 - val_loss: 346525.3125 - val_mse: 346525.3125 - val_mae: 323.0340 Epoch 82/300 683/683 [==============================] - 1s 1ms/step - loss: 276111.3438 - mse: 276111.3438 - mae: 287.0280 - val_loss: 311210.7812 - val_mse: 311210.7812 - val_mae: 286.9104 Epoch 83/300 683/683 [==============================] - 1s 1ms/step - loss: 275467.4062 - mse: 275467.4062 - mae: 287.0764 - val_loss: 324737.9375 - val_mse: 324737.9375 - val_mae: 306.9224 Epoch 84/300 683/683 [==============================] - 1s 2ms/step - loss: 273813.5938 - mse: 273813.5938 - mae: 286.5249 - val_loss: 311159.6562 - val_mse: 311159.6562 - val_mae: 294.2529 Epoch 85/300 683/683 [==============================] - 1s 1ms/step - loss: 273422.5312 - mse: 273422.5312 - mae: 285.7545 - val_loss: 320114.2500 - val_mse: 320114.2500 - val_mae: 295.8225 Epoch 86/300 683/683 [==============================] - 1s 1ms/step - loss: 267239.1250 - mse: 267239.1250 - mae: 282.7161 - val_loss: 318154.2188 - val_mse: 318154.2188 - val_mae: 292.0555 Epoch 87/300 683/683 [==============================] - 1s 1ms/step - loss: 269682.7188 - mse: 269682.7188 - mae: 283.8926 - val_loss: 348392.7500 - val_mse: 348392.7500 - val_mae: 317.6797 Epoch 88/300 683/683 [==============================] - 1s 1ms/step - loss: 263373.8438 - mse: 263373.8438 - mae: 279.0323 - val_loss: 307876.7188 - val_mse: 307876.7188 - val_mae: 294.1285 Epoch 89/300 683/683 [==============================] - 1s 1ms/step - loss: 263786.4375 - mse: 263786.4375 - mae: 280.3201 - val_loss: 311065.5312 - val_mse: 311065.5312 - val_mae: 296.8936 Epoch 90/300 683/683 [==============================] - 1s 1ms/step - loss: 265815.2500 - mse: 265815.2500 - mae: 280.8343 - val_loss: 332295.2500 - val_mse: 332295.2500 - val_mae: 312.4153 Epoch 91/300 683/683 [==============================] - 1s 1ms/step - loss: 269663.8750 - mse: 269663.8750 - mae: 284.4565 - val_loss: 319914.3125 - val_mse: 319914.3125 - val_mae: 295.9979 Epoch 92/300 683/683 [==============================] - 1s 1ms/step - loss: 263782.9375 - mse: 263782.9375 - mae: 280.2957 - val_loss: 319993.9062 - val_mse: 319993.9062 - val_mae: 299.9458 Epoch 93/300 683/683 [==============================] - 1s 1ms/step - loss: 266658.2812 - mse: 266658.2812 - mae: 281.5981 - val_loss: 319812.7812 - val_mse: 319812.7812 - val_mae: 305.4696 Epoch 94/300 683/683 [==============================] - 1s 1ms/step - loss: 262806.4688 - mse: 262806.4688 - mae: 278.9402 - val_loss: 314875.1875 - val_mse: 314875.1875 - val_mae: 290.6037 Epoch 95/300 683/683 [==============================] - 1s 1ms/step - loss: 261439.1094 - mse: 261439.1094 - mae: 278.2127 - val_loss: 334361.9062 - val_mse: 334361.9062 - val_mae: 297.4702 Epoch 96/300 683/683 [==============================] - 1s 1ms/step - loss: 263973.2812 - mse: 263973.2812 - mae: 281.4859 - val_loss: 314515.1562 - val_mse: 314515.1562 - val_mae: 294.4000 Epoch 97/300 683/683 [==============================] - 1s 1ms/step - loss: 264262.1250 - mse: 264262.1250 - mae: 279.8866 - val_loss: 316044.0938 - val_mse: 316044.0938 - val_mae: 303.6835 Epoch 98/300 683/683 [==============================] - 1s 1ms/step - loss: 261616.2188 - mse: 261616.2188 - mae: 279.1532 - val_loss: 318283.5312 - val_mse: 318283.5312 - val_mae: 297.6807 Epoch 99/300 683/683 [==============================] - 1s 1ms/step - loss: 263127.9062 - mse: 263127.9062 - mae: 279.7686 - val_loss: 333965.1250 - val_mse: 333965.1250 - val_mae: 293.9967 Epoch 100/300 683/683 [==============================] - 1s 1ms/step - loss: 261328.7500 - mse: 261328.7500 - mae: 278.4284 - val_loss: 313071.0000 - val_mse: 313071.0000 - val_mae: 292.8721 Epoch 101/300 683/683 [==============================] - 1s 1ms/step - loss: 260550.8906 - mse: 260550.8906 - mae: 277.3468 - val_loss: 327201.2500 - val_mse: 327201.2500 - val_mae: 295.6897 Epoch 102/300 683/683 [==============================] - 1s 1ms/step - loss: 262653.6562 - mse: 262653.6562 - mae: 279.3140 - val_loss: 304144.0938 - val_mse: 304144.0938 - val_mae: 291.3113 Epoch 103/300 683/683 [==============================] - 1s 1ms/step - loss: 261582.9062 - mse: 261582.9062 - mae: 279.0564 - val_loss: 318670.7188 - val_mse: 318670.7188 - val_mae: 308.2564 Epoch 104/300 683/683 [==============================] - 1s 1ms/step - loss: 261725.5469 - mse: 261725.5469 - mae: 280.4424 - val_loss: 350850.6250 - val_mse: 350850.6250 - val_mae: 301.5450 Epoch 105/300 683/683 [==============================] - 1s 1ms/step - loss: 260030.2188 - mse: 260030.2188 - mae: 276.3898 - val_loss: 321203.6875 - val_mse: 321203.6875 - val_mae: 297.9948 Epoch 106/300 683/683 [==============================] - 1s 1ms/step - loss: 265588.1250 - mse: 265588.1250 - mae: 281.2225 - val_loss: 307882.9062 - val_mse: 307882.9062 - val_mae: 292.1333 Epoch 107/300 683/683 [==============================] - 1s 1ms/step - loss: 259294.2500 - mse: 259294.2500 - mae: 276.9169 - val_loss: 310993.9688 - val_mse: 310993.9688 - val_mae: 292.7787 Epoch 108/300 683/683 [==============================] - 1s 1ms/step - loss: 257010.1719 - mse: 257010.1719 - mae: 275.8803 - val_loss: 338748.7812 - val_mse: 338748.7812 - val_mae: 317.0507 Epoch 109/300 683/683 [==============================] - 1s 1ms/step - loss: 263119.5000 - mse: 263119.5000 - mae: 278.9156 - val_loss: 333078.9062 - val_mse: 333078.9062 - val_mae: 308.0839 Epoch 110/300 683/683 [==============================] - 1s 1ms/step - loss: 257162.9375 - mse: 257162.9375 - mae: 275.7554 - val_loss: 354298.4688 - val_mse: 354298.4688 - val_mae: 293.5759 Epoch 111/300 683/683 [==============================] - 1s 1ms/step - loss: 261339.2188 - mse: 261339.2188 - mae: 278.0506 - val_loss: 326073.6562 - val_mse: 326073.6562 - val_mae: 306.4803 Epoch 112/300 683/683 [==============================] - 1s 1ms/step - loss: 259393.2656 - mse: 259393.2656 - mae: 276.4886 - val_loss: 316279.5312 - val_mse: 316279.5312 - val_mae: 299.7885 Epoch 113/300 683/683 [==============================] - 1s 1ms/step - loss: 260794.5156 - mse: 260794.5156 - mae: 277.9420 - val_loss: 334160.9688 - val_mse: 334160.9688 - val_mae: 310.0470 Epoch 114/300 683/683 [==============================] - 1s 1ms/step - loss: 256435.0469 - mse: 256435.0469 - mae: 276.0122 - val_loss: 320445.2188 - val_mse: 320445.2188 - val_mae: 300.8437 Epoch 115/300 683/683 [==============================] - 1s 1ms/step - loss: 258968.4375 - mse: 258968.4375 - mae: 276.8819 - val_loss: 315573.5312 - val_mse: 315573.5312 - val_mae: 300.7139 Epoch 116/300 683/683 [==============================] - 1s 1ms/step - loss: 255871.3125 - mse: 255871.3125 - mae: 274.2761 - val_loss: 309150.3125 - val_mse: 309150.3125 - val_mae: 288.1886 Epoch 117/300 683/683 [==============================] - 1s 1ms/step - loss: 257688.7969 - mse: 257688.7969 - mae: 275.8790 - val_loss: 315062.9688 - val_mse: 315062.9688 - val_mae: 289.6511 Epoch 118/300 683/683 [==============================] - 1s 1ms/step - loss: 253724.8438 - mse: 253724.8438 - mae: 275.1425 - val_loss: 312962.0938 - val_mse: 312962.0938 - val_mae: 298.4130 Epoch 119/300 683/683 [==============================] - 1s 1ms/step - loss: 259612.4062 - mse: 259612.4062 - mae: 278.4340 - val_loss: 313071.7500 - val_mse: 313071.7500 - val_mae: 290.6206 Epoch 120/300 683/683 [==============================] - 1s 1ms/step - loss: 253693.2031 - mse: 253693.2031 - mae: 273.6717 - val_loss: 315186.5000 - val_mse: 315186.5000 - val_mae: 295.6978 Epoch 121/300 683/683 [==============================] - 1s 1ms/step - loss: 257789.0938 - mse: 257789.0938 - mae: 276.5661 - val_loss: 315213.2500 - val_mse: 315213.2500 - val_mae: 294.2330 Epoch 122/300 683/683 [==============================] - 1s 1ms/step - loss: 252772.7188 - mse: 252772.7188 - mae: 274.1848 - val_loss: 315124.2500 - val_mse: 315124.2500 - val_mae: 297.0435 Epoch 123/300 683/683 [==============================] - 1s 1ms/step - loss: 254773.5781 - mse: 254773.5781 - mae: 274.5056 - val_loss: 320641.0938 - val_mse: 320641.0938 - val_mae: 295.7010 Epoch 124/300 683/683 [==============================] - 1s 1ms/step - loss: 252977.8438 - mse: 252977.8438 - mae: 273.8867 - val_loss: 362708.2188 - val_mse: 362708.2188 - val_mae: 305.9572 Epoch 125/300 683/683 [==============================] - 1s 1ms/step - loss: 254364.2969 - mse: 254364.2969 - mae: 274.2276 - val_loss: 317210.0312 - val_mse: 317210.0312 - val_mae: 295.9097 Epoch 126/300 683/683 [==============================] - 1s 1ms/step - loss: 253429.8125 - mse: 253429.8125 - mae: 274.1838 - val_loss: 318451.6562 - val_mse: 318451.6562 - val_mae: 290.1588 Epoch 127/300 683/683 [==============================] - 1s 1ms/step - loss: 254107.2500 - mse: 254107.2500 - mae: 273.9864 - val_loss: 307646.4062 - val_mse: 307646.4062 - val_mae: 290.9198 Epoch 128/300 683/683 [==============================] - 1s 1ms/step - loss: 256061.8594 - mse: 256061.8594 - mae: 274.0624 - val_loss: 309531.5625 - val_mse: 309531.5625 - val_mae: 294.4833 Epoch 129/300 683/683 [==============================] - 1s 1ms/step - loss: 250209.2656 - mse: 250209.2656 - mae: 271.4409 - val_loss: 302537.0938 - val_mse: 302537.0938 - val_mae: 285.6717 Epoch 130/300 683/683 [==============================] - 1s 2ms/step - loss: 248839.4531 - mse: 248839.4531 - mae: 271.7486 - val_loss: 306423.3125 - val_mse: 306423.3125 - val_mae: 288.5693 Epoch 131/300 683/683 [==============================] - 1s 2ms/step - loss: 252317.1875 - mse: 252317.1875 - mae: 272.5187 - val_loss: 316530.0625 - val_mse: 316530.0625 - val_mae: 296.3860 Epoch 132/300 683/683 [==============================] - 1s 1ms/step - loss: 258675.7969 - mse: 258675.7969 - mae: 276.4403 - val_loss: 316493.6875 - val_mse: 316493.6875 - val_mae: 290.1728 Epoch 133/300 683/683 [==============================] - 1s 1ms/step - loss: 259711.6719 - mse: 259711.6719 - mae: 277.7692 - val_loss: 313218.4375 - val_mse: 313218.4375 - val_mae: 290.5186 Epoch 134/300 683/683 [==============================] - 1s 1ms/step - loss: 252167.0781 - mse: 252167.0781 - mae: 274.3972 - val_loss: 318164.3438 - val_mse: 318164.3438 - val_mae: 292.5639 Epoch 135/300 683/683 [==============================] - 1s 1ms/step - loss: 253255.1562 - mse: 253255.1562 - mae: 274.2767 - val_loss: 329581.5000 - val_mse: 329581.5000 - val_mae: 307.2596 Epoch 136/300 683/683 [==============================] - 1s 1ms/step - loss: 254539.9844 - mse: 254539.9844 - mae: 275.0254 - val_loss: 330229.7812 - val_mse: 330229.7812 - val_mae: 301.9674 Epoch 137/300 683/683 [==============================] - 1s 1ms/step - loss: 252205.4844 - mse: 252205.4844 - mae: 273.3736 - val_loss: 315604.3750 - val_mse: 315604.3750 - val_mae: 292.6425 Epoch 138/300 683/683 [==============================] - 1s 1ms/step - loss: 249668.1875 - mse: 249668.1875 - mae: 272.0547 - val_loss: 325387.0625 - val_mse: 325387.0625 - val_mae: 293.9693 Epoch 139/300 683/683 [==============================] - 1s 1ms/step - loss: 254645.2656 - mse: 254645.2656 - mae: 275.2983 - val_loss: 316499.6562 - val_mse: 316499.6562 - val_mae: 291.2850 Epoch 140/300 683/683 [==============================] - 1s 1ms/step - loss: 249236.2031 - mse: 249236.2031 - mae: 271.0164 - val_loss: 352616.6250 - val_mse: 352616.6250 - val_mae: 308.7262 Epoch 141/300 683/683 [==============================] - 1s 2ms/step - loss: 248436.6562 - mse: 248436.6562 - mae: 270.8840 - val_loss: 314944.8750 - val_mse: 314944.8750 - val_mae: 290.9767 Epoch 142/300 683/683 [==============================] - 1s 1ms/step - loss: 252095.2656 - mse: 252095.2656 - mae: 274.0056 - val_loss: 319681.2812 - val_mse: 319681.2812 - val_mae: 292.6295 Epoch 143/300 683/683 [==============================] - 1s 1ms/step - loss: 247569.7656 - mse: 247569.7656 - mae: 270.0536 - val_loss: 338158.5312 - val_mse: 338158.5312 - val_mae: 312.4109 Epoch 144/300 683/683 [==============================] - 1s 1ms/step - loss: 249286.1562 - mse: 249286.1562 - mae: 272.4767 - val_loss: 319621.0312 - val_mse: 319621.0312 - val_mae: 304.6506 Epoch 145/300 683/683 [==============================] - 1s 1ms/step - loss: 249167.3750 - mse: 249167.3750 - mae: 272.2278 - val_loss: 331929.7812 - val_mse: 331929.7812 - val_mae: 303.1768 Epoch 146/300 683/683 [==============================] - 1s 1ms/step - loss: 251649.8438 - mse: 251649.8438 - mae: 274.0349 - val_loss: 315177.4688 - val_mse: 315177.4688 - val_mae: 286.2098 Epoch 147/300 683/683 [==============================] - 1s 1ms/step - loss: 248627.0000 - mse: 248627.0000 - mae: 271.9280 - val_loss: 329259.3438 - val_mse: 329259.3438 - val_mae: 305.4430 Epoch 148/300 683/683 [==============================] - 1s 1ms/step - loss: 248948.7812 - mse: 248948.7812 - mae: 271.9755 - val_loss: 345954.1562 - val_mse: 345954.1562 - val_mae: 317.6905 Epoch 149/300 683/683 [==============================] - 1s 1ms/step - loss: 246857.9375 - mse: 246857.9375 - mae: 269.6838 - val_loss: 314972.0000 - val_mse: 314972.0000 - val_mae: 292.2326 Epoch 150/300 683/683 [==============================] - 1s 1ms/step - loss: 249985.6250 - mse: 249985.6250 - mae: 271.4827 - val_loss: 319609.7500 - val_mse: 319609.7500 - val_mae: 286.9010 Epoch 151/300 683/683 [==============================] - 1s 1ms/step - loss: 243357.1719 - mse: 243357.1719 - mae: 268.4497 - val_loss: 318571.5625 - val_mse: 318571.5625 - val_mae: 291.9767 Epoch 152/300 683/683 [==============================] - 1s 1ms/step - loss: 247645.4844 - mse: 247645.4844 - mae: 269.7993 - val_loss: 324182.5312 - val_mse: 324182.5312 - val_mae: 295.8463 Epoch 153/300 683/683 [==============================] - 1s 1ms/step - loss: 246109.1406 - mse: 246109.1406 - mae: 269.8534 - val_loss: 339558.5938 - val_mse: 339558.5938 - val_mae: 311.5548 Epoch 154/300 683/683 [==============================] - 1s 1ms/step - loss: 247576.4375 - mse: 247576.4375 - mae: 270.5987 - val_loss: 318896.0000 - val_mse: 318896.0000 - val_mae: 294.0548 Epoch 155/300 683/683 [==============================] - 1s 1ms/step - loss: 247465.4688 - mse: 247465.4688 - mae: 270.0030 - val_loss: 312330.5625 - val_mse: 312330.5625 - val_mae: 292.2295 Epoch 156/300 683/683 [==============================] - 1s 1ms/step - loss: 248768.1250 - mse: 248768.1250 - mae: 271.0235 - val_loss: 384530.2188 - val_mse: 384530.2188 - val_mae: 345.7037 Epoch 157/300 683/683 [==============================] - 1s 1ms/step - loss: 244160.7500 - mse: 244160.7500 - mae: 268.0226 - val_loss: 372642.2812 - val_mse: 372642.2812 - val_mae: 313.5063 Epoch 158/300 683/683 [==============================] - 1s 1ms/step - loss: 248490.6406 - mse: 248490.6406 - mae: 270.8886 - val_loss: 303072.9062 - val_mse: 303072.9062 - val_mae: 287.3441 Epoch 159/300 683/683 [==============================] - 1s 1ms/step - loss: 245467.7344 - mse: 245467.7344 - mae: 269.4306 - val_loss: 319736.0938 - val_mse: 319736.0938 - val_mae: 288.3324 Epoch 160/300 683/683 [==============================] - 1s 1ms/step - loss: 246424.1875 - mse: 246424.1875 - mae: 269.9847 - val_loss: 309679.7812 - val_mse: 309679.7812 - val_mae: 296.4565 Epoch 161/300 683/683 [==============================] - 1s 1ms/step - loss: 244676.0312 - mse: 244676.0312 - mae: 268.6508 - val_loss: 336826.4375 - val_mse: 336826.4375 - val_mae: 306.8008 Epoch 162/300 683/683 [==============================] - 1s 1ms/step - loss: 247098.1250 - mse: 247098.1250 - mae: 271.1660 - val_loss: 319512.1250 - val_mse: 319512.1250 - val_mae: 286.5699 Epoch 163/300 683/683 [==============================] - 1s 1ms/step - loss: 242956.2188 - mse: 242956.2188 - mae: 268.0307 - val_loss: 317167.1250 - val_mse: 317167.1250 - val_mae: 296.5664 Epoch 164/300 683/683 [==============================] - 1s 1ms/step - loss: 244242.6719 - mse: 244242.6719 - mae: 268.8619 - val_loss: 329820.4688 - val_mse: 329820.4688 - val_mae: 306.1717 Epoch 165/300 683/683 [==============================] - 1s 1ms/step - loss: 240879.0312 - mse: 240879.0312 - mae: 267.7017 - val_loss: 327640.2188 - val_mse: 327640.2188 - val_mae: 291.0319 Epoch 166/300 683/683 [==============================] - 1s 1ms/step - loss: 243739.4219 - mse: 243739.4219 - mae: 269.2430 - val_loss: 329031.2188 - val_mse: 329031.2188 - val_mae: 291.9590 Epoch 167/300 683/683 [==============================] - 1s 1ms/step - loss: 243671.9844 - mse: 243671.9844 - mae: 267.5234 - val_loss: 325099.5625 - val_mse: 325099.5625 - val_mae: 302.7737 Epoch 168/300 683/683 [==============================] - 1s 1ms/step - loss: 246554.4062 - mse: 246554.4062 - mae: 270.2893 - val_loss: 379217.5938 - val_mse: 379217.5938 - val_mae: 324.0022 Epoch 169/300 683/683 [==============================] - 1s 1ms/step - loss: 237888.1719 - mse: 237888.1719 - mae: 263.8567 - val_loss: 307622.3125 - val_mse: 307622.3125 - val_mae: 287.1323 Epoch 170/300 683/683 [==============================] - 1s 1ms/step - loss: 240794.2188 - mse: 240794.2188 - mae: 266.8419 - val_loss: 312645.6250 - val_mse: 312645.6250 - val_mae: 289.5103 Epoch 171/300 683/683 [==============================] - 1s 1ms/step - loss: 242307.8750 - mse: 242307.8750 - mae: 267.1944 - val_loss: 313593.2812 - val_mse: 313593.2812 - val_mae: 293.2375 Epoch 172/300 683/683 [==============================] - 1s 1ms/step - loss: 244112.0938 - mse: 244112.0938 - mae: 268.6949 - val_loss: 346422.2812 - val_mse: 346422.2812 - val_mae: 307.1208 Epoch 173/300 683/683 [==============================] - 1s 1ms/step - loss: 242837.2812 - mse: 242837.2812 - mae: 268.5412 - val_loss: 309802.9062 - val_mse: 309802.9062 - val_mae: 290.0832 Epoch 174/300 683/683 [==============================] - 1s 1ms/step - loss: 240795.8125 - mse: 240795.8125 - mae: 267.5214 - val_loss: 319809.9688 - val_mse: 319809.9688 - val_mae: 293.8436 Epoch 175/300 683/683 [==============================] - 1s 1ms/step - loss: 239799.9062 - mse: 239799.9062 - mae: 266.5628 - val_loss: 324781.0000 - val_mse: 324781.0000 - val_mae: 296.3907 Epoch 176/300 683/683 [==============================] - 1s 1ms/step - loss: 243081.7188 - mse: 243081.7188 - mae: 267.6091 - val_loss: 324830.6562 - val_mse: 324830.6562 - val_mae: 298.8953 Epoch 177/300 683/683 [==============================] - 1s 1ms/step - loss: 240100.7500 - mse: 240100.7500 - mae: 266.3600 - val_loss: 325067.5938 - val_mse: 325067.5938 - val_mae: 296.2301 Epoch 178/300 683/683 [==============================] - 1s 1ms/step - loss: 238453.4531 - mse: 238453.4531 - mae: 265.2646 - val_loss: 318662.5938 - val_mse: 318662.5938 - val_mae: 291.3996 Epoch 179/300 683/683 [==============================] - 1s 1ms/step - loss: 237133.4688 - mse: 237133.4688 - mae: 264.7181 - val_loss: 330044.7500 - val_mse: 330044.7500 - val_mae: 289.6452 Epoch 180/300 683/683 [==============================] - 1s 1ms/step - loss: 239745.7188 - mse: 239745.7188 - mae: 268.1479 - val_loss: 331453.3125 - val_mse: 331453.3125 - val_mae: 302.9839 Epoch 181/300 683/683 [==============================] - 1s 1ms/step - loss: 238746.0781 - mse: 238746.0781 - mae: 265.2184 - val_loss: 328028.2500 - val_mse: 328028.2500 - val_mae: 293.6505 Epoch 182/300 683/683 [==============================] - 1s 1ms/step - loss: 237969.0469 - mse: 237969.0469 - mae: 264.9678 - val_loss: 327873.0938 - val_mse: 327873.0938 - val_mae: 301.0755 Epoch 183/300 683/683 [==============================] - 1s 2ms/step - loss: 239010.5000 - mse: 239010.5000 - mae: 267.5696 - val_loss: 316136.2188 - val_mse: 316136.2188 - val_mae: 290.5764 Epoch 184/300 683/683 [==============================] - 1s 1ms/step - loss: 239102.8906 - mse: 239102.8906 - mae: 266.1927 - val_loss: 342726.9688 - val_mse: 342726.9688 - val_mae: 308.8017 Epoch 185/300 683/683 [==============================] - 1s 1ms/step - loss: 236049.7969 - mse: 236049.7969 - mae: 264.6142 - val_loss: 318345.0312 - val_mse: 318345.0312 - val_mae: 292.3081 Epoch 186/300 683/683 [==============================] - 1s 1ms/step - loss: 233989.5000 - mse: 233989.5000 - mae: 263.1669 - val_loss: 330552.0312 - val_mse: 330552.0312 - val_mae: 294.7944 Epoch 187/300 683/683 [==============================] - 1s 1ms/step - loss: 240144.0000 - mse: 240144.0000 - mae: 268.8177 - val_loss: 398766.8750 - val_mse: 398766.8750 - val_mae: 330.7056 Epoch 188/300 683/683 [==============================] - 1s 1ms/step - loss: 238614.6875 - mse: 238614.6875 - mae: 266.2303 - val_loss: 315421.4688 - val_mse: 315421.4688 - val_mae: 294.1631 Epoch 189/300 683/683 [==============================] - 1s 1ms/step - loss: 237522.2656 - mse: 237522.2656 - mae: 265.6988 - val_loss: 325328.7500 - val_mse: 325328.7500 - val_mae: 288.5888 Epoch 190/300 683/683 [==============================] - 1s 1ms/step - loss: 237870.2031 - mse: 237870.2031 - mae: 265.3958 - val_loss: 318737.8438 - val_mse: 318737.8438 - val_mae: 294.9449 Epoch 191/300 683/683 [==============================] - 1s 1ms/step - loss: 238063.4844 - mse: 238063.4844 - mae: 264.9331 - val_loss: 315241.6562 - val_mse: 315241.6562 - val_mae: 291.6031 Epoch 192/300 683/683 [==============================] - 1s 1ms/step - loss: 238009.1406 - mse: 238009.1406 - mae: 265.5050 - val_loss: 368024.7500 - val_mse: 368024.7500 - val_mae: 324.9869 Epoch 193/300 683/683 [==============================] - 1s 1ms/step - loss: 235795.0469 - mse: 235795.0469 - mae: 264.9696 - val_loss: 315103.8438 - val_mse: 315103.8438 - val_mae: 292.0537 Epoch 194/300 683/683 [==============================] - 1s 1ms/step - loss: 236416.0312 - mse: 236416.0312 - mae: 265.5388 - val_loss: 321999.4375 - val_mse: 321999.4375 - val_mae: 293.9460 Epoch 195/300 683/683 [==============================] - 1s 1ms/step - loss: 234873.2031 - mse: 234873.2031 - mae: 263.3706 - val_loss: 311939.0000 - val_mse: 311939.0000 - val_mae: 288.6151 Epoch 196/300 683/683 [==============================] - 1s 1ms/step - loss: 234328.6562 - mse: 234328.6562 - mae: 264.2634 - val_loss: 324735.6875 - val_mse: 324735.6875 - val_mae: 291.1252 Epoch 197/300 683/683 [==============================] - 1s 2ms/step - loss: 235439.1562 - mse: 235439.1562 - mae: 265.0031 - val_loss: 323742.1562 - val_mse: 323742.1562 - val_mae: 300.8357 Epoch 198/300 683/683 [==============================] - 1s 1ms/step - loss: 233634.6875 - mse: 233634.6875 - mae: 263.6290 - val_loss: 360827.5312 - val_mse: 360827.5312 - val_mae: 324.8114 Epoch 199/300 683/683 [==============================] - 1s 1ms/step - loss: 230987.2812 - mse: 230987.2812 - mae: 263.1795 - val_loss: 307492.6562 - val_mse: 307492.6562 - val_mae: 289.9847 Epoch 200/300 683/683 [==============================] - 1s 1ms/step - loss: 234649.5469 - mse: 234649.5469 - mae: 264.2585 - val_loss: 331327.7500 - val_mse: 331327.7500 - val_mae: 291.7809 Epoch 201/300 683/683 [==============================] - 1s 1ms/step - loss: 233876.0625 - mse: 233876.0625 - mae: 263.4013 - val_loss: 315331.7188 - val_mse: 315331.7188 - val_mae: 290.0981 Epoch 202/300 683/683 [==============================] - 1s 1ms/step - loss: 234308.0156 - mse: 234308.0156 - mae: 265.5008 - val_loss: 313116.8750 - val_mse: 313116.8750 - val_mae: 290.7409 Epoch 203/300 683/683 [==============================] - 1s 1ms/step - loss: 231922.2969 - mse: 231922.2969 - mae: 263.3418 - val_loss: 330799.8438 - val_mse: 330799.8438 - val_mae: 293.1941 Epoch 204/300 683/683 [==============================] - 1s 1ms/step - loss: 234520.8906 - mse: 234520.8906 - mae: 263.8803 - val_loss: 335989.1562 - val_mse: 335989.1562 - val_mae: 292.9513 Epoch 205/300 683/683 [==============================] - 1s 1ms/step - loss: 233283.7656 - mse: 233283.7656 - mae: 263.2875 - val_loss: 319494.0938 - val_mse: 319494.0938 - val_mae: 293.6731 Epoch 206/300 683/683 [==============================] - 1s 1ms/step - loss: 230865.5312 - mse: 230865.5312 - mae: 261.6255 - val_loss: 314722.0000 - val_mse: 314722.0000 - val_mae: 291.7632 Epoch 207/300 683/683 [==============================] - 1s 1ms/step - loss: 231601.2188 - mse: 231601.2188 - mae: 263.9325 - val_loss: 332109.0000 - val_mse: 332109.0000 - val_mae: 303.3210 Epoch 208/300 683/683 [==============================] - 1s 1ms/step - loss: 236821.8594 - mse: 236821.8594 - mae: 266.9368 - val_loss: 351583.2812 - val_mse: 351583.2812 - val_mae: 318.0450 Epoch 209/300 683/683 [==============================] - 1s 1ms/step - loss: 229941.9219 - mse: 229941.9219 - mae: 261.3749 - val_loss: 347424.7188 - val_mse: 347424.7188 - val_mae: 300.4833 Epoch 210/300 683/683 [==============================] - 1s 1ms/step - loss: 231124.1562 - mse: 231124.1562 - mae: 263.4935 - val_loss: 316584.6562 - val_mse: 316584.6562 - val_mae: 291.6676 Epoch 211/300 683/683 [==============================] - 1s 1ms/step - loss: 229895.3906 - mse: 229895.3906 - mae: 261.7680 - val_loss: 324049.4688 - val_mse: 324049.4688 - val_mae: 296.7806 Epoch 212/300 683/683 [==============================] - 1s 1ms/step - loss: 230764.5469 - mse: 230764.5469 - mae: 262.3957 - val_loss: 319640.0938 - val_mse: 319640.0938 - val_mae: 297.5267 Epoch 213/300 683/683 [==============================] - 1s 1ms/step - loss: 231508.3594 - mse: 231508.3594 - mae: 263.4590 - val_loss: 315110.7500 - val_mse: 315110.7500 - val_mae: 294.1516 Epoch 214/300 683/683 [==============================] - 1s 1ms/step - loss: 234441.8906 - mse: 234441.8906 - mae: 264.4696 - val_loss: 319204.4688 - val_mse: 319204.4688 - val_mae: 293.0650 Epoch 215/300 683/683 [==============================] - 1s 1ms/step - loss: 231499.3906 - mse: 231499.3906 - mae: 262.3961 - val_loss: 330151.6250 - val_mse: 330151.6250 - val_mae: 298.8980 Epoch 216/300 683/683 [==============================] - 1s 1ms/step - loss: 226845.8125 - mse: 226845.8125 - mae: 260.8755 - val_loss: 321445.0625 - val_mse: 321445.0625 - val_mae: 296.2092 Epoch 217/300 683/683 [==============================] - 1s 1ms/step - loss: 227694.9844 - mse: 227694.9844 - mae: 261.3324 - val_loss: 373237.4688 - val_mse: 373237.4688 - val_mae: 339.5027 Epoch 218/300 683/683 [==============================] - 1s 2ms/step - loss: 230139.2656 - mse: 230139.2656 - mae: 261.8775 - val_loss: 331616.1562 - val_mse: 331616.1562 - val_mae: 308.6748 Epoch 219/300 683/683 [==============================] - 1s 1ms/step - loss: 230345.6094 - mse: 230345.6094 - mae: 262.5209 - val_loss: 322574.0625 - val_mse: 322574.0625 - val_mae: 291.1911 Epoch 220/300 683/683 [==============================] - 1s 2ms/step - loss: 234833.6562 - mse: 234833.6562 - mae: 265.7259 - val_loss: 332378.0312 - val_mse: 332378.0312 - val_mae: 298.6258 Epoch 221/300 683/683 [==============================] - 1s 2ms/step - loss: 229788.7656 - mse: 229788.7656 - mae: 262.5352 - val_loss: 320583.8750 - val_mse: 320583.8750 - val_mae: 297.7886 Epoch 222/300 683/683 [==============================] - 1s 2ms/step - loss: 229295.7188 - mse: 229295.7188 - mae: 262.8520 - val_loss: 324690.1562 - val_mse: 324690.1562 - val_mae: 296.3268 Epoch 223/300 683/683 [==============================] - 1s 2ms/step - loss: 229703.9219 - mse: 229703.9219 - mae: 262.4504 - val_loss: 326312.8125 - val_mse: 326312.8125 - val_mae: 294.2664 Epoch 224/300 683/683 [==============================] - 1s 1ms/step - loss: 226453.7031 - mse: 226453.7031 - mae: 261.2796 - val_loss: 311089.9062 - val_mse: 311089.9062 - val_mae: 292.6800 Epoch 225/300 683/683 [==============================] - 1s 1ms/step - loss: 224966.2344 - mse: 224966.2344 - mae: 258.3442 - val_loss: 319410.4375 - val_mse: 319410.4375 - val_mae: 291.8418 Epoch 226/300 683/683 [==============================] - 1s 1ms/step - loss: 230568.0469 - mse: 230568.0469 - mae: 262.9463 - val_loss: 321605.1562 - val_mse: 321605.1562 - val_mae: 292.4710 Epoch 227/300 683/683 [==============================] - 1s 1ms/step - loss: 226570.5469 - mse: 226570.5469 - mae: 260.3956 - val_loss: 322775.1562 - val_mse: 322775.1562 - val_mae: 294.1214 Epoch 228/300 683/683 [==============================] - 1s 1ms/step - loss: 228336.8281 - mse: 228336.8281 - mae: 261.2844 - val_loss: 318103.1875 - val_mse: 318103.1875 - val_mae: 295.7575 Epoch 229/300 683/683 [==============================] - 1s 2ms/step - loss: 224043.0156 - mse: 224043.0156 - mae: 259.7840 - val_loss: 319289.0000 - val_mse: 319289.0000 - val_mae: 292.1557 Epoch 230/300 683/683 [==============================] - 1s 2ms/step - loss: 224701.6094 - mse: 224701.6094 - mae: 260.9535 - val_loss: 326501.6250 - val_mse: 326501.6250 - val_mae: 295.5091 Epoch 231/300 683/683 [==============================] - 1s 1ms/step - loss: 228988.7500 - mse: 228988.7500 - mae: 262.3162 - val_loss: 324963.4375 - val_mse: 324963.4375 - val_mae: 295.7687 Epoch 232/300 683/683 [==============================] - 1s 1ms/step - loss: 227417.9688 - mse: 227417.9688 - mae: 262.6385 - val_loss: 317112.2188 - val_mse: 317112.2188 - val_mae: 290.6240 Epoch 233/300 683/683 [==============================] - 1s 1ms/step - loss: 221404.6250 - mse: 221404.6250 - mae: 256.9697 - val_loss: 345369.7188 - val_mse: 345369.7188 - val_mae: 296.8222 Epoch 234/300 683/683 [==============================] - 1s 1ms/step - loss: 226915.4062 - mse: 226915.4062 - mae: 260.5221 - val_loss: 357301.7188 - val_mse: 357301.7188 - val_mae: 298.8837 Epoch 235/300 683/683 [==============================] - 1s 1ms/step - loss: 226922.7812 - mse: 226922.7812 - mae: 261.6121 - val_loss: 330035.2812 - val_mse: 330035.2812 - val_mae: 293.5409 Epoch 236/300 683/683 [==============================] - 1s 1ms/step - loss: 225463.3438 - mse: 225463.3438 - mae: 259.9837 - val_loss: 321573.4688 - val_mse: 321573.4688 - val_mae: 300.3592 Epoch 237/300 683/683 [==============================] - 1s 1ms/step - loss: 219638.9688 - mse: 219638.9688 - mae: 257.1601 - val_loss: 336701.4688 - val_mse: 336701.4688 - val_mae: 304.7694 Epoch 238/300 683/683 [==============================] - 1s 1ms/step - loss: 224494.4062 - mse: 224494.4062 - mae: 259.1663 - val_loss: 330598.5312 - val_mse: 330598.5312 - val_mae: 299.1254 Epoch 239/300 683/683 [==============================] - 1s 1ms/step - loss: 222012.2812 - mse: 222012.2812 - mae: 258.6867 - val_loss: 342209.4062 - val_mse: 342209.4062 - val_mae: 294.7746 Epoch 240/300 683/683 [==============================] - 1s 1ms/step - loss: 223869.5938 - mse: 223869.5938 - mae: 259.9234 - val_loss: 331262.8438 - val_mse: 331262.8438 - val_mae: 307.0318 Epoch 241/300 683/683 [==============================] - 1s 1ms/step - loss: 227580.4688 - mse: 227580.4688 - mae: 262.3178 - val_loss: 326530.9062 - val_mse: 326530.9062 - val_mae: 293.3021 Epoch 242/300 683/683 [==============================] - 1s 1ms/step - loss: 224539.1562 - mse: 224539.1562 - mae: 259.7239 - val_loss: 389608.9375 - val_mse: 389608.9375 - val_mae: 320.5471 Epoch 243/300 683/683 [==============================] - 1s 1ms/step - loss: 218508.6094 - mse: 218508.6094 - mae: 258.6673 - val_loss: 314408.4375 - val_mse: 314408.4375 - val_mae: 293.1385 Epoch 244/300 683/683 [==============================] - 1s 1ms/step - loss: 221680.2812 - mse: 221680.2812 - mae: 258.6898 - val_loss: 344316.1562 - val_mse: 344316.1562 - val_mae: 314.3919 Epoch 245/300 683/683 [==============================] - 1s 1ms/step - loss: 221686.2656 - mse: 221686.2656 - mae: 259.0364 - val_loss: 317032.6250 - val_mse: 317032.6250 - val_mae: 294.3319 Epoch 246/300 683/683 [==============================] - 1s 1ms/step - loss: 222438.1250 - mse: 222438.1250 - mae: 257.5395 - val_loss: 326619.1562 - val_mse: 326619.1562 - val_mae: 298.2320 Epoch 247/300 683/683 [==============================] - 1s 2ms/step - loss: 222145.7656 - mse: 222145.7656 - mae: 260.2728 - val_loss: 323361.0000 - val_mse: 323361.0000 - val_mae: 295.3570 Epoch 248/300 683/683 [==============================] - 1s 1ms/step - loss: 222334.3281 - mse: 222334.3281 - mae: 258.8281 - val_loss: 329342.5312 - val_mse: 329342.5312 - val_mae: 300.9589 Epoch 249/300 683/683 [==============================] - 1s 1ms/step - loss: 221140.2656 - mse: 221140.2656 - mae: 258.4786 - val_loss: 317744.3438 - val_mse: 317744.3438 - val_mae: 294.8520 Epoch 250/300 683/683 [==============================] - 1s 1ms/step - loss: 219874.5781 - mse: 219874.5781 - mae: 256.7529 - val_loss: 320852.5000 - val_mse: 320852.5000 - val_mae: 296.2648 Epoch 251/300 683/683 [==============================] - 1s 1ms/step - loss: 221500.8906 - mse: 221500.8906 - mae: 259.4411 - val_loss: 324074.5938 - val_mse: 324074.5938 - val_mae: 297.8997 Epoch 252/300 683/683 [==============================] - 1s 1ms/step - loss: 222766.6406 - mse: 222766.6406 - mae: 258.7282 - val_loss: 325791.3438 - val_mse: 325791.3438 - val_mae: 299.6815 Epoch 253/300 683/683 [==============================] - 1s 1ms/step - loss: 221904.0156 - mse: 221904.0156 - mae: 259.1252 - val_loss: 326322.2500 - val_mse: 326322.2500 - val_mae: 294.8628 Epoch 254/300 683/683 [==============================] - 1s 1ms/step - loss: 223081.5000 - mse: 223081.5000 - mae: 259.3542 - val_loss: 333399.3125 - val_mse: 333399.3125 - val_mae: 295.2879 Epoch 255/300 683/683 [==============================] - 1s 1ms/step - loss: 219567.8594 - mse: 219567.8594 - mae: 257.8861 - val_loss: 322648.7188 - val_mse: 322648.7188 - val_mae: 293.8795 Epoch 256/300 683/683 [==============================] - 1s 1ms/step - loss: 221493.0938 - mse: 221493.0938 - mae: 260.0973 - val_loss: 325666.6875 - val_mse: 325666.6875 - val_mae: 291.6931 Epoch 257/300 683/683 [==============================] - 1s 1ms/step - loss: 218678.7031 - mse: 218678.7031 - mae: 257.1678 - val_loss: 315611.8438 - val_mse: 315611.8438 - val_mae: 292.7763 Epoch 258/300 683/683 [==============================] - 1s 1ms/step - loss: 219097.1406 - mse: 219097.1406 - mae: 258.3428 - val_loss: 326643.5938 - val_mse: 326643.5938 - val_mae: 306.8564 Epoch 259/300 683/683 [==============================] - 1s 1ms/step - loss: 218547.2344 - mse: 218547.2344 - mae: 257.8393 - val_loss: 330103.6562 - val_mse: 330103.6562 - val_mae: 301.8471 Epoch 260/300 683/683 [==============================] - 1s 1ms/step - loss: 220009.0625 - mse: 220009.0625 - mae: 257.6576 - val_loss: 327524.0938 - val_mse: 327524.0938 - val_mae: 293.6712 Epoch 261/300 683/683 [==============================] - 1s 1ms/step - loss: 217144.0781 - mse: 217144.0781 - mae: 256.5927 - val_loss: 330045.3750 - val_mse: 330045.3750 - val_mae: 299.1945 Epoch 262/300 683/683 [==============================] - 1s 1ms/step - loss: 218799.0000 - mse: 218799.0000 - mae: 257.4108 - val_loss: 340358.5000 - val_mse: 340358.5000 - val_mae: 300.7191 Epoch 263/300 683/683 [==============================] - 1s 1ms/step - loss: 216857.1250 - mse: 216857.1250 - mae: 255.6308 - val_loss: 322186.2188 - val_mse: 322186.2188 - val_mae: 293.6117 Epoch 264/300 683/683 [==============================] - 1s 1ms/step - loss: 215736.5469 - mse: 215736.5469 - mae: 256.2198 - val_loss: 330762.0625 - val_mse: 330762.0625 - val_mae: 303.2274 Epoch 265/300 683/683 [==============================] - 1s 1ms/step - loss: 220834.7969 - mse: 220834.7969 - mae: 259.3272 - val_loss: 324420.6562 - val_mse: 324420.6562 - val_mae: 301.5763 Epoch 266/300 683/683 [==============================] - 1s 1ms/step - loss: 213649.0938 - mse: 213649.0938 - mae: 254.7285 - val_loss: 321566.8438 - val_mse: 321566.8438 - val_mae: 292.6199 Epoch 267/300 683/683 [==============================] - 1s 1ms/step - loss: 216613.4688 - mse: 216613.4688 - mae: 256.0401 - val_loss: 351091.8750 - val_mse: 351091.8750 - val_mae: 311.4252 Epoch 268/300 683/683 [==============================] - 1s 2ms/step - loss: 216403.7188 - mse: 216403.7188 - mae: 256.6718 - val_loss: 338129.0312 - val_mse: 338129.0312 - val_mae: 295.7360 Epoch 269/300 683/683 [==============================] - 1s 1ms/step - loss: 219325.6406 - mse: 219325.6406 - mae: 257.6091 - val_loss: 320166.3750 - val_mse: 320166.3750 - val_mae: 293.4935 Epoch 270/300 683/683 [==============================] - 1s 1ms/step - loss: 216817.0312 - mse: 216817.0312 - mae: 255.0081 - val_loss: 330971.9062 - val_mse: 330971.9062 - val_mae: 301.4047 Epoch 271/300 683/683 [==============================] - 1s 1ms/step - loss: 217477.1250 - mse: 217477.1250 - mae: 258.1442 - val_loss: 315130.1562 - val_mse: 315130.1562 - val_mae: 295.7966 Epoch 272/300 683/683 [==============================] - 1s 1ms/step - loss: 217618.6719 - mse: 217618.6719 - mae: 257.5927 - val_loss: 319189.6875 - val_mse: 319189.6875 - val_mae: 294.6176 Epoch 273/300 683/683 [==============================] - 1s 1ms/step - loss: 214368.7188 - mse: 214368.7188 - mae: 254.7816 - val_loss: 321217.5938 - val_mse: 321217.5938 - val_mae: 292.2056 Epoch 274/300 683/683 [==============================] - 1s 2ms/step - loss: 215494.5625 - mse: 215494.5625 - mae: 255.4738 - val_loss: 337693.3125 - val_mse: 337693.3125 - val_mae: 301.9772 Epoch 275/300 683/683 [==============================] - 1s 1ms/step - loss: 213759.2969 - mse: 213759.2969 - mae: 253.9668 - val_loss: 322348.1875 - val_mse: 322348.1875 - val_mae: 294.7024 Epoch 276/300 683/683 [==============================] - 1s 1ms/step - loss: 218339.6719 - mse: 218339.6719 - mae: 256.5962 - val_loss: 318860.7500 - val_mse: 318860.7500 - val_mae: 298.4697 Epoch 277/300 683/683 [==============================] - 1s 1ms/step - loss: 212229.9375 - mse: 212229.9375 - mae: 253.0822 - val_loss: 334915.1250 - val_mse: 334915.1250 - val_mae: 307.6370 Epoch 278/300 683/683 [==============================] - 1s 1ms/step - loss: 215656.9844 - mse: 215656.9844 - mae: 254.9639 - val_loss: 329815.9688 - val_mse: 329815.9688 - val_mae: 296.4344 Epoch 279/300 683/683 [==============================] - 1s 1ms/step - loss: 213004.7344 - mse: 213004.7344 - mae: 255.9615 - val_loss: 331985.0625 - val_mse: 331985.0625 - val_mae: 301.6564 Epoch 280/300 683/683 [==============================] - 1s 1ms/step - loss: 215592.4062 - mse: 215592.4062 - mae: 256.4908 - val_loss: 322727.4375 - val_mse: 322727.4375 - val_mae: 297.6215 Epoch 281/300 683/683 [==============================] - 1s 2ms/step - loss: 212147.0938 - mse: 212147.0938 - mae: 254.4098 - val_loss: 350716.8438 - val_mse: 350716.8438 - val_mae: 315.5979 Epoch 282/300 683/683 [==============================] - 1s 1ms/step - loss: 214694.9375 - mse: 214694.9375 - mae: 255.4699 - val_loss: 318556.6562 - val_mse: 318556.6562 - val_mae: 292.6938 Epoch 283/300 683/683 [==============================] - 1s 1ms/step - loss: 210359.7344 - mse: 210359.7344 - mae: 253.6239 - val_loss: 336551.3750 - val_mse: 336551.3750 - val_mae: 306.2090 Epoch 284/300 683/683 [==============================] - 1s 1ms/step - loss: 216476.9688 - mse: 216476.9688 - mae: 257.3586 - val_loss: 346310.4688 - val_mse: 346310.4688 - val_mae: 310.3838 Epoch 285/300 683/683 [==============================] - 1s 1ms/step - loss: 213371.3750 - mse: 213371.3750 - mae: 254.5538 - val_loss: 324027.4375 - val_mse: 324027.4375 - val_mae: 301.0831 Epoch 286/300 683/683 [==============================] - 1s 1ms/step - loss: 209473.9531 - mse: 209473.9531 - mae: 251.9590 - val_loss: 318272.5938 - val_mse: 318272.5938 - val_mae: 292.0929 Epoch 287/300 683/683 [==============================] - 1s 1ms/step - loss: 212559.6250 - mse: 212559.6250 - mae: 255.1318 - val_loss: 320147.1562 - val_mse: 320147.1562 - val_mae: 297.3651 Epoch 288/300 683/683 [==============================] - 1s 1ms/step - loss: 213987.0938 - mse: 213987.0938 - mae: 255.4787 - val_loss: 343735.1875 - val_mse: 343735.1875 - val_mae: 311.0410 Epoch 289/300 683/683 [==============================] - 1s 2ms/step - loss: 212939.9844 - mse: 212939.9844 - mae: 255.8164 - val_loss: 329572.7188 - val_mse: 329572.7188 - val_mae: 307.3170 Epoch 290/300 683/683 [==============================] - 1s 1ms/step - loss: 211866.2188 - mse: 211866.2188 - mae: 253.8895 - val_loss: 324348.0312 - val_mse: 324348.0312 - val_mae: 302.0331 Epoch 291/300 683/683 [==============================] - 1s 1ms/step - loss: 214421.4062 - mse: 214421.4062 - mae: 256.1899 - val_loss: 324709.3438 - val_mse: 324709.3438 - val_mae: 305.8430 Epoch 292/300 683/683 [==============================] - 1s 1ms/step - loss: 214567.9062 - mse: 214567.9062 - mae: 257.1556 - val_loss: 320887.1250 - val_mse: 320887.1250 - val_mae: 296.5273 Epoch 293/300 683/683 [==============================] - 1s 1ms/step - loss: 210826.6094 - mse: 210826.6094 - mae: 253.2814 - val_loss: 348340.5938 - val_mse: 348340.5938 - val_mae: 300.0701 Epoch 294/300 683/683 [==============================] - 1s 1ms/step - loss: 210734.7188 - mse: 210734.7188 - mae: 252.7330 - val_loss: 330317.0312 - val_mse: 330317.0312 - val_mae: 297.9991 Epoch 295/300 683/683 [==============================] - 1s 1ms/step - loss: 213789.9062 - mse: 213789.9062 - mae: 255.4389 - val_loss: 327556.9062 - val_mse: 327556.9062 - val_mae: 295.4689 Epoch 296/300 683/683 [==============================] - 1s 1ms/step - loss: 209180.7031 - mse: 209180.7031 - mae: 252.4926 - val_loss: 328716.8750 - val_mse: 328716.8750 - val_mae: 303.2322 Epoch 297/300 683/683 [==============================] - 1s 1ms/step - loss: 213946.8906 - mse: 213946.8906 - mae: 255.4148 - val_loss: 318147.3750 - val_mse: 318147.3750 - val_mae: 292.1889 Epoch 298/300 683/683 [==============================] - 1s 1ms/step - loss: 209742.5469 - mse: 209742.5469 - mae: 251.8029 - val_loss: 347704.2500 - val_mse: 347704.2500 - val_mae: 318.0484 Epoch 299/300 683/683 [==============================] - 1s 1ms/step - loss: 211260.2969 - mse: 211260.2969 - mae: 253.7263 - val_loss: 332148.8125 - val_mse: 332148.8125 - val_mae: 304.3614 Epoch 300/300 683/683 [==============================] - 1s 1ms/step - loss: 208935.3594 - mse: 208935.3594 - mae: 252.0351 - val_loss: 326753.4688 - val_mse: 326753.4688 - val_mae: 303.0244
El objeto history tiene un diccionario dentro del método history. Este guarda los diferentes valores de las métricas de pérdida para cada epoch. Nosotros podemos utilizar estos valores para visualizar como es el comportamiento de la pérdida en cada epoch. Utilizaremos una escala logaritmica para hacer que la visualización sea más clara.
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(np.log(history.history['loss']), label='Training Loss')
ax.plot(np.log(history.history['val_loss']), label='Validation Loss')
ax.set_title('Log(Loss) vs epochs', fontsize=15)
ax.set_xlabel('epoch number', fontsize=14)
ax.legend(fontsize=12)
ax.set_ylim(12, 14)
ax.grid()
Lo que observamos es algo tipico cuando entrenamos redes neuronales. Como mencionamos anteriormente, la pérdida de entrenamiento va disminuyendo por cada epoch, porque eso es lo que hace el proceso de entrenamiento: ajustar el peso de tal manera que la pérdida sea cada vez menor. Sin embargo, lo que realmnte importa es como actua el modelo prediciendo datos que no ha visto y en este caso, los datos que no se han visto corresponden al 10% del conjunto de entrenamiento. Vemos como la curva de la pérdida de validación ha disminuido en los primeros epochs y luego a comenzado a aumentar, lo que significa que que la red ha dejado de aprender de la relación entre las variables y el vector objetivo y sólo está aprendiendo el ruido del conjunto de entrenamiento.
Podemos también monitorear otras métricas que podemos configurar en el proceso de compilación. Ahora utilizaremos la métrica del error absoluto medio o mean absolute error (MAE). Como otras medidas de regresiones, entre más pequeño sea el MAE, mejor.
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(history.history['mae'], label='Train MAE')
ax.plot(history.history['val_mae'], label='Validation MAE')
ax.set_title('MAE vs epochs', fontsize=15)
ax.set_xlabel('epoch number', fontsize=14)
ax.legend(fontsize=12)
ax.set_ylim(200, 500)
ax.grid()
El comportamiento en el MAE de entrenamiento es el mismo que la pérdida del conjunto de entrenamiento. Sin embargo, en las métricas de validación, primero observamos una disminución y luego un aumento. Estamos entrenando esta red con 300 epochs y esto es quizás demasiado. De acuerdo al gráfico, deberiamos dejar de entrenar mucho antes, alrededor de 40-70 epochs. Ahora implementemos un early stopping o parada anticipada.
Parada anticipada.
Para realizar una parada anticipada en Keras, utilizaremos una instancia del objeto llamado callbacks. Un callback es un conjunto de funciones para obtener una mirada de los estados internos y estadísticas del modelo durante el entrenamiento. Podemos pasar una lista de callbacks al .fit().
Nosotros utilizaremos uno de estos callbacks llamado EarlyStopping. Primero, iniciamos el objeto y luego, podemos usar esto para controlar el entrenamiento. Los argumentos que podemos configurar son los siguientes:
- monitor: Cantidad de la variable que se va a monitorear, por ejemplo, el MAE.
- min_delta: Cambio mínimo de la variable a monitorear que sea calificada como mejora, es decir, un cambio menor a min_delta no contará como mejora.
- patience: Número permitido de epochs que no muestran mejoría en la variable a monitorear para detener el entrenamiento. Por ejemplo, si después de 5 epoch la variable no mejora, se detiene el proceso.
- verbose: Modo de verbosidad.
- mode: Argumento con tres modalidades: auto, min y max
- min: El entrenamiento se detendrá cuando la cantidad monitoreada deje de decrecer.
- max: El entrenamiento se detendrá cuando la cantidad monitoreada deje de crecer.
- auto: La dirección es automáticamente inferida por el nombre de la variable a monitorear.
- baseline: El entrenamiento se detendrá si el modelo no muestra mejoras sobre una línea base.
- restore_best_weights: Toma un valor booleano donde si es verdadero, el modelo restaura el peso del epoch con el mejor valor de la variable que se va a monitorear. Si es falso, se utilizará el último peso obtenido en el último epoch.
from keras.callbacks import EarlyStopping
early_stoping = EarlyStopping(monitor='val_mae', min_delta=5, patience=20, verbose=1, mode='auto')Con esto, ya tenemos configurado una parada anticipada de tal manera que cuando el MAE deje de mejorar en más de 5 unidades por 20 epochs, el entrenamiento se detendrá.
Como la red ya está entrenada, debemos construirla de nuevo para utilizar la parada anticipada.
nn_reg2 = Sequential()
n_hidden = 64
# capas ocultas
nn_reg2.add(Dense(units=n_hidden, activation='relu', input_shape=(n_input,)))
nn_reg2.add(Dense(units=n_hidden, activation='relu'))
nn_reg2.add(Dense(units=n_hidden, activation='relu'))
nn_reg2.add(Dense(units=n_hidden, activation='relu'))
nn_reg2.add(Dense(units=n_hidden, activation='relu'))
nn_reg2.add(Dense(units=n_hidden, activation='relu'))
nn_reg2.add(Dense(units=1, activation=None))
nn_reg2.compile(loss='mean_squared_error', optimizer='adam', metrics=['mse', 'mae'])
nn_reg2.summary()Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_11 (Dense) (None, 64) 1408
dense_12 (Dense) (None, 64) 4160
dense_13 (Dense) (None, 64) 4160
dense_14 (Dense) (None, 64) 4160
dense_15 (Dense) (None, 64) 4160
dense_16 (Dense) (None, 64) 4160
dense_17 (Dense) (None, 1) 65
=================================================================
Total params: 22,273
Trainable params: 22,273
Non-trainable params: 0
_________________________________________________________________
Ahora, cuando realicemos el fit(), debemos incorporar el argumento callback que contiene una lista con las funciones que vamos a utilizar. En este caso, vamos a utilizar early_stopping.
batch_size = 64
n_epochs = 300
history = nn_reg2.fit(X_train, y_train,
epochs = n_epochs,
batch_size = batch_size,
validation_split = 0.1,
callbacks = [early_stoping])Epoch 1/300 683/683 [==============================] - 2s 2ms/step - loss: 4074584.0000 - mse: 4074584.0000 - mae: 978.9944 - val_loss: 907036.8125 - val_mse: 907036.8125 - val_mae: 477.6147 Epoch 2/300 683/683 [==============================] - 1s 2ms/step - loss: 728339.6250 - mse: 728339.6250 - mae: 434.5718 - val_loss: 673701.6875 - val_mse: 673701.6875 - val_mae: 405.0725 Epoch 3/300 683/683 [==============================] - 1s 1ms/step - loss: 581314.0625 - mse: 581314.0625 - mae: 398.0353 - val_loss: 543704.3125 - val_mse: 543704.3125 - val_mae: 382.7009 Epoch 4/300 683/683 [==============================] - 1s 1ms/step - loss: 477614.3750 - mse: 477614.3750 - mae: 372.2533 - val_loss: 479594.1250 - val_mse: 479594.1250 - val_mae: 367.3098 Epoch 5/300 683/683 [==============================] - 1s 2ms/step - loss: 413366.9688 - mse: 413366.9688 - mae: 356.9076 - val_loss: 440341.0625 - val_mse: 440341.0625 - val_mae: 363.9987 Epoch 6/300 683/683 [==============================] - 1s 1ms/step - loss: 390403.2812 - mse: 390403.2812 - mae: 349.5566 - val_loss: 398980.6875 - val_mse: 398980.6875 - val_mae: 349.4655 Epoch 7/300 683/683 [==============================] - 1s 1ms/step - loss: 370081.5938 - mse: 370081.5938 - mae: 339.2853 - val_loss: 393672.7812 - val_mse: 393672.7812 - val_mae: 344.2959 Epoch 8/300 683/683 [==============================] - 1s 1ms/step - loss: 361730.9375 - mse: 361730.9375 - mae: 335.6235 - val_loss: 365933.5000 - val_mse: 365933.5000 - val_mae: 327.8531 Epoch 9/300 683/683 [==============================] - 1s 1ms/step - loss: 362483.0312 - mse: 362483.0312 - mae: 335.7765 - val_loss: 372358.3438 - val_mse: 372358.3438 - val_mae: 332.2648 Epoch 10/300 683/683 [==============================] - 1s 1ms/step - loss: 343565.0000 - mse: 343565.0000 - mae: 325.3829 - val_loss: 382482.2812 - val_mse: 382482.2812 - val_mae: 344.4958 Epoch 11/300 683/683 [==============================] - 1s 1ms/step - loss: 349831.3750 - mse: 349831.3750 - mae: 328.4012 - val_loss: 373428.8750 - val_mse: 373428.8750 - val_mae: 327.1324 Epoch 12/300 683/683 [==============================] - 1s 1ms/step - loss: 333122.4062 - mse: 333122.4062 - mae: 319.9485 - val_loss: 369550.1562 - val_mse: 369550.1562 - val_mae: 341.3672 Epoch 13/300 683/683 [==============================] - 1s 1ms/step - loss: 342419.5938 - mse: 342419.5938 - mae: 325.9057 - val_loss: 375203.1875 - val_mse: 375203.1875 - val_mae: 335.8931 Epoch 14/300 683/683 [==============================] - 1s 1ms/step - loss: 345167.5312 - mse: 345167.5312 - mae: 326.7870 - val_loss: 446981.1562 - val_mse: 446981.1562 - val_mae: 376.1908 Epoch 15/300 683/683 [==============================] - 1s 1ms/step - loss: 337162.1875 - mse: 337162.1875 - mae: 321.1629 - val_loss: 360469.0312 - val_mse: 360469.0312 - val_mae: 332.2074 Epoch 16/300 683/683 [==============================] - 1s 1ms/step - loss: 330001.8750 - mse: 330001.8750 - mae: 317.9146 - val_loss: 356921.6562 - val_mse: 356921.6562 - val_mae: 318.8238 Epoch 17/300 683/683 [==============================] - 1s 2ms/step - loss: 325480.4688 - mse: 325480.4688 - mae: 316.2596 - val_loss: 368489.2812 - val_mse: 368489.2812 - val_mae: 312.9010 Epoch 18/300 683/683 [==============================] - 1s 2ms/step - loss: 320913.9688 - mse: 320913.9688 - mae: 314.2040 - val_loss: 349809.0938 - val_mse: 349809.0938 - val_mae: 320.0375 Epoch 19/300 683/683 [==============================] - 2s 2ms/step - loss: 324401.3750 - mse: 324401.3750 - mae: 316.4430 - val_loss: 348527.6250 - val_mse: 348527.6250 - val_mae: 320.1294 Epoch 20/300 683/683 [==============================] - 1s 2ms/step - loss: 327471.0938 - mse: 327471.0938 - mae: 317.1595 - val_loss: 372095.6875 - val_mse: 372095.6875 - val_mae: 334.0724 Epoch 21/300 683/683 [==============================] - 1s 2ms/step - loss: 317524.0312 - mse: 317524.0312 - mae: 310.3505 - val_loss: 334470.4688 - val_mse: 334470.4688 - val_mae: 311.0693 Epoch 22/300 683/683 [==============================] - 1s 1ms/step - loss: 317120.5000 - mse: 317120.5000 - mae: 310.3249 - val_loss: 339449.5000 - val_mse: 339449.5000 - val_mae: 318.9597 Epoch 23/300 683/683 [==============================] - 1s 1ms/step - loss: 321553.3125 - mse: 321553.3125 - mae: 312.9440 - val_loss: 349315.0000 - val_mse: 349315.0000 - val_mae: 318.8475 Epoch 24/300 683/683 [==============================] - ETA: 0s - loss: 316454.0625 - mse: 316454.0625 - mae: 309.560 - 1s 1ms/step - loss: 315918.3438 - mse: 315918.3438 - mae: 309.3542 - val_loss: 345573.3125 - val_mse: 345573.3125 - val_mae: 314.3750 Epoch 25/300 683/683 [==============================] - 1s 1ms/step - loss: 309098.4375 - mse: 309098.4375 - mae: 305.6963 - val_loss: 346189.9375 - val_mse: 346189.9375 - val_mae: 314.3092 Epoch 26/300 683/683 [==============================] - 1s 2ms/step - loss: 315601.9375 - mse: 315601.9375 - mae: 309.7077 - val_loss: 330051.9688 - val_mse: 330051.9688 - val_mae: 304.1929 Epoch 27/300 683/683 [==============================] - 1s 2ms/step - loss: 315682.1250 - mse: 315682.1250 - mae: 310.2230 - val_loss: 349066.9375 - val_mse: 349066.9375 - val_mae: 308.0298 Epoch 28/300 683/683 [==============================] - 1s 1ms/step - loss: 309988.5625 - mse: 309988.5625 - mae: 306.5088 - val_loss: 325271.2500 - val_mse: 325271.2500 - val_mae: 307.6054 Epoch 29/300 683/683 [==============================] - 1s 1ms/step - loss: 304918.8125 - mse: 304918.8125 - mae: 302.2885 - val_loss: 327167.0625 - val_mse: 327167.0625 - val_mae: 296.9158 Epoch 30/300 683/683 [==============================] - 1s 1ms/step - loss: 303772.9375 - mse: 303772.9375 - mae: 302.6071 - val_loss: 336111.3750 - val_mse: 336111.3750 - val_mae: 310.7133 Epoch 31/300 683/683 [==============================] - 1s 1ms/step - loss: 302497.8750 - mse: 302497.8750 - mae: 303.5038 - val_loss: 315679.9375 - val_mse: 315679.9375 - val_mae: 299.7375 Epoch 32/300 683/683 [==============================] - 1s 1ms/step - loss: 303158.8438 - mse: 303158.8438 - mae: 303.2362 - val_loss: 354602.8125 - val_mse: 354602.8125 - val_mae: 315.5391 Epoch 33/300 683/683 [==============================] - 1s 1ms/step - loss: 304782.1875 - mse: 304782.1875 - mae: 302.7748 - val_loss: 353256.0625 - val_mse: 353256.0625 - val_mae: 311.9447 Epoch 34/300 683/683 [==============================] - 1s 1ms/step - loss: 303147.0938 - mse: 303147.0938 - mae: 302.8792 - val_loss: 318144.7188 - val_mse: 318144.7188 - val_mae: 296.7119 Epoch 35/300 683/683 [==============================] - 1s 2ms/step - loss: 298156.1875 - mse: 298156.1875 - mae: 298.6697 - val_loss: 336605.8438 - val_mse: 336605.8438 - val_mae: 306.9611 Epoch 36/300 683/683 [==============================] - 1s 1ms/step - loss: 299596.5000 - mse: 299596.5000 - mae: 299.9556 - val_loss: 322674.8438 - val_mse: 322674.8438 - val_mae: 307.4403 Epoch 37/300 683/683 [==============================] - 1s 1ms/step - loss: 300178.3125 - mse: 300178.3125 - mae: 298.4560 - val_loss: 314509.0938 - val_mse: 314509.0938 - val_mae: 296.2591 Epoch 38/300 683/683 [==============================] - 1s 1ms/step - loss: 294396.4375 - mse: 294396.4375 - mae: 297.4360 - val_loss: 329298.5625 - val_mse: 329298.5625 - val_mae: 329.2694 Epoch 39/300 683/683 [==============================] - 1s 2ms/step - loss: 301466.6562 - mse: 301466.6562 - mae: 299.3991 - val_loss: 327630.9062 - val_mse: 327630.9062 - val_mae: 302.9140 Epoch 40/300 683/683 [==============================] - 1s 1ms/step - loss: 295207.2500 - mse: 295207.2500 - mae: 296.2662 - val_loss: 325768.1562 - val_mse: 325768.1562 - val_mae: 311.2917 Epoch 41/300 683/683 [==============================] - 1s 2ms/step - loss: 295347.6250 - mse: 295347.6250 - mae: 296.5297 - val_loss: 311541.1562 - val_mse: 311541.1562 - val_mae: 296.7051 Epoch 42/300 683/683 [==============================] - 1s 2ms/step - loss: 297011.2188 - mse: 297011.2188 - mae: 298.4242 - val_loss: 380495.0000 - val_mse: 380495.0000 - val_mae: 346.1007 Epoch 43/300 683/683 [==============================] - 1s 1ms/step - loss: 291458.9375 - mse: 291458.9375 - mae: 293.1868 - val_loss: 328070.8125 - val_mse: 328070.8125 - val_mae: 302.0080 Epoch 44/300 683/683 [==============================] - 1s 2ms/step - loss: 293290.6250 - mse: 293290.6250 - mae: 294.1129 - val_loss: 322465.0938 - val_mse: 322465.0938 - val_mae: 295.4600 Epoch 45/300 683/683 [==============================] - 1s 2ms/step - loss: 287428.2500 - mse: 287428.2500 - mae: 291.1035 - val_loss: 319993.2188 - val_mse: 319993.2188 - val_mae: 290.0431 Epoch 46/300 683/683 [==============================] - 1s 1ms/step - loss: 292736.4062 - mse: 292736.4062 - mae: 296.0988 - val_loss: 317995.6875 - val_mse: 317995.6875 - val_mae: 288.5659 Epoch 47/300 683/683 [==============================] - 1s 2ms/step - loss: 292584.8438 - mse: 292584.8438 - mae: 293.1908 - val_loss: 311535.5312 - val_mse: 311535.5312 - val_mae: 297.2931 Epoch 48/300 683/683 [==============================] - 1s 2ms/step - loss: 292643.5938 - mse: 292643.5938 - mae: 295.6700 - val_loss: 321812.2812 - val_mse: 321812.2812 - val_mae: 298.3164 Epoch 49/300 683/683 [==============================] - 1s 1ms/step - loss: 286030.4062 - mse: 286030.4062 - mae: 289.7929 - val_loss: 339137.6250 - val_mse: 339137.6250 - val_mae: 312.7348 Epoch 50/300 683/683 [==============================] - 1s 1ms/step - loss: 290520.9375 - mse: 290520.9375 - mae: 293.4063 - val_loss: 328366.9688 - val_mse: 328366.9688 - val_mae: 296.8376 Epoch 51/300 683/683 [==============================] - 1s 1ms/step - loss: 288669.2812 - mse: 288669.2812 - mae: 291.6965 - val_loss: 323711.0938 - val_mse: 323711.0938 - val_mae: 306.4781 Epoch 52/300 683/683 [==============================] - 1s 1ms/step - loss: 290686.3125 - mse: 290686.3125 - mae: 294.0210 - val_loss: 316348.5312 - val_mse: 316348.5312 - val_mae: 304.7263 Epoch 53/300 683/683 [==============================] - 1s 1ms/step - loss: 289582.0938 - mse: 289582.0938 - mae: 293.6424 - val_loss: 396517.0625 - val_mse: 396517.0625 - val_mae: 324.3072 Epoch 54/300 683/683 [==============================] - 1s 1ms/step - loss: 285453.1250 - mse: 285453.1250 - mae: 289.9561 - val_loss: 326710.4375 - val_mse: 326710.4375 - val_mae: 293.3047 Epoch 55/300 683/683 [==============================] - 1s 1ms/step - loss: 283480.1562 - mse: 283480.1562 - mae: 288.3475 - val_loss: 300681.8438 - val_mse: 300681.8438 - val_mae: 287.8940 Epoch 56/300 683/683 [==============================] - 1s 1ms/step - loss: 285680.3438 - mse: 285680.3438 - mae: 288.6022 - val_loss: 306903.6875 - val_mse: 306903.6875 - val_mae: 302.0164 Epoch 57/300 683/683 [==============================] - 1s 1ms/step - loss: 281432.5000 - mse: 281432.5000 - mae: 286.4992 - val_loss: 373743.3125 - val_mse: 373743.3125 - val_mae: 341.5518 Epoch 58/300 683/683 [==============================] - 1s 1ms/step - loss: 282888.0312 - mse: 282888.0312 - mae: 287.6124 - val_loss: 321229.0000 - val_mse: 321229.0000 - val_mae: 300.3172 Epoch 59/300 683/683 [==============================] - 1s 1ms/step - loss: 287015.3750 - mse: 287015.3750 - mae: 289.9182 - val_loss: 328259.3750 - val_mse: 328259.3750 - val_mae: 305.7977 Epoch 60/300 683/683 [==============================] - 1s 1ms/step - loss: 284804.6875 - mse: 284804.6875 - mae: 289.9005 - val_loss: 319918.8125 - val_mse: 319918.8125 - val_mae: 289.3815 Epoch 61/300 683/683 [==============================] - 1s 1ms/step - loss: 283793.5000 - mse: 283793.5000 - mae: 288.4717 - val_loss: 301017.0625 - val_mse: 301017.0625 - val_mae: 286.2588 Epoch 62/300 683/683 [==============================] - 1s 1ms/step - loss: 279605.2500 - mse: 279605.2500 - mae: 285.1729 - val_loss: 312720.0938 - val_mse: 312720.0938 - val_mae: 294.3479 Epoch 63/300 683/683 [==============================] - 1s 1ms/step - loss: 281218.8438 - mse: 281218.8438 - mae: 287.2284 - val_loss: 347774.2500 - val_mse: 347774.2500 - val_mae: 309.3641 Epoch 64/300 683/683 [==============================] - 1s 1ms/step - loss: 282656.3125 - mse: 282656.3125 - mae: 289.4062 - val_loss: 359132.8125 - val_mse: 359132.8125 - val_mae: 330.9236 Epoch 65/300 683/683 [==============================] - 1s 1ms/step - loss: 279769.5000 - mse: 279769.5000 - mae: 286.0619 - val_loss: 329986.1250 - val_mse: 329986.1250 - val_mae: 315.6244 Epoch 00065: early stopping
Utilizando una parada anticipada, la red se detuvo luego de 76 epochs, lo que significa que luego de ese punto no veremos mucha mejora en la métrica del conjunto de validación que estamos evaluando. Ahora grafiquemos nuevamente el MAE.
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(history.history['mae'], label='Train MAE')
ax.plot(history.history['val_mae'], label='Validation MAE')
ax.set_title('MAE vs epochs', fontsize=15)
ax.set_xlabel('epoch number', fontsize=14)
ax.legend(fontsize=12)
ax.set_ylim(200, 500)
ax.grid()
Ahora, nuestra red no está sobreajustada. Tanto el MAE del conjunto de entrenamiento como el de validación están relativamente cerca una de la otra.
Dropout
Como hemos podido notar, las redes neuronales tienen un número inmenso de parámetros entrenables (peso y sesgo). Incluso con pequeñas redes MLP pudimos observar cientos o miles de parámetros. Esta es una de las razones por la que las redes neuronales se sobreajustan a los datos tan facilmente, por lo que en general tendremos que utilizar técnicas de regularización.
Una de las técnicas más populares de regularización es el dropout que significa abandono en español. La idea es que en cada paso del bucle de entrenamiento, cada unidad en nuestra red (incluidos las entradas de unidades, excluyendo las salidas) tenga una probabilidad fija de ser ignorado o abandonado durante el entrenamiento. Por ejemplo, una probabilidad de abandono de 0.5, por cada paso en el bucle de entrenamiento, es como lanzar una moneda por cada neurona en nuestra red y luego, basado en los resultados, decidir si ese peso en esa neurona es actualizada o no.
La lógica de esta técnica y porqué funciona tiene la siguiente explicación: como las unidades están constantemente yendo y viniendo durante el entrenamiento, las unidades no pueden relacionarse las unas de las otras, reduciendo la dependencia entre ellas y por lo tanto, forzando cada neurona de ser tan util como sea posible para realizar buenas predicciones. Es por eso que el dropout no es solamente una técnica de regularización muy util, si no que también mejora a menudo el rendimiento de la red.
Utilizar dropout en Keras es simple; simplemente añadimos una capa dropout después de la capa a la que le aplicaremos el dropout. Para este ejemplo, crearemos una tercera red neuronal, importando la clase Dropout.
from keras.layers import DropoutAhora, construyamos nuestra red neuronal. Debemos considerar que la primera capa es un Dropout, dado que queremos aplicar un dropout a las unidades de entrada. En otras palabras, estamos seleccionando aleatóriamente qué variable utilizar en cada paso de entrenamiento. Utilizaremos una proporción de dropout del 0.3 o 30%.
nn_reg_dropout = Sequential()
n_hidden = 64
dropout_rate = 0.3# Añadir Dropout en la capa de entrada
nn_reg_dropout.add(Dropout(rate=dropout_rate, input_shape=(n_input,)))# Añadimos cuatro capas ocultas + dropout para cada una de ellas.
nn_reg_dropout.add(Dense(units=n_hidden, activation='relu',
input_shape=(n_input,)))
nn_reg_dropout.add(Dropout(rate=dropout_rate))
nn_reg_dropout.add(Dense(units=n_hidden, activation='relu'))
nn_reg_dropout.add(Dropout(rate=dropout_rate))
nn_reg_dropout.add(Dense(units=n_hidden, activation='relu'))
nn_reg_dropout.add(Dropout(rate=dropout_rate))
nn_reg_dropout.add(Dense(units=n_hidden, activation='relu'))
nn_reg_dropout.add(Dropout(rate=dropout_rate))
nn_reg_dropout.add(Dense(units=n_hidden, activation='relu'))
nn_reg_dropout.add(Dropout(rate=dropout_rate))
nn_reg_dropout.add(Dense(units=n_hidden, activation='relu'))
nn_reg_dropout.add(Dropout(rate=dropout_rate))
nn_reg_dropout.add(Dense(units=1, activation=None))
nn_reg_dropout.summary()Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dropout (Dropout) (None, 21) 0
dense_18 (Dense) (None, 64) 1408
dropout_1 (Dropout) (None, 64) 0
dense_19 (Dense) (None, 64) 4160
dropout_2 (Dropout) (None, 64) 0
dense_20 (Dense) (None, 64) 4160
dropout_3 (Dropout) (None, 64) 0
dense_21 (Dense) (None, 64) 4160
dropout_4 (Dropout) (None, 64) 0
dense_22 (Dense) (None, 64) 4160
dropout_5 (Dropout) (None, 64) 0
dense_23 (Dense) (None, 64) 4160
dropout_6 (Dropout) (None, 64) 0
dense_24 (Dense) (None, 1) 65
=================================================================
Total params: 22,273
Trainable params: 22,273
Non-trainable params: 0
_________________________________________________________________
Ahora realizaremos el paso de compilación
nn_reg_dropout.compile(loss='mse', optimizer='adam', metrics=['mse', 'mae'])Finalmente, entrenemos el modelo utilizando nuevamente early stopping, pero debemos ser pacientes, dado con el dropout la red demora más en entrenar, por lo que configuraremos patience para que sea 40.
batch_size = 64
n_epochs = 300
early_stoping = EarlyStopping(monitor='val_mae', min_delta=5,
patience=40, verbose=1,
mode='auto')
history = nn_reg_dropout.fit(X_train, y_train,
epochs=n_epochs,
batch_size=batch_size,
validation_split=0.1,
callbacks=[early_stoping])Epoch 1/300 683/683 [==============================] - 2s 3ms/step - loss: 8304554.5000 - mse: 8304554.5000 - mae: 1737.4705 - val_loss: 3243188.2500 - val_mse: 3243188.2500 - val_mae: 1001.1776 Epoch 2/300 683/683 [==============================] - ETA: 0s - loss: 4848921.5000 - mse: 4848921.5000 - mae: 1315.50 - 2s 2ms/step - loss: 4841461.5000 - mse: 4841461.5000 - mae: 1314.3899 - val_loss: 2336165.0000 - val_mse: 2336165.0000 - val_mae: 823.2911 Epoch 3/300 683/683 [==============================] - 2s 2ms/step - loss: 4490755.0000 - mse: 4490755.0000 - mae: 1243.2821 - val_loss: 3179119.0000 - val_mse: 3179119.0000 - val_mae: 982.5865 Epoch 4/300 683/683 [==============================] - 2s 2ms/step - loss: 4340611.0000 - mse: 4340611.0000 - mae: 1215.6516 - val_loss: 3584474.7500 - val_mse: 3584474.7500 - val_mae: 1047.1689 Epoch 5/300 683/683 [==============================] - 2s 2ms/step - loss: 4235934.5000 - mse: 4235934.5000 - mae: 1195.1564 - val_loss: 2751525.5000 - val_mse: 2751525.5000 - val_mae: 912.3874 Epoch 6/300 683/683 [==============================] - 2s 2ms/step - loss: 4308563.5000 - mse: 4308563.5000 - mae: 1197.5514 - val_loss: 3796236.2500 - val_mse: 3796236.2500 - val_mae: 1101.8308 Epoch 7/300 683/683 [==============================] - 2s 2ms/step - loss: 4091716.7500 - mse: 4091716.7500 - mae: 1175.9646 - val_loss: 3151090.0000 - val_mse: 3151090.0000 - val_mae: 991.4131 Epoch 8/300 683/683 [==============================] - 2s 2ms/step - loss: 4179111.2500 - mse: 4179111.2500 - mae: 1180.4707 - val_loss: 4332426.5000 - val_mse: 4332426.5000 - val_mae: 1159.6383 Epoch 9/300 683/683 [==============================] - 2s 2ms/step - loss: 4115390.2500 - mse: 4115390.2500 - mae: 1173.3132 - val_loss: 3389427.2500 - val_mse: 3389427.2500 - val_mae: 1033.1105 Epoch 10/300 683/683 [==============================] - 2s 2ms/step - loss: 4122567.5000 - mse: 4122567.5000 - mae: 1174.1766 - val_loss: 2758346.2500 - val_mse: 2758346.2500 - val_mae: 938.1470 Epoch 11/300 683/683 [==============================] - 2s 2ms/step - loss: 4170547.2500 - mse: 4170547.2500 - mae: 1164.8273 - val_loss: 3083519.7500 - val_mse: 3083519.7500 - val_mae: 978.2745 Epoch 12/300 683/683 [==============================] - 2s 2ms/step - loss: 4067619.5000 - mse: 4067619.5000 - mae: 1163.6902 - val_loss: 2858884.2500 - val_mse: 2858884.2500 - val_mae: 945.7017 Epoch 13/300 683/683 [==============================] - 2s 2ms/step - loss: 4091691.2500 - mse: 4091691.2500 - mae: 1168.8794 - val_loss: 3233752.2500 - val_mse: 3233752.2500 - val_mae: 1000.8339 Epoch 14/300 683/683 [==============================] - 2s 3ms/step - loss: 4040545.5000 - mse: 4040545.5000 - mae: 1160.2780 - val_loss: 3984769.2500 - val_mse: 3984769.2500 - val_mae: 1119.5851 Epoch 15/300 683/683 [==============================] - 2s 2ms/step - loss: 3988874.7500 - mse: 3988874.7500 - mae: 1148.4845 - val_loss: 3889787.5000 - val_mse: 3889787.5000 - val_mae: 1091.5212 Epoch 16/300 683/683 [==============================] - 2s 2ms/step - loss: 4007759.0000 - mse: 4007759.0000 - mae: 1155.2914 - val_loss: 3308809.7500 - val_mse: 3308809.7500 - val_mae: 1021.0085 Epoch 17/300 683/683 [==============================] - 2s 3ms/step - loss: 3904369.7500 - mse: 3904369.7500 - mae: 1142.1150 - val_loss: 2887681.7500 - val_mse: 2887681.7500 - val_mae: 956.5418 Epoch 18/300 683/683 [==============================] - 2s 2ms/step - loss: 4015243.5000 - mse: 4015243.5000 - mae: 1149.1959 - val_loss: 3388108.7500 - val_mse: 3388108.7500 - val_mae: 1031.5659 Epoch 19/300 683/683 [==============================] - 2s 2ms/step - loss: 3970667.0000 - mse: 3970667.0000 - mae: 1142.3286 - val_loss: 2941486.0000 - val_mse: 2941486.0000 - val_mae: 934.8324 Epoch 20/300 683/683 [==============================] - 2s 2ms/step - loss: 3995937.0000 - mse: 3995937.0000 - mae: 1144.2051 - val_loss: 3583598.7500 - val_mse: 3583598.7500 - val_mae: 1057.7667 Epoch 21/300 683/683 [==============================] - 2s 2ms/step - loss: 3896585.5000 - mse: 3896585.5000 - mae: 1132.1003 - val_loss: 4248340.0000 - val_mse: 4248340.0000 - val_mae: 1152.0227 Epoch 22/300 683/683 [==============================] - 2s 2ms/step - loss: 3893031.2500 - mse: 3893031.2500 - mae: 1135.3254 - val_loss: 2879170.5000 - val_mse: 2879170.5000 - val_mae: 941.7843 Epoch 23/300 683/683 [==============================] - 2s 2ms/step - loss: 4045254.0000 - mse: 4045254.0000 - mae: 1147.4547 - val_loss: 3306846.2500 - val_mse: 3306846.2500 - val_mae: 999.9781 Epoch 24/300 683/683 [==============================] - 2s 2ms/step - loss: 3930670.2500 - mse: 3930670.2500 - mae: 1140.6525 - val_loss: 3222626.5000 - val_mse: 3222626.5000 - val_mae: 995.0251 Epoch 25/300 683/683 [==============================] - 2s 2ms/step - loss: 4007742.2500 - mse: 4007742.2500 - mae: 1143.6976 - val_loss: 2855859.7500 - val_mse: 2855859.7500 - val_mae: 936.7758 Epoch 26/300 683/683 [==============================] - 2s 2ms/step - loss: 3952398.2500 - mse: 3952398.2500 - mae: 1138.1643 - val_loss: 3583776.0000 - val_mse: 3583776.0000 - val_mae: 1051.3975 Epoch 27/300 683/683 [==============================] - 2s 3ms/step - loss: 3859784.0000 - mse: 3859784.0000 - mae: 1128.9397 - val_loss: 3350165.2500 - val_mse: 3350165.2500 - val_mae: 1024.7157 Epoch 28/300 683/683 [==============================] - 2s 3ms/step - loss: 3895551.0000 - mse: 3895551.0000 - mae: 1131.1698 - val_loss: 2820769.5000 - val_mse: 2820769.5000 - val_mae: 911.3213 Epoch 29/300 683/683 [==============================] - 2s 2ms/step - loss: 3932947.2500 - mse: 3932947.2500 - mae: 1133.9017 - val_loss: 2687183.2500 - val_mse: 2687183.2500 - val_mae: 900.8076 Epoch 30/300 683/683 [==============================] - 2s 2ms/step - loss: 4023550.5000 - mse: 4023550.5000 - mae: 1143.7968 - val_loss: 3716970.2500 - val_mse: 3716970.2500 - val_mae: 1058.9614 Epoch 31/300 683/683 [==============================] - 2s 2ms/step - loss: 3905112.2500 - mse: 3905112.2500 - mae: 1133.3188 - val_loss: 3651885.7500 - val_mse: 3651885.7500 - val_mae: 1031.3729 Epoch 32/300 683/683 [==============================] - 2s 2ms/step - loss: 4009830.2500 - mse: 4009830.2500 - mae: 1133.8091 - val_loss: 3027321.2500 - val_mse: 3027321.2500 - val_mae: 943.6761 Epoch 33/300 683/683 [==============================] - 2s 2ms/step - loss: 3931725.0000 - mse: 3931725.0000 - mae: 1134.0376 - val_loss: 4496269.0000 - val_mse: 4496269.0000 - val_mae: 1173.7557 Epoch 34/300 683/683 [==============================] - 2s 3ms/step - loss: 3974868.0000 - mse: 3974868.0000 - mae: 1134.8696 - val_loss: 2986445.2500 - val_mse: 2986445.2500 - val_mae: 938.1116 Epoch 35/300 683/683 [==============================] - 2s 2ms/step - loss: 3947980.0000 - mse: 3947980.0000 - mae: 1137.8527 - val_loss: 3074895.0000 - val_mse: 3074895.0000 - val_mae: 1004.3111 Epoch 36/300 683/683 [==============================] - 2s 2ms/step - loss: 4024042.7500 - mse: 4024042.7500 - mae: 1139.5117 - val_loss: 2999780.0000 - val_mse: 2999780.0000 - val_mae: 962.6456 Epoch 37/300 683/683 [==============================] - 2s 2ms/step - loss: 3914725.7500 - mse: 3914725.7500 - mae: 1132.2104 - val_loss: 3296315.2500 - val_mse: 3296315.2500 - val_mae: 1018.3626 Epoch 38/300 683/683 [==============================] - 2s 2ms/step - loss: 3857632.5000 - mse: 3857632.5000 - mae: 1122.6930 - val_loss: 2786346.0000 - val_mse: 2786346.0000 - val_mae: 928.3387 Epoch 39/300 683/683 [==============================] - 2s 2ms/step - loss: 3843822.5000 - mse: 3843822.5000 - mae: 1121.3646 - val_loss: 3496179.7500 - val_mse: 3496179.7500 - val_mae: 1035.5460 Epoch 40/300 683/683 [==============================] - 2s 2ms/step - loss: 3969192.5000 - mse: 3969192.5000 - mae: 1132.9777 - val_loss: 2434380.7500 - val_mse: 2434380.7500 - val_mae: 860.6026 Epoch 41/300 683/683 [==============================] - 2s 2ms/step - loss: 3988211.0000 - mse: 3988211.0000 - mae: 1137.0084 - val_loss: 3221902.7500 - val_mse: 3221902.7500 - val_mae: 989.9997 Epoch 42/300 683/683 [==============================] - 2s 2ms/step - loss: 3962705.2500 - mse: 3962705.2500 - mae: 1133.8149 - val_loss: 3127287.2500 - val_mse: 3127287.2500 - val_mae: 964.4513 Epoch 00042: early stopping
El modelo fue entrenado con 68 epochs. Ahora, veamos el gráfico del MAE en el conjunto de entrenamiento y de validación.
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(history.history['mae'], label='Train MAE')
ax.plot(history.history['val_mae'], label='Validation MAE')
ax.set_title('MAE vs epochs utilizando dropout', fontsize=15)
ax.set_xlabel('epoch number', fontsize=14)
ax.legend(fontsize=12)
ax.grid()
En nuestro caso, se observa que dropout no ayudo en el MAE del conjunto de validación. Esto no es sorprendente, porque dropout tiende a funcionar bien para redes más grandes, como docenas de capas, cientos y miles o incluso millones de parámetros. Aunque dropout no fue util para nuestro ejemplo o al menos para nuestra configuración de red neuronal, es siempre bueno tenerlo en cuenta a la hora de entrenar redes neuronales.
Consejos prácticos al entrenar redes neuronales.
Estos simples consejos pueden hacer una gran diferencia al entrenar tu modelo de redes neuronales.
- Estandarizar las variables antes de entregarlas al modelo. MLP es muy sensible a las variables en diferentes escalas, por lo que siempre asegurate en tenerlas a la misma escala.
- Comienza con una red pequeña y si el rendimiento no es el esperado, agrega de a poco capas a tu modelo.
- En general, redes más profundas tienden a trabajar mejor que redes poco profundas con muchas unidades por capa.
- Intenta no utilizar variables muy correlacionadas, porque pueden afectar el rendimiento de la red.
- Usar un conjunto de validación para monitorear el sobreajuste durante el entrenamiento.
- Para el dropout intenta con valores entre 0.1 y 0.5.
- Usa el optimizador Adam o el RMSprop con los parámetros por defecto. Escoger los parámetros adecuados para un optimizador puede ser un gran desafío.
- Retoca una cosa a la vez. Cuando estés en este proceso de prueba y error, prueba con un cambio a la vez sin importar lo que estés modificando (número de capas, número de unidades por capa o cualquier otro aspecto en la red). Si cambias más de un aspecto a la vez, no sabrás que está ocasionando el cambio en el rendimiento de la red.
- Las redes neuronales funcionan mejor para grandes datasets. Uno de los factores asociados a la popularidad y eficiencia de una red neuronal es el tamaño de los datos, en especial para tareas muy complejas. Las redes neuronales son muy poderosas cuando las utilizamos en grandes volumenes de datos, pero para datos que son de menor tamaño como el que estamos utilizando, las redes neuronales, como el MLP, pueden que sean utiles, pero puede que no.
- Se paciente. Estos modelos son complicados persé.
Finalmente, ten en cuenta que un MLP son cajas negras; nosotros metemos los datos en la red neuronal y tenemos la esperanza que salgan buenas predicciones en el otro lado. Sin embargo, no hay una manera fácil de determinar que variables son importantes para la predicción o cómo la red neuronal está utilizando las diferentes variables.
Quinta parte: Evaluación de modelos
En cada proyecto de análisis predictivo es muy importante considerar que métricas utilizar para evaluar los modelos y como implementar la evaluación general de la estrategia y como conectarla con el problema de negocios que estamos intentando resolver.
Evaluación de modelos de regresión
Cuando evaluamos un modelo, tenemos métricas numéricas y visualizaciones que ayudan a complementar la información del desempeño del modelo. Vamos a utilizar el modelo de regresión lineal generado anteriormente, donde el nombre de la variable es ml_reg, pero la diferencia es que vamos a utilizar el método predict para el conjunto de test.
y_pred = ml_reg.predict(X_test)Ahora que tenemos las predicciones en el conjunto de test, podemos calcular la evaluación de las métricas. La evaluación en los modelos de regresión lineal es relativamente simple y la intuición detrás de casi todas las métricas es la misma: si la predicción es cercana al valor real, entonces es un buen modelo, pero si el valor predicho es lejano al real es un mal modelo. Técnicamente hablando, la diferencia entre el valor real y el predicho se le llama valor residual, por lo que la mayoría de las metricas se midel por qué tan bajo es el valor residual en términos absolutos.
MSE y RMSE
Recordar que la métrica que hemos utilizado para el MSE se define de la siguiente manera:
Notar que en el MSE (error cuadrático medio) estamos utilizando el cuadrado y esto es básicamente para que el resultado, independiente si el valor predicho es mayor al valor real o viverversa, sea el mismo.Sin embargo, esto generá mayor desviación en el resultado, por ejemplo, un desvio de 50 dólares va a significar un MSE de 2500, lo que genera un efecto significativo en el resultado.
Recordar a su vez que N es el número de muestras de nuestro conjunto de testing. Por tanto aquí estamos calculando un promedio de las diferencias al cuadrado. En este caso, el MSE sería la diferencia al cuadrado en dólares entre el diamante predicho y el real, vale decir, nos arrojaría dólares al cuadrado. Para tener un número más interpetable, usualmente calculamos la raíz cuadrada para volver a las unidades originales (sólo dólares). Esta métrica se llama RMSE o raíz de error cuadrático medio.
Ahora calculemos el RMSE de nuestro modelo. Notar que primero calculamos el MSE y luego calculamos la raíz cuadrada del mismo.
rmse = mean_squared_error(y_true=y_test, y_pred=y_pred)**0.5
print('RMSE: {:,.2F}'.format(rmse))RMSE: 1,098.76
Esta medida nos dice que tan lejos, en promedio, están los valores predichos por los reales. Algunas personas suelen interpretar este número como "en promedio, el error del modelo es de 1.085 dólares". Sin embargo, una interpretación valida puede que no sea precisa; si quieres calcular el promedio de los errores absolutos del modelo, es mejor usar el error cuadrático medio (MAE). Recordar que nosotros estamos buscando el menor valor posible para obtener un buen modelo (el modelo perfecto es cero).
MAE
El MAE es mucho más intepretable, porque no es una aproximación al error promedio del modelo, si no que es por definición el promedio del error absoluto de la desviación entre el valor predicho y el valor real.
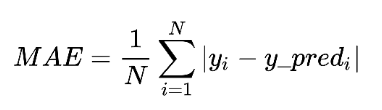
Como estamos tomando el valor absoluto, le estamos dando la misma importancia a los valores sobreestimados y subestimados al valor real. Veamos como se calcula el MAE con scikit-learn.
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_true=y_test, y_pred=y_pred)
print('MAE: {:,.2F}'.format(mae))MAE: 727.00
Ahora podemos decir que, en promedio, el error de nuestro modelo es de 733,7 dólares.
Al igual que el MSE y el RMSE, entre más pequeño sea el valor, mejor.
R cuadrádo (R2)
Cuando intentamos realizar predicciones, los valores siempre van a variar. No sería lógico realizar un modelo predictivo si los valores del vector objetivo fuesen constantes. Desde cierto punto de vista, lo que intentamos hacer con el modelo que estamos evaluando es explicar la variación en los precios tomando en consideración distintos factores que pueden afectarlo.
El $R^2$ o coeficiente de determinación es una métrica que es interpretada como la proporción de la variación que es predecible o que explique el modelo. Es un valor que puede ir de 1 (el modelo explica el 100% la variación del vector objetivo) al cero (el modelo solo predice el promedio) e incluso puede llegar a ser peor, siendo negativo, lo que significa que el modelo es tan malo que sería mejor que el valor predicho siempre sea el promedio del vector objetivo.
Un coeficiente de determinación del 0,6 puede ser interpretado como que el 60% de la variación del vector objetivo puede ser explicado por el modelo y el otro 40% se debe a otros factores y, por supuesto, a la aleatoriedad. Esta métrica se calcula elevando al cuadrado el coeficiente de correlación de Pearson entre los valores reales y previstos. Tenga en cuenta que esta métrica es una medida de que tan cerca los valores observados y predichos varian conjuntamente. No nos dice directamente que tan cerca es el valor predicho del real. Veamos el valor de $R^2$ en nuestro modelo.
from sklearn.metrics import r2_score
r2 = r2_score(y_true=y_test, y_pred=y_pred)
print('R-squared: {:,.2f}'.format(r2))R-squared: 0.92
Entonces, el 92% de la variabilidad observada en los precios de los diamantes es explicado o capturado por el modelo. Desde esta perspectiva, el modelo se ve muy bien.
Definiendo una métrica personalizada.
Cuando entregemos los resultados del modelo a los stakeholders, tendremos que ser lo más claros posibles y demostrar que el modelo es útil desde la perspectiva de la empresa. En general, a las personas de negocios no saben o no les interesan las métricas como el RMSE y por esta razón usualmente tendrás que definir tus propias métricas basadas en el problema de negocio que estamos intentando resolver.
Digamos que el manager de IDR (Intelligent Diamond Reseller) nos dijo que, si bien entre más preciso mejor, lo que es realmente importante para ellos es que el error de predicción (diferencia entre la predicción y el valor real de mercado) sea menor al 15% del valor real. Por lo que, mientras el valor del error absoluto no sea mayor al 15%, la compañía ganará dinero. Con esa información podremos crear una métrica personalizada para medir que tan valioso es nuestro modelo. Podemos definir esta métrica como el porcentaje de predicción con errores aceptables.
Antes de crear la métrica, creemos un DataFrame que nos será de útilidad.
eval_df = pd.DataFrame({'y_true': y_test, 'y_pred':y_pred, 'residuals':y_test-y_pred})En este DataFrame tenemos el precio real, el precio predicho del conjunto de test y los valores residuales. Ahora, pensemos en lo que el manager nos dijo: si por ejemplo tenemos un diamante con un precio de 2.000 dólares y el valor predicho es de 2.250, el valor residual sería de -250 o 250 dólares en términos absolutos, que corresponde a una variación del 12,5% del valor real (250/2000). Esta predicción será buena para la compañía, porque está dentro 15% de tolerancia que ellos determinaron.
Ahora que entendemos el cálculo que debemos hacer, creemos una columna adicional que corresponde al porcentaje que el valor absoluto del residuo representa con respecto al valor real.
eval_df['prop_error'] = eval_df['residuals'].abs() / eval_df['y_true']Ahora podremos facilmente calcular el porcentaje de predicciones que están dentro del 15%.
custom_metric = 100 * (eval_df['prop_error'] < 0.15).mean()
print('Custom metric: {:,.2f}%'.format(custom_metric))Custom metric: 39.27%
Entonces, el 39,2% de nuestras predicciones tienen un error menor al 15% del valor real.
Métodos de visualización para evaluar modelos de regresión
Es muy util comparar el complementar el análisis numérico de las métricas con visualizaciones, dado que nos pueden ayudar a entender las predicciones y los errores que el modelo tiene. Lo primero que podemos hacer es mirar la distribución de los valores residuales.
eval_df['residuals'].hist(bins=25, ec='k')
Vemos que la gran mayoría de los valores residuales se encuentran en dentro del rango de los 2.000 dólares, sin embargo, vemos que se concentran entre los -1.000 y el cero. Calculemos cuántos de estos valores residuales son negativos, es decir, los valores que el modelo está sobreestimando.
(eval_df['residuals'] <= 0).mean()0.598182829593918
Tenemos que casi el 60% de los valores residuales son negativos, lo que sugiere que el modelo sistemáticamente está sobreestimando el precio.
Para investigar en mayor profundidad, visualizemos un diagrama de dispersión de los valores reales y los valores predichos.
fig, ax = plt.subplots(figsize=(8, 5))
ax.scatter(eval_df['y_true'], eval_df['y_pred'], s=3)
ax.plot(eval_df['y_true'], eval_df['y_true'], color='red')
ax.set_title('Prediction vs observed values')
ax.set_xlabel('Observed prices')
ax.set_ylabel('Predicted prices')
ax.grid()
En un modelo perfecto, todos los puntos deberian ir sobre la línea roja. Lo primero que debemos constatar es que, en general, las predicciones siguen al precio real. Esto es bueno, pero cuando tomamos una mirada más de cerca, especificamente a la esquina inferior izquierda, vemos algo extraño y es que el modelo esta haciendo algo que no tiene sentido: predice valores negativos. Esto sería algo bastante vergonzoso si presentaramos esto a un cliente o a nuestro jefe. Menos mal que lo notamos y podemos así constatar lo importante que es evaluar el modelo antes de presentarlo.
Veamos cuales son los primeros cinco valores negativos que predice nuestro modelo.
eval_df['y_pred'].loc[eval_df['y_pred']<0][:5]50994 -81.564846 24040 -296.654418 28198 -168.726806 28508 -360.271852 29777 -104.381718 Name: y_pred, dtype: float64
Además, del gráfico de dispersión, podemos ver que el ranfo observado de precios entre los 1.000 y los 7.500 dólares, el modelo está en la mayor parte sobreestimando los precios, es decir, la mayoría de los puntos está sobre la línea roja.
Otro gráfico que puede ayudarnos a detectar algunos patrones en los valores resuduales es visualizando este último con los valores predichos.
fig, ax = plt.subplots(figsize=(8, 5))
ax.scatter(eval_df['y_pred'], eval_df['residuals'], s=3)
ax.set_title('Prediction vs residuals', fontsize=16)
ax.set_xlabel('Predictions', fontsize=14)
ax.set_ylabel('Residuals', fontsize=14)
ax.axhline(color='k')
ax.axvline(color='k')
ax.grid()
Podemos ver nuevamente en este gráfico que el modelo sobreestima los precios (residuales negativos). También podemos notar un tipo de patrón no lineal entre los valores predichos y los residuales. Idealmente, no deberíamos ver ningún patrón en el gráfico. La presencia de un patrón indica que no estamos usando toda la información de las variables para predecir el precio. Esto significa que tenemos espacio de mejora.
La validación cruzada de K-fold
Hasta ahora hemos hecho validaciones en el conjunto de test con una modelo de regresión lineal multiple y hemos calculado algunas métricas. Digamos que utilizaremos el MAE para evaluar el modelo. Recordemos que el MAE nos dió un valor de 727. Ahora, aunque pensemos que no tiene sentido, repitamos los mismos pasos para construir el modelo utilizando los siguientes pasos:
- Separar del dataset en conjunto de entrenamiento y validación.
- Estandarizar las variables numéricas.
- Entrenar el modelo.
- Obtener las predicciones
- Evaluar el modelo utilizando el MAE
# Primero, reducimos la colienealidad de las dimensiones.
pca = PCA(n_components=1, random_state=123)
pca.fit(X.loc[:, ['x', 'y', 'z']])
X['dim_index'] = pca.transform(X.loc[:, ['x', 'y', 'z']]).flatten()
X.drop(['x', 'y', 'z'], axis=1, inplace=True)
# Luego, separamos la data en conjunto de entrenamiento y de test.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.1, random_state=2)
# Estandarizamos las variables numéricas
scaler = StandardScaler()
scaler.fit(X_train[numerical_features])
X_train.loc[:, numerical_features] = scaler.fit_transform(X_train[numerical_features])
X_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])
# Entrenamos el modelo
ml_reg = LinearRegression()
ml_reg.fit(X_train, y_train)
# Obtenemos las predicciones
y_pred = ml_reg.predict(X_test)
# Evaluamos el modelo utilizando MAE
mae = mean_absolute_error(y_true=y_test, y_pred=y_pred)
print('MAE: {:,.2F}'.format(mae))MAE: 726.94
Hemos repetido los mismos pasos que antes, pero el MAE ahora es de 726,94. Entonces, ¿cuál es el MAE correcto? ¿El que de antes o el de ahora? ¿El modelo mejoró simplemente por correrlo nuevamente? ¿Qué fue lo que ocurrió?
El código es exactamente igual al anterior, salvo en una pequeña modificación: En la función train_test_split hemos cambiado el valor del argumento random_state a 1, lo que significa que ahora tenemos conjuntos diferentes de entrenamiento y test, aunque en ambos casos el tamaño es el mismo. Entonces, ¿cuál es el MAE real, el primero o el segundo?. La respuesta es ninguno. Los dos son solo estimaciones del modelo y como las observaciones o conjuntos son asignados al azar, lo que obtenemos es una estimación del MAE producto de la aleatoriedad.
La desventaja de utilizar la estrategía de entrenamiento/test es que solo obtendremos una estimación de la métrica que utilizamos para evaluar el modelo. Esto no es recomendado si estamos interesados en entregar una buena evaluación del valor real de la métrica a utilizar.
Como sabemos que la métrica que estamos utilizando para la evaluación del modelo puede cambiar, sería mejor obtener más de una estimación y promediarlas para tener una mejor aproximación del verdadero valor de la métrica. Hay muchas técnicas para realizar esto, principalmente dividir o técnicas de remuestreo o validación cruzada. La aproximación más popular para obtener muchas estimaciones de las métricas de evaluación es utilizando la validación cruzada k-fold.
La idea detrás de la validación cruzada es simple: dividimos el dataset en K partes iguales (pliegues o folds). En la primera iteración, utilizamos la primera parte para testear y el resto para entrenar y obtenemos las métricas. Luego, utilizamos la segunda parte de K como test y el resto para entrenar, obteniendo nuevas métricas, y así sucesivamente. De esta manera, obtendremos K estimaciones de las métricas. En la siguiente imagen se puede ver que utilizamos K=4, es decir, obtendremos una métrica, digamos MAE, con cuatro valores distintos.
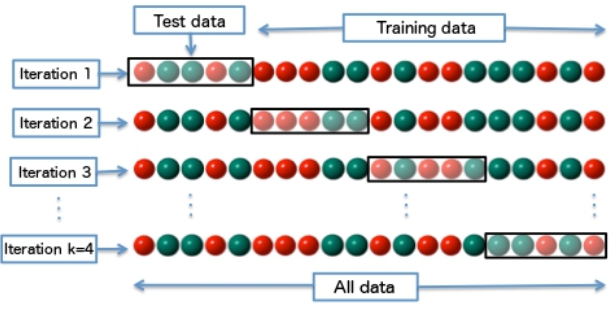
Los valores más comúnes para K son 5 o 10. Implementemos 10 validaciones cruzadas K-fold para obtener una evaluación más precisa del MAE para nuestro modelo de regresión. La función cross_validate usa un estimados y una métrica de puntuación para calcular la validación cruzada K-fold
from sklearn.model_selection import cross_validate
# Estandarizamos todo el dataset
scaler = StandardScaler()
scaler.fit(X[numerical_features])
X.loc[:, numerical_features] = scaler.fit_transform(X[numerical_features])
# 10 K-folds
ml_reg = LinearRegression()
cv_results = cross_validate(ml_reg, X, y, scoring='neg_mean_absolute_error', cv=10)
scores = -1 * cv_results['test_score']Por razones técnicas, scikit-learn utiliza los valores negativos de las métricas (neg_mean_absolute_error), por lo tanto debemos multiplicar en -1 los resultados.
scoresarray([ 720.85265206, 663.16270409, 695.1720048 , 950.8559192 ,
2043.86304417, 890.01326285, 539.98275677, 624.46339134,
584.62586465, 604.34227596])
Como podemos ver, hay algunas variaciones en estas métricas. Con calcular el promedio de estas cantidades obtendremos una mejor estimación del verdadero valor del MAE esperado.
scores.mean()831.733387587927
Esto nos da que para este modelo, la mejor estimación del MAE que podemos esperar es de un 829.35.
La validación cruzada K-fold es super útil, no solo para obtener una estimación más exacta de las métricas, si no también para ajustes de hiperparámetros.
Sexta parte: Ajuste del modelo y mejora del rendimiento.
Ajustes de Hiperparámetros
En muchos modelos, incluidos los que hemos usado hasta ahora, hay algunos parámetros o inputs que no son aprendidos de los datos. Necesitamos elegir sus valores que son llamados hiperparámetros. Hasta ahora, hemos utilizado los hiperparámetros que vienen por defecto en los modelos, que son en general buenos valores basados en las buenas prácticas del análisis predictivo. Sin embargo, si queremos que nuestro modelo tenga un mejor desempeño, necesitamos un ajuste de hiperparámetros que la actividad de encontrar buenos valores de hiperparámetros para nuestro modelo.
Optimizar un solo hiperparámetro
Comenzaremos con el caso más simple que es ajustar un solo hiperparámetro.
El modelo K vecinos más próximos o k-nearest neighbors (KNN) es un ejemplo de un modelo no paramétrico. Esto quiere decir que no tiene parámetros aprendidos de los datos, sin embargo, tiene un hiperparámetro muy importante: la cantidad de vecinos. Anteriormente, habiamos utilizado un modelo KNN con 12 vecinos y nuestro modelo nos dió un resultado mejor en comparación con regresión lineal multiple y lasso. Utilizamos 12 vecinos, porque es un buen valor, pero no hay garantías que sea el mejor valor. Aquí nos adentramos a la búsqueda de mejores hiperparámetros para mejorar el rendimiento de nuestro modelo.
Para optimizar un hiperparámetro lo primero que debemos definir es como vamos a evaluar el modelo. Lo más simple sería seleccionar una métrica principal de interés, como por ejemplo el MAE (mean absolute error). Ahora, debemos seleccionar los posibles valores candidatos para ver cuál de ellos es el mejor para disminuir el MAE la mayor cantidad posible.
Para obtener los pares _candidatevalue y _metricvalue, necesitamos introducir el concepto de conjunto de validación, que es un subconjunto del dataset que serán usado para medir el rendimiento del modelo bajo distintos candidatos numéricos para el hiperparámetro. Esta evaluación no la hacemos en el conjunto de test, porque estariamos implicitamente usando los datos del conjunto de test para ajustar algunos aspectos del modelo. Si realizamos la evaluación del modelo en el conjunto de test, los hiperparámetros se ajustarian a los datos del mismo conjunto y el punto esencial de tener un conjunto de test es simular como el modelo se desempeñaría con datos que no han sido vistos previamente, por lo que no queremos que los hiperparámetros se optimicen en un conjunto de datos que supuestamente no conocemos o no hemos visto con el propósito de evaluar el modelo, es decir, el conjunto de test no se toca.
Primero, asignamos el 10% al conjunto de validación, extraido del conjunto de entrenamiento.
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.1, random_state=13)Ahora, un simple bucle hará el truco de obtener los pares mencionados anteriormente.
candidates = np.arange(4, 16)
mae_metrics = []
for k in candidates:
model = KNeighborsRegressor(n_neighbors=k,
weights='distance',
metric='minkowski',
leaf_size=50,
n_jobs=4)
model.fit(X_train, y_train)
y_pred = model.predict(X_val)
metric = mean_absolute_error(y_true=y_val, y_pred=y_pred)
mae_metrics.append(metric)Ahora, visualicemos el MAE asociado a cada K.
fig, ax = plt.subplots(figsize=(8,5))
ax.plot(candidates, mae_metrics, '-o')
ax.set_xlabel('Hiper-parameter K', fontsize=14)
ax.set_ylabel('MAE', fontsize=14)
ax.grid()
Como sabemos que entre más bajo el MAE mejor el modelo, el mejor valor de K es 8. Esto no quiere decir que no podamos generar un modelo mejor. Recordar que el MAE en el conjunto de test es solo una estimación del MAE real, dado que puede ir cambiando de acuerdo a la aleatoriedad asociada cuando creamos el conjunto de entrenamiento y de validación. Podremos obtener una mejor estimación de una métrica utilizando la validación cruzada K-fold.
Realicemos el mismo procedimiento que antes con la validación cruzada K-fold. Para esto, no neceistamos un conjunto de validación, dado que cada K-fold o pliegue jugará el rol de test de validación. Como modificamos el conjunto de entrenamiento al crear el conjunto de validación, vamos a realizar nuevamente el train_test_split, incluida la estandarización.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=7)
scaler = StandardScaler()
scaler.fit(X_train[numerical_features])
X_train.loc[:, numerical_features] = scaler.fit_transform(X_train[numerical_features])
X_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])Ahora, corramos exactamente el mismo bucle, pero utilizando 10 validaciones cruzadas K-fold oara obtener las métricas. Esto, por supuesto, tomará más tiempo en correr.
from sklearn.model_selection import cross_val_score
candidates = np.arange(4, 16)
mean_mae = []
std_mae = []
for k in candidates:
model = KNeighborsRegressor(n_neighbors=k,
weights='distance',
metric='minkowski',
leaf_size=50,
n_jobs=4)
cv_results = cross_val_score(model, X_train, y_train,
scoring='neg_mean_absolute_error', cv=10)
mean_score, std_score = -1 * cv_results.mean(), cv_results.std()
mean_mae.append(mean_score)
std_mae.append(std_score)Veamos el gráfico del MAE resultante por la validación cruzada una vez más.
fig, ax = plt.subplots(figsize=(8,5))
ax.plot(candidates, mean_mae, 'o-')
ax.set_xlabel('Hyper-parameter K', fontsize=14)
ax.set_ylabel('Mean MAE', fontsize=14)
ax.set_xticks(candidates)
ax.grid()
Ahora, vemos que el mejor valor para K es 7. Sin embargo, el promedio de MAE no es muy diferente para cuando K es 8 o 6. Como el MAE de esos valores es tan cercano, en la práctivca, cualquier valor de 6, 7 u 8 resultará muy similar. Otro valor estadístico que recolectamos de la validación cruzada es la desviación estándar para cada una de las 10 estimaciones de MAE (ontuvimos 10 estimaciones por cada valor candidato). El gráfico es el siguiente.
fig, ax = plt.subplots(figsize=(8,5))
ax.plot(candidates, std_mae, 'o-')
ax.set_xlabel('Hyper-parameter K', fontsize=14)
ax.set_ylabel('Standard deviation of MAE', fontsize=14)
ax.set_xticks(candidates)
ax.grid()
Los valores que vemos en el gráfico son estimaciones de lo que nosotros conocemos como la varianza del modelo. Este mide que tan grande son los cambios en el resulado del modelo cuando el conjunto de entrenamiento cambia. Una gran varianza en general no es deseable, dado que implica que el modelo no es estable. Vemos que nuestro modelo muestra una baja varianza y que el modelo con una menor varianza es cuando K=7. De esto, concluimos que el mejor parámetro para el modelo KNN es K=7, esto najo el contexto de que estamos utilizando solamente a MAE como métrica y de los valores que utilizamos para realizar la validación cruzada. En otras circunstancias, puede que nuestro mejor K sea otro valor, pero mirando el modelo, vemos que a medida que K aumenta, el modelo va empeorando, por lo que es lógico asumir que esta tendencia persiste para mayores valores de K. Tenemos que tener en cuenta que, aunque no sabemos que K=7 es nuestro mejor valor, sería impráctivo probar todos los valores.
Mejorando el rendimiento
Aunque ya hemos encontrado el mejor valor de K para el modelo KNN, la red neuronal se ve un modelo más prometedor. Para mejorar el accuracy del precio de los diamantes, realizaremos dos cosas:
- Entrenar una red neuronal
- Transformar el vector objetivo
Entrenar una red neuronal
Antes utilizamos una red neuronal obteniendo resultados muy buenos. Vamos a entrenar un modelo similar al que entrenamos anteriormente.
n_input = X_train.shape[1]
n_hidden1 = 32
n_hidden2 = 16
n_hidden3 = 8
nn_reg = Sequential()
nn_reg.add(Dense(units=n_hidden1, activation='relu', input_shape=(n_input,)))
nn_reg.add(Dense(units=n_hidden2, activation='relu', input_shape=(n_input,)))
nn_reg.add(Dense(units=n_hidden3, activation='relu', input_shape=(n_input,)))
# capa de salida
nn_reg.add(Dense(units=1, activation=None))Ahora compilemos y entrenemos la red neuronal.
batch_size = 32
n_epochs = 50
nn_reg.compile(loss='mean_absolute_error', optimizer='adam')
nn_reg.fit(X_train, y_train, epochs=n_epochs,
batch_size=batch_size, validation_split=0.05)Epoch 1/50 1441/1441 [==============================] - 2s 1ms/step - loss: 1603.6183 - val_loss: 639.0833 Epoch 2/50 1441/1441 [==============================] - 1s 1ms/step - loss: 533.1669 - val_loss: 487.8318 Epoch 3/50 1441/1441 [==============================] - 1s 1ms/step - loss: 435.1113 - val_loss: 428.8880 Epoch 4/50 1441/1441 [==============================] - 1s 928us/step - loss: 399.4563 - val_loss: 408.8276 Epoch 5/50 1441/1441 [==============================] - 1s 950us/step - loss: 384.7220 - val_loss: 396.3698 Epoch 6/50 1441/1441 [==============================] - 2s 1ms/step - loss: 376.1317 - val_loss: 389.3395 Epoch 7/50 1441/1441 [==============================] - 2s 1ms/step - loss: 370.2703 - val_loss: 385.5541 Epoch 8/50 1441/1441 [==============================] - 2s 1ms/step - loss: 365.5037 - val_loss: 379.5463 Epoch 9/50 1441/1441 [==============================] - 2s 1ms/step - loss: 360.4731 - val_loss: 378.9594 Epoch 10/50 1441/1441 [==============================] - 2s 1ms/step - loss: 356.0416 - val_loss: 373.1992 Epoch 11/50 1441/1441 [==============================] - 2s 1ms/step - loss: 352.9469 - val_loss: 369.2031 Epoch 12/50 1441/1441 [==============================] - 1s 988us/step - loss: 349.9888 - val_loss: 369.7405 Epoch 13/50 1441/1441 [==============================] - 1s 1ms/step - loss: 347.4757 - val_loss: 365.9247 Epoch 14/50 1441/1441 [==============================] - 1s 974us/step - loss: 345.2575 - val_loss: 365.5248 Epoch 15/50 1441/1441 [==============================] - 2s 1ms/step - loss: 343.5773 - val_loss: 362.7621 Epoch 16/50 1441/1441 [==============================] - 2s 1ms/step - loss: 341.4948 - val_loss: 364.3504 Epoch 17/50 1441/1441 [==============================] - 2s 1ms/step - loss: 339.8450 - val_loss: 360.8046 Epoch 18/50 1441/1441 [==============================] - 2s 1ms/step - loss: 338.4868 - val_loss: 360.5938 Epoch 19/50 1441/1441 [==============================] - 2s 1ms/step - loss: 337.0423 - val_loss: 361.0131 Epoch 20/50 1441/1441 [==============================] - 1s 990us/step - loss: 335.9924 - val_loss: 359.4487 Epoch 21/50 1441/1441 [==============================] - ETA: 0s - loss: 334.791 - 2s 1ms/step - loss: 334.8246 - val_loss: 359.3605 Epoch 22/50 1441/1441 [==============================] - 2s 1ms/step - loss: 333.9033 - val_loss: 363.8465 Epoch 23/50 1441/1441 [==============================] - 2s 1ms/step - loss: 333.4333 - val_loss: 359.8504 Epoch 24/50 1441/1441 [==============================] - 2s 1ms/step - loss: 332.8700 - val_loss: 355.6024 Epoch 25/50 1441/1441 [==============================] - 1s 1ms/step - loss: 331.6737 - val_loss: 355.1915 Epoch 26/50 1441/1441 [==============================] - 1s 1ms/step - loss: 331.2357 - val_loss: 355.3245 Epoch 27/50 1441/1441 [==============================] - 1s 1ms/step - loss: 330.1378 - val_loss: 355.3175 Epoch 28/50 1441/1441 [==============================] - 2s 1ms/step - loss: 329.7863 - val_loss: 352.6492 Epoch 29/50 1441/1441 [==============================] - 2s 1ms/step - loss: 329.0565 - val_loss: 351.9757 Epoch 30/50 1441/1441 [==============================] - 2s 1ms/step - loss: 328.7337 - val_loss: 350.9525 Epoch 31/50 1441/1441 [==============================] - 2s 1ms/step - loss: 327.7344 - val_loss: 352.7669 Epoch 32/50 1441/1441 [==============================] - 2s 1ms/step - loss: 326.9600 - val_loss: 348.4870 Epoch 33/50 1441/1441 [==============================] - 1s 986us/step - loss: 326.5713 - val_loss: 353.1712 Epoch 34/50 1441/1441 [==============================] - 2s 1ms/step - loss: 326.1855 - val_loss: 351.0252 Epoch 35/50 1441/1441 [==============================] - 1s 979us/step - loss: 325.5748 - val_loss: 347.4455 Epoch 36/50 1441/1441 [==============================] - 1s 1ms/step - loss: 325.1469 - val_loss: 347.0288 Epoch 37/50 1441/1441 [==============================] - 2s 1ms/step - loss: 324.6692 - val_loss: 346.7990 Epoch 38/50 1441/1441 [==============================] - 1s 942us/step - loss: 323.6702 - val_loss: 349.7031 Epoch 39/50 1441/1441 [==============================] - 1s 877us/step - loss: 323.6147 - val_loss: 347.3631 Epoch 40/50 1441/1441 [==============================] - 1s 943us/step - loss: 322.6089 - val_loss: 348.7155 Epoch 41/50 1441/1441 [==============================] - 1s 959us/step - loss: 322.5857 - val_loss: 343.3606 Epoch 42/50 1441/1441 [==============================] - 1s 921us/step - loss: 321.9913 - val_loss: 344.5847 Epoch 43/50 1441/1441 [==============================] - 1s 961us/step - loss: 321.8043 - val_loss: 343.1212 Epoch 44/50 1441/1441 [==============================] - 1s 941us/step - loss: 321.0180 - val_loss: 344.7462 Epoch 45/50 1441/1441 [==============================] - 2s 1ms/step - loss: 320.8260 - val_loss: 343.2254 Epoch 46/50 1441/1441 [==============================] - 2s 1ms/step - loss: 320.3639 - val_loss: 344.8617 Epoch 47/50 1441/1441 [==============================] - 2s 1ms/step - loss: 320.2120 - val_loss: 342.8759 Epoch 48/50 1441/1441 [==============================] - 2s 1ms/step - loss: 319.4245 - val_loss: 341.7672 Epoch 49/50 1441/1441 [==============================] - 1s 1ms/step - loss: 319.2429 - val_loss: 346.9252 Epoch 50/50 1441/1441 [==============================] - 1s 913us/step - loss: 318.7562 - val_loss: 338.5038
Luego que la red neuronal ha sido entrenada, podemos obtener el valor del MAE dentro del conjunto de test.
y_pred = nn_reg.predict(X_test)
mae_neural_net = mean_absolute_error(y_test, y_pred)
print('MAE Neural Network: {:0.2f}'.format(mae_neural_net))MAE Neural Network: 341.48
Obtenemos un MAE de 345.14 que es mucho mejor que el modelo KNN óptimo. Ahora probemos una segunda idea para ver si podremos mejorar aún más el modelo.
Transformar el vector objetivo
Recordemos que el vector objetivo, cuando realizamos el EDA para entender mejor los datos que estamos trabajando, tiene una distribución muy sesgada a la derecha. A veces, los modelos de regresión trabajan mejor cuando el vector objetivo tiene una distribución más simétrica. Hay muchas transformaciones que podemos aplicar a nuestro vector objetivo para que su distribución sea más simétrica. Como solo tenemos valores positivos, una de las transformaciones más comunes que podemos aplicar para distribuciones sesgadas es la transformación logarítmica, es decir, tranformaremos todos los valores a escala logarítmica. Apliquemos esta transformación para el conjunto de entrenamiento y miremos como se distribuye el vector objetivo resultante.
y_train = np.log(y_train)
pd.Series(y_train).hist(bins=25, ec='k', figsize=(8, 5))
plt.title('Distribution of log diamond prices', fontsize=16)
plt.grid(False)
La distribución no es exactamente simétrica, pero al menos ya no tenemos el sesgo que teniamos antes. Ahora entrenemos la misma red neuronal que antes con el vector objetivo ya transformado.
nn_reg = Sequential()
nn_reg.add(Dense(units=n_hidden1, activation='relu', input_shape=(n_input,)))
nn_reg.add(Dense(units=n_hidden2, activation='relu', input_shape=(n_input,)))
nn_reg.add(Dense(units=n_hidden3, activation='relu', input_shape=(n_input,)))
# capa de salida
nn_reg.add(Dense(units=1, activation=None))
batch_size = 32
n_epochs = 40
nn_reg.compile(loss='mean_absolute_error', optimizer='adam')
nn_reg.fit(X_train, y_train, epochs=n_epochs,
batch_size=batch_size, validation_split=0.05)Epoch 1/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.6389 - val_loss: 0.1597 Epoch 2/40 1441/1441 [==============================] - 1s 930us/step - loss: 0.1366 - val_loss: 0.1263 Epoch 3/40 1441/1441 [==============================] - 1s 1ms/step - loss: 0.1203 - val_loss: 0.1122 Epoch 4/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.1092 - val_loss: 0.0999 Epoch 5/40 1441/1441 [==============================] - 1s 1ms/step - loss: 0.1029 - val_loss: 0.1034 Epoch 6/40 1441/1441 [==============================] - 1s 983us/step - loss: 0.0992 - val_loss: 0.0945 Epoch 7/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0976 - val_loss: 0.1011 Epoch 8/40 1441/1441 [==============================] - 1s 1ms/step - loss: 0.0967 - val_loss: 0.0921 Epoch 9/40 1441/1441 [==============================] - 1s 963us/step - loss: 0.0958 - val_loss: 0.0984 Epoch 10/40 1441/1441 [==============================] - 1s 915us/step - loss: 0.0941 - val_loss: 0.0996 Epoch 11/40 1441/1441 [==============================] - 1s 983us/step - loss: 0.0930 - val_loss: 0.0910 Epoch 12/40 1441/1441 [==============================] - 1s 911us/step - loss: 0.0925 - val_loss: 0.0886 Epoch 13/40 1441/1441 [==============================] - 1s 942us/step - loss: 0.0908 - val_loss: 0.0930 Epoch 14/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0907 - val_loss: 0.0884 Epoch 15/40 1441/1441 [==============================] - 1s 1ms/step - loss: 0.0908 - val_loss: 0.0959 Epoch 16/40 1441/1441 [==============================] - 1s 1ms/step - loss: 0.0905 - val_loss: 0.0858 Epoch 17/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0901 - val_loss: 0.0858 Epoch 18/40 1441/1441 [==============================] - 1s 995us/step - loss: 0.0893 - val_loss: 0.0868 Epoch 19/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0890 - val_loss: 0.0873 Epoch 20/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0879 - val_loss: 0.0857 Epoch 21/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0890 - val_loss: 0.0988 Epoch 22/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0879 - val_loss: 0.0858 Epoch 23/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0876 - val_loss: 0.0852 Epoch 24/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0869 - val_loss: 0.0839 Epoch 25/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0863 - val_loss: 0.0863 Epoch 26/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0858 - val_loss: 0.0878 Epoch 27/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0865 - val_loss: 0.0865 Epoch 28/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0864 - val_loss: 0.0955 Epoch 29/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0865 - val_loss: 0.0843 Epoch 30/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0862 - val_loss: 0.0939 Epoch 31/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0851 - val_loss: 0.0836 Epoch 32/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0851 - val_loss: 0.0841 Epoch 33/40 1441/1441 [==============================] - 2s 2ms/step - loss: 0.0851 - val_loss: 0.0835 Epoch 34/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0846 - val_loss: 0.0808 Epoch 35/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0853 - val_loss: 0.0901 Epoch 36/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0847 - val_loss: 0.0905 Epoch 37/40 1441/1441 [==============================] - 1s 1ms/step - loss: 0.0846 - val_loss: 0.0896 Epoch 38/40 1441/1441 [==============================] - 1s 1ms/step - loss: 0.0845 - val_loss: 0.0835 Epoch 39/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0841 - val_loss: 0.0960 Epoch 40/40 1441/1441 [==============================] - 2s 1ms/step - loss: 0.0848 - val_loss: 0.0839
Finlamente, veamos los precios que el modelo predijo y el MAE. Tenga en cuenta que, para que nuestros resultados sean comparables, deberiamos cambiar la predicción de los precios de escala logarítmica a escala normal.
y_pred = nn_reg.predict(X_test).flatten()
# transformamos desde escala logarítmica a normal
y_pred = np.exp(y_pred)
mae_neural_net2 = mean_absolute_error(y_test, y_pred)
print('MAE Neural Network: {:0.2f}'.format(mae_neural_net2))MAE Neural Network: 319.11
Obtenemos un resultado de 316.13, que es una mejora del 9,18% en nuestra métrica. Puede verse como un aumento pequeño, pero en realidad es una mejora importante, considerando que solo hemos realizado una pequeña transformación a nuestra variable objetivo.
Análisis de resultados.
Además de evaluar el modelo utilizando una métrica, siempre es buena idea evaluar el modelo utilizando gráficos. Primero realicemos un gráfico residual vs los datos observados, que es básicamente como se distribuyen los valores residuales (valor predicho - valor real) con los valores reales.
fig, ax = plt.subplots(figsize=(8, 5))
residuals = y_test - y_pred
ax.scatter(y_test, residuals, s=3)
ax.set_title('Residuals vs Oserved Prices', fontsize=16)
ax.set_xlabel('Observed Prices', fontsize=14)
ax.set_ylabel('Residuals', fontsize=14)
ax.grid()
Podemos notar dos cosas de este gráfico:
1) Los residuos más grandes, es decir, los errores más grandes del modelo se concentran donde los precios de los diamantes son más altos.
2) Con un par de excepciones, todos los precios residuales de los diamantes que tengan un precio de 5000 o inferior, están bajo los 2000.
¿Podemos entonces concluir que el modelo tiene mayor poder de predicción con precios más bajos que grandes? Eso depende que entendemos por poder de predicción. Si juzgamos al modelo por el valor absoluto de los errores que está teniendo, entonces si, dado que el valor residual tiende a crecer cuando el precio crece. De hecho, si calculamos el MAE utilizando un valor de diamantes menor a 7500 dólares, tendremos un MAE mucho menor.
mask_7500 = y_test <= 7500
mae_neural_less_7500 = mean_absolute_error(y_test[mask_7500], y_pred[mask_7500])
print('MAE considering price <= 7500; {:0.2f}'.format(mae_neural_less_7500))MAE considering price <= 7500; 188.98¡Wow! Obtenemos un MAE muchísimo mejor cuando solo predecimos los precios bajo 7500 dólares.
Hay que, sin embargo, considerar que el poder de predicción puede significar algo distinto. Efectivamente el tamaño residual es mayor para precios más altos, pero ¿qué tan alto es el valor residual en proporción con el precio real?. Por ejemplo, consideremos los siguientes casos:
1) Una predicción de 400 cuando el precio real es 500. Aquí tenemos que el valor residual es de 100, pero 100 dólares es el 20% del precio real.
2) Una predicción de 4800 cuando el precio real es 5000. Aquí tenemos que el valor residual es de 200, pero 200 dólares es el 4% del precio real.
¿Qué predicción es mejor, el primer o el segundo caso?. Para responder a esta pregunta, debemos primero responder qué entendemos por poder de predicción y como respondemos a esta pregunta depende del problema del negocio que estamos intentando resolver. Miremos primero al gráfico residual como el porcentaje del valor real. Las lineas rojas hacen referencia a aquellos puntos en que su porcentake de error está entre el 15% y -15%.
fig, ax = plt.subplots(figsize=(8, 5))
percent_residuals = (y_test - y_pred)/y_test
ax.scatter(y_test, percent_residuals, s=3)
ax.set_title('Percent residuals vs Observed Prices', fontsize=16)
ax.set_xlabel('Observed Prices', fontsize=14)
ax.set_ylabel('Percent Residuals', fontsize=14)
ax.axhline(y=0.15, color='r')
ax.axhline(y=-0.15, color='r')
ax.grid()
No solamente un problema técnico, sino un problema de negocio
Cuando realizamos análisis predictivo, mejorar el rendimiento no es solo acerca de mejores modelos, transformaciones y ajustes de hiperparámetros. Debemos siempre entender el problema del negocio y usar esa información para entregar la mejor solución o una lista de opciones que puedan ayudar a los stakeholders a decidir cuál de esas es la mejor.
Por ejemplo, si el modelo de negocios de IDR depende de que el tamaño absoluto de los valores residuales sea bajo, yo recomendaría utilizar el modelo solo para diamantes con un precio menor a 7.500. Si el modelo predice un precio de 13000, por ejemplo, el diamante debiese ser evaluado bajo otro procedimiento. Esta es una limitación del modelo, pero esta limitación también mejora el rendimiento en este nuevo dominio correspondiente a diamantes con un rango menor de precio. Por otro lado, si el modelo del negocio de IDR depende de los errores relativos de la predicción, debiesen de tener más cuidado para diamantes cuyo precio es menor de 1000 dólares aproximadamente.
El análisis predictivo no es un proceso lineal. La evaluación del modelo nos puede llevar a diferentes aproximaciones y en consecuencia tendremos que cambiar ciertas decisiones que ya realizamos, en vista de estos nuevos descubrimientos. Por ejemplo, si decidimos que la mejor manera de evaluar el modelo es con MAE, pero luego al analizar los resultados y discutirlo con nuestros colegas descubrimos que necesitabamos cambiar las métricas de evaluación, eso nos lleva nuevamente a la construcción del modelo y considerar modelos distintos.
Cambiar nuestro parecer acerca de las decisiones y conclusiones no es algo malo, si no más bien todo lo contrario. Admitir ignorancia y cambiar las perspectivas abrirá puertas para nuevas aproximaciones que pueden resultar mejores. Este es un buen consejo no solo para el análisis predictivo, si no también para la vida.
Séptima parte: Comunicación e implementación del modelo.
El fin de hacer un modelo es poder utilizarlo para resolver un problema, por lo que siempre necesitaremos implementar el modelo de tal forma que pueda ser usado por cualquier persona. Hay tres principales maneras en que un proyecto de análisis predictivo puede ser implementado:
1) Para reportes técnicos.
2) Como una mejora a un producto ya existente.
3) Como una aplicación de análisis.
Utilizar un reporte técnico.
Hay veces que nos pedirán un reporte técnico explicando los resultados, conclusiones principales y recomendaciones. Esto es generalmente acompañado de una presentación, donde expondrás frente a tu jefatura la metofología utilizada y principales hallazgos. Esta es la razón por la que los científicos de datos deben tener habilidades de comunicación, dado que se tendrá que exponer de una menera que se entienda y que pueda enganchar a la audencia de lo que se está hablando.
Es importante entender a la audiencia, recordando siempre que el output es para ellos y no para ti. Tendiendo a tu audiencia en mente, podrás decidir tu estílo de presentación, como por ejemplo, formal o informal, el nivel técnico, cuánta jerga utilizar, los puntos principales que comunicaremos, etc.
Aunque todos los proyectos son diferentes, hay una serie de secciones o tópicos que es importante cubrir en una presentación:
- Contexto.
- Problema del negocio.
- Metodología.
- Problemas con los datos.
- Principales hallazgos.
- Implicancias en las predicciones.
- Limitaciones del modelo.
- Recomendaciones.
Tendrás que utilizar muchas visualizaciones para reportear los hallazgos, por lo que dominar como usar las visualizaciones para poder comunicar efectivamente es muy necesario. Un material recomendado para ello es el libro Knaflic (2015) donde el autor explica como generar historias con los datos y nos lleva por el proceso de utilizar visualizaciones para comunicar seis lecciones:
- Entender el contexto: ¿Cuál es tu audiencia? ¿Qué necesita tu audiencia saber o hacer?
- Elige un medio apropiado de visualización: ¿Cuál es el tipo de visualización más apropiado para comunicar tu punto?
- Eliminar el desorden: En cada visualización usa solo los elementos que son estrictamente necesarios, evitando redundancia o cosas que no suman.
- Concentra la atención en dónde tu quieres: Utiliza diferentes técnicas para llamar la atención de la audencia en los puntos principales que quieres comunicar.
- Piensa como un diseñador: Significa que la forma sigue a la función. Piensa en el mensaje y en la función que queremos que cumpla la visualización y luego crear la visualización (forma) que permitirá entregar el mensaje a la audiencia.
- Cuenta una historia: Las historias resuenan y se adhieren en formas que los datos por si mismo no pueden. Los humanos son narradores, por lo que intenta enmarcar el problema de negocio y tu solución, como una historia cohesiva, no solo como una lista de hechos. Finalmente, intenta articular tu reporte o presentación de una forma que sea atractiva tanto logica como emocionalmente.
Mejora a un producto existente.
Hay veces que el modelo resultante se convertá en una característica adicional a una aplicación más grande. Podemos pensar en una aplicación como Amazon o Youtube que incluye características, como recomendaciones de productos o videos, que son parte del análisis predictivo.
Por otro lado, hay programas utilizados internamente en las empresas que incluyen análisis predictivos. Estas pueden estar en diferentes áreas, incluyendo:
- Marketing: Predecir el resultado de una campaña de marketing directo.
- Finanzas: Análisis predictivo para realizar trading. De hecho, la mayoría de las transacciones en los mercados financieros más grandes son hechos por algoritmos y no por humanos.
- Retail: Por ejemplo, predecir que clientas están embarazadas para que la compañía pueda apuntar ofertas especiales a ese segmento.
- Cuidado de salud: Diferentes tipos de dispositivos médicos tienen características predictivas.
- Aviación: Predecir el atraso de los vuelos.
Estas actividades son realizadas en equipos. Es recomendable no intentar ser un unicornio que sabe de todo: análisis predictivo, configuración de clúster, computación en la nube, computación paralela, canalizaciones de datos (data pipelines), software engineering, DevOps, diseño, etc. Solo intenta aprender lo fundamental de alguno de estos campos que están relacionados a desarrollo de software para que seas capaz de comunicar efectivamente tu área de expertiz al resto del equipo.
Utilizar una aplicación de análisis.
A veces, será requerido entregar el modelo a través de una aplicación, sea una versión de escritorio, web o móvil. Esto es similar al caso anterior (añadir el modelo predictivo a un producto existente), pero en este caso, el output del análisis predictivo es el protagonista y las demás características son los personajes secundarios que apoyan al principal en cumplir su cometido, que es predecir.
Hay algunas aproximaciones para elegir el modelo y desarrollar una aplicación. Las siguientes son las más comunes:
- Re-implementación: La mayoría de las aplicaciones empresariales deben desarrollarse utilizando estándares de la industria que incluye velocidad, seguridad y lenguajes de programación de bajo nivel, como Java, C o C++. Luego de terminar el modelo con Python, para tomar la solución a la producción, debemos reimplementar la solución utilizando alguno de estos lenguajes de bajo nivel. La principal ventaja de esta aproximación es que se ganará rendimiento. El principal problema es que consume mucho tiempo reimplementar un modelo en otro lenguaje y con mayor razón si el modelo necesita ser revisado frecuentemente.
- Utilizar un objeto serializado: Esta forma es más simple. En ella, producimos un modelo y luego lo guardamos como objeto serializado. Luego, este objeto puede ser utilizado para servir para una aplicación escrita en Python o tecnología compatible.
- PMML: La otra solución es utilizar Predictive Model Markup Language o PMML, que es un formato de intercambio de modelos predictivos basado en XML. Este lenguaje provee una forma para las aplicaciones de análisis de describir y analizar modelos. Aunque este lenguaje puede ser usado en distintos sistemas operativos y plataformas, no es muy usado en la comunidad de analistas predictivos. Si deseas explorar esta opción, puedes entrar a este link: http://dmg.org/
Debemos considerar que para pasar un modelo a producción se necesita un equipo de ingenieros y muchas semanas con el fin de desarrollar una aplicación analítica a nivel empresarial. Lo que construiremos a continuación es solo un prototipo, pero a pesar de su simplicidad, veremos como desarrollar una aplicación web que servirá para realizar predicciones de un modelo entrenado.
Introducción a Dash
Dash es un framework de Python para construir aplicaciones web de manera rápida y sencilla, sin necesariamente tener conocimiento previo de JavasCript, CSS, HTML o cualquier otra tecnología relacionada al mundo web.
Por otro lado Plotly es una librería de visualización creada por la misma compañia que creó Dash. Estas dos tecnologías fueron hechas para trabajar en conjunto.
Como el objetivo de la librería es producir visualizaciones interactivas en la web, la compañia ofrece un servicio de host. Podemos utilizar esta librería en modo offline que es lo que haremos a continuación.
En esta sección no cubriremos Plotly, pero si estás interesado en aprender puedes comenzar con la documentación: https://plotly.com/python/getting-started/
Para instalar dash en su ambiente anaconda, copie y pegue estos comandos en su terminal.
pip install dash
pip install dash-html-components
pip install dash-core-components
El layout de la aplicación
El layout de la aplicación describe como se ve la aplicación. Es básicamente un árbol jerárquico de componentes, es decir, hay componentes que están hechos de otros componentes y estos están hechos de otros componentes y así. Los componentes que pertenecen a otro componente se les llama hijos y los componentes pueden tener entre cero y muchos hijos. Para construir un layout y sus componentes utilizaremos dos librerias:
- dash_html_components: Esta lirbrería provee clases para todas las etiquetas HTML y los argumentos que describen estas etiquetas, como style, className e id.
- dash_core_components: Esta libreía genera componentes de alto nivel, como controles y gráficos.
En el layout ubicaremos todos los componentes en nuestra aplicación. Conceptualmente podemos pensar que cada componente es una aplicación interactiva que pertenece a una de estas categorías:
- Componente estático: encabezado, texto, imagenes, etc. Podemos utiulizarlo para proveer una descripción de la aplicación. Utilizaremos mayormente la librería dash_html_components para crear estos componentes.
- Componentes de entrada: Son aquellos que campturan los inputs del usuario. Utilizaremos la librería dash_core_components para crear estos componentes.
- Componentes de salida: Estos son los elementos de la aplicación que iran cambiando como resultado de la interacción del usuario con el texto, gráficos, tablas, etc. Dependiendo del tipo de output, utilizaremos tanto la librería dash_html_components y dash_core_components para crear estos componentes.dash_core_components
Construir una aplicación básica estática
Comenzaremos realizando una aplicación muy simple que tendrá como objetivo realizar visualizaciones dinámicas realizadas con Plotly. A esto se le llama aplicación estática, porque no hay input por parte del usuario.
Los pasos para crear esta aplicación son los siguientes:
1) Realizar las importaciones necesarias.
2) Importar la base de datos.
3) Crear el esquema de gráficos en Plotly.
4) Crear una instancia de las visualizaciones con Plotly.
5) Crear un layout.
6) Correr el servidor.
import dash
from dash import dcc
from dash import html
import plotly.graph_objs as go
import pandas as pddiamonds = pd.read_csv('diamonds.csv', index_col=0)El segundo paso ya lo hicimos en un principio, por lo que vamos a continuar con el tercer paso
app = dash.Dash(__name__)Ahora, crearemos los principales elementos de un histograma con Plotly
# Trace son las Series que toma un gráfico, en este caso, es una.
trace = go.Histogram(x= diamonds['price'])
# Layout son las caracteristicas del gráfico, como la leyenda, los titulos, los ejes, etc.
layout = go.Layout(title = 'Diamonds Price', xaxis=dict(title='Price'), yaxis=dict(title='Count'))Ahora que ya creamos los dos elementos de un gráfico Plotly (trace y layout), podemos crear la figura. El argumento del objeto figure deberia tener una lista de traces y en este caso tenemos solo una.
figure = go.Figure(data=[trace], layout=layout)Ahora, podemos crear el layout de nuestra aplicación Dash. Aquí crearemos las etiquetas HTML, como los titulos (H1 y H2), las divisiones (etiqueta Div) y los parrafos (etiqueta P). La etiqueta tendrá cuatro hijos que son los cuatro componentes de la lista: H1, H2, P y el gráfico.
app.layout = html.Div(children = [html.H1('My first Dash App'),
html.H2('Histogram of diamond prices'),
html.P('Este es un texto normal. Lo podemos usar para describir algo en la aplicación'),
dcc.Graph(id='my-histogram', figure=figure)])Finalmente, necesitamos correr la aplicación de manera local
if __name__ == '__main__':
app.run_server(debug=False)Al dar clic en la dirección ID del servidor, se nos abrirá una nueva pestaña con el histograma de los precios. Una vez dentro, podremos interactuar con ese gráfico, haciendo zoom, moviendolo, etc. Ahora podemos seguir adelante viendo como añadirle a esta aplicación la capacidad de interactuar con el usuario.
Construir una aplicación básica interactiva
Ahora crearemos una aplicación simple que acepte inputs del usuario, haciéndola interactiva. Los pasos para lograr este cometido son:
1) Realizar los inputs necesarios.
2) Importar los datasets.
3) Crear una instancia de la app.
4) Importar archivos externos de tipo CSS.
5) Crear el input para generar interactividad.
6) Crear un layout.
7) Crear una función callback para generar interactividad.
8) Correr el servidor.
from dash.dependencies import Input, Output # solo nos falta importar estaExtraeremos una muestra de 2000 observaciones para hacer las visualizaciones más simples.
diamonds = pd.read_csv('diamonds.csv', index_col=0)
diamonds = diamonds.sample(n=2000)Ahora, creamos la instancia de la aplicación y en sus argumentos, incorporamos el documento CSS
app = dash.Dash(__name__,
external_stylesheets=[
'https://codepen.io/chriddyp/pen/bWLwgP.css'])Esta aplicación consistirá en un diagrama de dispersión con dos valores numéricos del dataset. El usuario elegirá estas dos variables y por tanto necesitamos dos controles, uno para cada eje, para que el usuario pueda decidir que variables desea graficar. Utilizaremos el objeto Dropdown para que la aplicación nos acepte más de un input. Este objeto en general recibe al menos tres argumentos:
1) id: Es el identificar que usaremos para referirnos al objeto en la aplicación.
2) options: Es una lista de diccionarios en la forma {'label':label_for_user, 'value':value}
3) value: Es el valor seleccionado por defecto.
La lista de opciones que tendrá el usuario son los datos numéricos del dataset.
numerical_features = ['price', 'carat', 'depth', 'table', 'x', 'y', 'z']
options_dropdown = [{'label':x.upper(), 'value':x} for x in numerical_features]Ahora comenzaremos a crear los objetos Dropdown para el eje x. Lo utilizaremos dentro de una etiqueta div
dd_x_var = dcc.Dropdown(id = 'x-var',
options = options_dropdown,
value = 'carat')
div_x_var = html.Div(children=[html.H4('Variable for x axis:'), dd_x_var],
className = 'six columns')A continuación realizamos el Dropdown para el eje y.
dd_y_var = dcc.Dropdown(id = 'y-var',
options = options_dropdown,
value = 'price')
div_y_var = html.Div(children=[html.H4('Variable for y axis:'), dd_y_var],
className = 'six columns')Utilizamos el className "six columns" en la etiqueta div, porque utilizaremos solo seis columnas en el navegador para que pueda verse de manera ordenada.
Ahora podemos proceder a crear el layout de la aplicación. Esto nuevamente será muy simple.
app.layout = html.Div(children = [html.H1('Adding interactive controls'),
html.H2('Interactive scatter plot example'),
html.Div(
children=[div_x_var, div_y_var],
className = 'row'),
dcc.Graph(id='scatter')])Ahora incluiremos la interactividad. En Dash podremos hacer esto con (decoradores). El decorador utiliza el output que será modificado. Esto lo hace usando el ID del objeto y las propiedades que van a ser modificadas. También utiliza una lista de inputs para actualizar el output. Necesitamos por tanto proveer el ID del input y las propiedades que usará para actualizar.
@app.callback(
Output(component_id='scatter',
component_property='figure'),
[Input(component_id='x-var',
component_property='value'),
Input(component_id='y-var', component_property='value')])
def scatter_plot(x_col, y_col):
trace = go.Scatter(
x = diamonds[x_col],
y = diamonds[y_col],
mode = 'markers')
layout = go.Layout
go.Layout(title = 'Scatter plot',
xaxis = dict(title = x_col.upper()),
yaxis = dict(title = y_col.upper())
)
output_plot = go.Figure(data=[trace],
layout=layout
)
return output_plotComo puedes ver, ambos inputs y outputs identifican el objeto correspondiente a la aplicación usando _componentid. En cambio, _componentproperty es la propiedad que hará cambiar el output y la propiedad que leerá los inputs. El output de la función será asignado al objeto Figure de Plotly.
Finalmente, escribimos el código para iniciar la ejecución de la aplicación en el servidor local.
if __name__ == '__main__':
app.run_server(debug=False)Ahora que sabemos como invcluir interactividad, construyamos una aplicación que sirva para la precidicción del precio de los diamantes. Para mayor información de las aplicaciones interactivas con Dash puedes ver el siguiente link
Implementar un modelo predictivo como una aplicación web
La aplicación que construiremos será muy simple, pero es lo mejor para comenzar y puede ser utilizado en el mundo real. Imaginemos que presentamos los resultados del modelo a IDR y están contentos con los resultados. Le dicen que están listos para utilizar el modelo para el negocio. Para ello, debemos correr el script para entrenar el modelo y añadir algunos objetos necesarios para hacer las predicciones. Recordemos que estos son:
- El objeto PCA que transforma las variables x, y, z en una nueva variable.
- El objeto Scaler.
- el modelo entrenado.
Lo primero que haremos antes de comenzar es serializar estos objetos para utilizarlos en otros programas sin tener que producirlos cada vez que necesitamos hacerlo.
import joblib
joblib.dump(pca, 'pca.joblib') # serializamos el PCA
joblib.dump(scaler, 'scaler.joblib') # serializamos el Scaler
nn_reg.save('diamond-prices-model.h5') # serializamos el modelo entrenado en formato H5 (solo numérico)Los pasos para crear esta aplicación predictiva son los siguientes:
1) Realizar las importaciones necesarios.
2) Crear una instancia de la app.
3) Importar archivos externos de tipo CSS.
4) Cargamos los objetos mencionados anteriormente para serializarlos.
5) Construir los componentes de entrada y sus respectivas etiquetas div.
6) Construir la función de predicción.
# Paso 1
from dash.dependencies import Input, Output
from keras.models import load_model# Seguimos con los pasos 2 y 3.
app = dash.Dash(__name__,
external_stylesheets=[
'https://codepen.io/chriddyp/pen/bWLwgP.css'])Ahora con el paso 4 vamos a serializar. Esto no es más que convertir un objeto en una secuencia de bytes para almacenarlo.
import joblib
model = load_model('diamond-prices-model.h5') # el formato h5 es sólo numérico
pca = joblib.load('pca.joblib')
scaler = joblib.load('scaler.joblib')Ahora debemos construir los objetos que recibirá el input del usuario. Utilizaremos cajas de entrada como input de datos numéricos y un menú desplegable para las variables categóricas. Esto nos da un total de 9 inputs y lo distribuiremos en cuatro columnas.
Aquí tenemos los seis inputs para las variables numéricas.
# Div para carat
input_carat = dcc.Input(id='carat', type='numeric', value=0.7)
div_carat = html.Div(children=[html.H3('Carat:'), input_carat],
className = 'four columns')
# Div para depth
input_depth = dcc.Input(id='depth', placeholder='',
type='numeric', value=60)
div_depth = html.Div(children=[html.H3('Depth:'), input_depth],
className = 'four columns')
# Div para table
input_table = dcc.Input(id='table', placeholder='',
type='numeric', value=60)
div_table = html.Div(children=[html.H3('Table:'), input_table],
className = 'four columns')
# Div para x
input_x = dcc.Input(id='x', placeholder='',
type='numeric', value=5)
div_x = html.Div(children=[html.H3('x value:'), input_x],
className = 'four columns')
# Div para y
input_y = dcc.Input(id='y', placeholder='',
type='numeric', value=5)
div_y = html.Div(children=[html.H3('y value:'), input_y],
className = 'four columns')
# Div para z
input_z = dcc.Input(id='z', placeholder='',
type='numeric', value=3)
div_z = html.Div(children=[html.H3('z value:'), input_z],
className = 'four columns')Ahora, hacemos lo mismo para las variables categóricas.
# Div para el corte
cut_values = ['Fair', 'Good', 'Ideal', 'Premium', 'Very Good']
cut_options = [{'label':x, 'value':x} for x in cut_values]
input_cut = dcc.Dropdown(id='cut', options=cut_options, value='Ideal')
div_cut = html.Div(children=[html.H3('Cut:'), input_cut],
className='four columns')
# Div para el color
color_values = ['D', 'E', 'F', 'G', 'H', 'I', 'J']
color_options = [{'label':x, 'value':x} for x in color_values]
input_color = dcc.Dropdown(id='color', options=color_options, value='G')
div_color = html.Div(children=[html.H3('Color:'), input_color],
className='four columns')
# Div para la claridad
clarity_values = ['I1', 'IF', 'SI1', 'SI2', 'VS1', 'VS2', 'VVS1', 'VVS2']
clarity_options = [{'label':x, 'value':x} for x in clarity_values]
input_clarity = dcc.Dropdown(id='clarity', options=clarity_options, value='SI1')
div_clarity = html.Div(children=[html.H3('Clarity:'), input_clarity],
className='four columns')Ahora hace sentido separar estos nueve inputs en tres grupos:
- variables numéricas: carat, depth y table.
- dimensiones: x, y, z
- variables categóricas: cut, color y clarity
Utilizaremos una etiqueta div para dividir a cada grupo. Note que esta agrupación corresponde a las divisiones que habiamos hecho anteriormente.
# Div para variables numéricas
div_numerical = html.Div(children=[div_carat, div_depth, div_table],
className = 'row')
# Div para las dimensiones
div_dimensions = html.Div(children=[div_x, div_y, div_z],
className = 'row')
# Div para variables numéricas
div_categorical = html.Div(children=[div_cut, div_color, div_clarity],
className = 'row')Ahora, estamos en condiciones de crear el alma de la aplicación, es decir, una función que toma los valores del usuario y producirá las predicciones de precio.
def get_prediction(carat, depth, table, x, y, z,
cut, color, clarity):
"""takes the inputs from the user and
produces the price prediction"""
cols = ['carat', 'depth', 'cut_Good, cut_Ideal',
'cut_Premium', 'cut_Very Good',
'color_E', 'color_F', 'color_G',
'color_H', 'color_I', 'color_J',
'clarity_IF', 'clarity_SI1', 'clarity_SI2',
'clarity_VS1', 'clarity_VS2', 'clarity_VVS1',
'clarity_VVS2', 'dim_index']
cut_dict = {x:'cut_' + x for x in cut_values[1:]}
color_dict = {x:'color_' + x for x in color_values[1:]}
clarity_dict = {x:'clarity_' + x for x in clarity_values[1:]}
# produce a dataframe with a single row of zeros
df = pd.DataFrame(data = np.zeros((1, len(cols))), columns = cols)
# obtener los datos numéricos
df.loc[0, 'carat'] = 'carat'
df.loc[0, 'depth'] = 'depth'
df.loc[0, 'table'] = 'table'
# transformar dimensiones en una sola utilizando PCA
dims_df = pd.DataFrame(data=[[x, y, z]],
columns=['x', 'y', 'z'])
df.loc[0, 'dim_index'] = pca.transform(dims_df).flatten()[0]
# utilizar one-hot encoding para las variables categóricas
if cut != 'Fair':
df.loc[0, cut_dict[cut]] = 1
if color != 'D':
df.loc[0, color_dict[color]] = 1
if clarity != 'I1':
df.loc[0, clarity_dict[clarity]] = 1
# Scale the numerical features using trained scaler
numerical_features = ['carat', 'depth', 'table', 'dim_index']
df.loc[:, numerical_features] = scaler.transform(df.loc[:, numerical_features])
# Obtener las predicciones utilizando la red neuronal entrenada
prediction = model.predict(df.values).flatten()[0]
# Transformar los precios de escala logaritmica a la escala normal
prediction = np.exp(prediction)
return int(prediction)Con esto ya estamos casi listo. Faltaría construir el layout de la aplicación. El componente de la aplicación que mostrará el output o predicción será la etiqueta H1 con el id "output"
# Layout de la aplicación
app.layout = html.Div([html.H1('IDR Predict diamond prices'),
html.H2('Ingrese las características del diamante para poder predecir su precio'),
html.Div(children=[div_numerical, div_dimensions, div_categorical]),
html.H1(id='output', style={'margin-top': '50px', 'text-align':'center'})])Lo último es construir el decorador (callback) que actualizará el output utilizando los 9 inputs.
predictors = ['carat', 'depth', 'table', 'x', 'y', 'z', 'cut', 'color', 'clarity']
@app.callback(Output('output', 'children'),
[Input(x, 'value') for x in predictors])
def show_prediction(carat, depth, table, x, y, z, cut, color, clarity):
pred = get_prediction(carat, depth, table, x, y, z, cut, color, clarity)
return str('Predicted Price: {:,}'.format(pred))¡Y con eso terminamos! Correremos la aplicación para poder probarla y ser capaz de predecir el precio de diamantes basandonos en sus características.
if __name__ == '__main__':
app.run_server(debug=False)Dash is running on http://127.0.0.1:8050/ Dash is running on http://127.0.0.1:8050/ Dash is running on http://127.0.0.1:8050/ * Serving Flask app "__main__" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off
Deja un comentario