
Morosidad en Tarjeta de Crédito
Primera parte: Entendiendo el problema y propuesta de la solución
Contexto
TFI (Taiwanese Financial Institution) es una empresa financiera que ofrece tarjetas de crédito. Últimamente, esta empresa ha sufrido un duro revés al tener a muchos de sus clientes en default, es decir, sin capacidad de poder pagar el monto adeudado de sus tarjetas. Esto ha generado que la empresa se haya visto afectada en sus ingresos y es por eso que necesitan urgente tener un mecanismo para poder anticipar a aquellas personas que pueden entrar en default antes de entregarles una tarjeta de crédito.
Se le pide poder realizar un modelo predictivo para dar solución a este inconveniente anticipando los clientes que pagarán y los clientes que no.
La empresa tiene dos tipos de datos para cada cliente: su perfil y sus datos históricos acerca de sus pagos. Los atributos son los siguientes:
SEX: 1: masculino, 0=femenino
EDUCATION: (1 = educación básica, 2=universidad, 3=educación media, 4=otros)
AGE: Edad del cliente
MARRIAGE: (1=casado(a), 2=soltero(a), 3=otro)
LIMIT_BAL: Cupo entregado en New Taiwan Dollar. Incluye tarjetas individuales y adicionales.
PAY_0 - PAY_5: Seis columnas que muestran los pagos históricos desde Abril a Septiembre del 2005. Cada columna (del 0 al 5) representan los meses desde Septiembre (0) hasta Abril (5). Cada una de ellas contiene una escala del -1 al 8:
- -1: Pagador debil.
- 0: Pago atrasado por un mes.
- 2: Pago atrasado por dos meses. *...
- 8: Pago atrasado por 8 meses.
- 9: Pago atrasado por 9 meses o más.
BILL_AMT1 - BILL_AMT6: Columnas del 1 al 6 que reflejan el monto de la factura en New Taiwan Dollar por cada mes.
- X12: Monto de la factura en Septiembre 2005.
- X13: Monto de la factura en Agosto 2005.
- ...
- x17: Monto de la factura en Abril 2005.
PAY_AMT1 - PAY_AMT6: Columnas del 1 al 6 que reflejan el monto del pago anterior en New Taiwan Dollar por cada mes.
default.payment.next.month: Refleja si el cliente entra en default el mes próximo o paga la deuda.
Proponiendo una solución
Ahora que entendemos el problema, veamos los datos desde un punto de vista técnico:
- La unidad de observación es un cliente
- El dataset consiste en 24 atributos y cada cliente es considerado un punto de dato.
Objetivo
El objetivo de este proyecto es utilizar los atributos contenidos en el dataset (todas las columnas excepto por el pago del siguiente mes) para construir un modelo predictivo que nos avise si el cliente va a pagar o no el próximo mes basado en su información personal y de pagos. Este modelo será utilizado por TFI para tomar acciones ante un potencial moroso y minimizar las pérdidas por estos clientes.
Metodología
Para este problema hay solo dos caminos: El cliente paga el mes siguiente o no lo paga. En este caso, sabemos que nuestra variable objetivo es categórica: puede tener una determinada cantidad de categorías, dos en este caso. Como estamos prediciendo una variable categórica, estamos enfrentandonos ante un problema de clasificación. Este tipo de problemas es de los más comunes en Data Science, porque muchos problemas se resumen basicamente en elección de dos o varias opciones.
- Clasificación binaria: Consiste en predecir dos categorías (pago o moroso).
- Clasificación multiclase: Consiste en predecir más de dos categorías
- Clasificación multietiqueta: El problema de asignar más de una categoría o etiqueta a una observación, por ejemplo, predecir la temática de un nuevo artículo basado en su contenido, pero un artículo puede contener varios temas.
Métricas del modelo
Tenemos que preguntarnos: ¿Como vamos a evaluar si nuestro modelo es suficientemente bueno?. Para responder a esta pregunta, debemos utilizar las métricas adecuadas y hay un amplio y estandarizado uso de herramientas para poder medir la calidad del modelo para problemas de clasificación.
En un escenario real los modelos no hacen predicciones perfectas, por lo que debemos esperar algunos errores. Como estamos lidiando con una variable objetivo binaria, hay dos tipos de errores que el modelo puede hacer:
- Predecir que un cliente va a pagar siendo que en realidad se fue a mora.
- Predecir que un cliente se va a ir a mora siendo que en realidad va a pagar.
Estos dos tipos de errores tienen que ser tomados en consideración cuando decidamos como evaluar nuestro modelo. La metodolog+ia evaluativa debe alinearse con la estrategia de la compañia de minimizar las moras en las tarjetas de crédito.
El manager de TFI le pide no solo predecir si el cliente entrará en default o no, si no que también explicar el porqué el cliente va a caer en una mora. En otras palabras, cuales son las variables que más se asocian al default. A la empresa le gustaría obtener un reporte con un detallado analisis de la situación para tener un mejor entendimiento del problema y tener información para hacer algo al respecto.
Segunda parte: Recolectar y preparar los datos
Ahora que entendemos el problema es hora de poner las manos en la data. Para este ejercicio, los datos fueron conseguidos en el siguiente link.
# importamos las librerías que necesitamos para esta segunda parte.
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")# importamos el dataset.
ccd=pd.read_csv('UCI_Credit_Card.csv',index_col='ID') # utilizamos una columna como index.
# Vemos las primeras 5 observaciones del dataframe
ccd.head()| LIMIT_BAL | SEX | EDUCATION | MARRIAGE | AGE | PAY_0 | PAY_2 | PAY_3 | PAY_4 | PAY_5 | ... | BILL_AMT4 | BILL_AMT5 | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | PAY_AMT3 | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | default.payment.next.month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | |||||||||||||||||||||
| 1 | 20000.0 | 2 | 2 | 1 | 24 | 2 | 2 | -1 | -1 | -2 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 689.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1 |
| 2 | 120000.0 | 2 | 2 | 2 | 26 | -1 | 2 | 0 | 0 | 0 | ... | 3272.0 | 3455.0 | 3261.0 | 0.0 | 1000.0 | 1000.0 | 1000.0 | 0.0 | 2000.0 | 1 |
| 3 | 90000.0 | 2 | 2 | 2 | 34 | 0 | 0 | 0 | 0 | 0 | ... | 14331.0 | 14948.0 | 15549.0 | 1518.0 | 1500.0 | 1000.0 | 1000.0 | 1000.0 | 5000.0 | 0 |
| 4 | 50000.0 | 2 | 2 | 1 | 37 | 0 | 0 | 0 | 0 | 0 | ... | 28314.0 | 28959.0 | 29547.0 | 2000.0 | 2019.0 | 1200.0 | 1100.0 | 1069.0 | 1000.0 | 0 |
| 5 | 50000.0 | 1 | 2 | 1 | 57 | -1 | 0 | -1 | 0 | 0 | ... | 20940.0 | 19146.0 | 19131.0 | 2000.0 | 36681.0 | 10000.0 | 9000.0 | 689.0 | 679.0 | 0 |
5 rows × 24 columns
Como en los atributos pay, del 0 se salta al 2, para simplificar las cosas cambiaremos el nombre de la columna pay_0 a pay_1. También cambiaremos el nombre de la variable objetivo a uno más corto.
ccd=ccd.rename(columns={'PAY_0':'PAY_1', 'default.payment.next.month':'default'})# dimensión del dataframe
print('Cantidad de atributos:{}.\nCantidad de observaciones:{}.'.format(*ccd.shape))Cantidad de atributos: 30000. Cantidad de observaciones: 24.
En realidad, el dataset tiene 25 columnas o atributos, pero como estamos utilizando una columna como index no la considera en el conteo acorde a la documentación
Si vemos na columna que funciona como identificador único para cada observación, es buena práctica utilizarla como index.
# Como vamos a referenciar las columnas varias veces, resulta más conveniente convertirlas en minúsculas.
ccd.rename(columns=lambdax:x.lower(),inplace=True)Exploración numérica
Ahora que vemos que nuestro dataset se importo de manera correcta y con unas pequeñas modificaciones, estamos listos para comenzar la primera exploración en nuestro dataset. Comencemos a crear unas listas que las utilizaremos más adelante.
bill_amt_features = ['bill_amt' + str(i) for i in range(1, 7)]
pay_amt_features = ['pay_amt' + str(i) for i in range(1, 7)]
numerical_features = ['limit_bal', 'age'] + bill_amt_features + pay_amt_featuresVeremos ahora un resumen estadístico área ver si todo luce bien.
ccd[['limit_bal','age']].describe()| limit_bal | age | |
|---|---|---|
| count | 30000.000000 | 30000.000000 |
| mean | 167484.322667 | 35.485500 |
| std | 129747.661567 | 9.217904 |
| min | 10000.000000 | 21.000000 |
| 25% | 50000.000000 | 28.000000 |
| 50% | 140000.000000 | 34.000000 |
| 75% | 240000.000000 | 41.000000 |
| max | 1000000.000000 | 79.000000 |
Comenzando con el cupo de la tarjeta de crédito, vemos un rango entre 10.000 y 1.000.000, con un promedio de 167.000, es decir, la gran parte de los datos se concentra en los primeros deciles. Para la edad el rango es el esperado: de 21 a 79 años.
Veamos ahora como se ven las facturas de las tarjetas.
ccd[bill_amt_features].describe().round()| bill_amt1 | bill_amt2 | bill_amt3 | bill_amt4 | bill_amt5 | bill_amt6 | |
|---|---|---|---|---|---|---|
| count | 30000.0 | 30000.0 | 30000.0 | 30000.0 | 30000.0 | 30000.0 |
| mean | 51223.0 | 49179.0 | 47013.0 | 43263.0 | 40311.0 | 38872.0 |
| std | 73636.0 | 71174.0 | 69349.0 | 64333.0 | 60797.0 | 59554.0 |
| min | -165580.0 | -69777.0 | -157264.0 | -170000.0 | -81334.0 | -339603.0 |
| 25% | 3559.0 | 2985.0 | 2666.0 | 2327.0 | 1763.0 | 1256.0 |
| 50% | 22382.0 | 21200.0 | 20088.0 | 19052.0 | 18104.0 | 17071.0 |
| 75% | 67091.0 | 64006.0 | 60165.0 | 54506.0 | 50190.0 | 49198.0 |
| max | 964511.0 | 983931.0 | 1664089.0 | 891586.0 | 927171.0 | 961664.0 |
Estas son las caracteristicas de las facturas en los últimos 6 meses. Podemos ver que en todos los casos, el valor mínimo es negativo. Esto significa que los clientes tienen un saldo a favor en su tarjeta de crédito, por lo que está bien ver valores negativos para este atributo.
Por el momento, esto se ve bien, es decir, no hay nada extraño que llame la atención. Ahora veremos los pagos históricos de la tarjeta de crédito.
ccd[pay_amt_features].describe().round()| pay_amt1 | pay_amt2 | pay_amt3 | pay_amt4 | pay_amt5 | pay_amt6 | |
|---|---|---|---|---|---|---|
| count | 30000.0 | 30000.0 | 30000.0 | 30000.0 | 30000.0 | 30000.0 |
| mean | 5664.0 | 5921.0 | 5226.0 | 4826.0 | 4799.0 | 5216.0 |
| std | 16563.0 | 23041.0 | 17607.0 | 15666.0 | 15278.0 | 17777.0 |
| min | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 25% | 1000.0 | 833.0 | 390.0 | 296.0 | 252.0 | 118.0 |
| 50% | 2100.0 | 2009.0 | 1800.0 | 1500.0 | 1500.0 | 1500.0 |
| 75% | 5006.0 | 5000.0 | 4505.0 | 4013.0 | 4032.0 | 4000.0 |
| max | 873552.0 | 1684259.0 | 896040.0 | 621000.0 | 426529.0 | 528666.0 |
Como era esperado, los valores mínimos son cero, vale decir, hay clientes que no realizaron ningún pago. Vemos que el promedio es significativamente menor al promedio de la facturación, indicando que los clientes en promedio pagan solo una pequeña fracción de lo facturado.
Por ahora, esta breve inspección no ha mostrado nada inusual y hemos ganado un poco de entendimiento de esta base. Ahora, realizaremos un análisis a las variables categóricas.
Manejando las variables categóricas
Podemos notar que todos los datos que hacen referencia al comportamiento crediticio del cliente son todos datos numéricos, sin embargo, hay variables dentro del perfil del cliente que son categóricos. Estos los tenemos que expresar numéricamente para el posterior uso en el modelo
Hay que tener cuidado cuando utilizamos números representando variables numéricas, dado que muchos modelos consideran estos numeros como representaciones de variables numéricas, es decir, si yo represento un 1 a los hombres y 2 a las mujeres, el modelo tratara esas variables tal cuál son (las mujeres representan dos veces la cantidad de hombres, lo que no tiene sentido) y el modelo nos puede dar distintos resultados dependiendo de la representatividad numérica que toman las variables categóricas. Desde las propiedades matemáticas de los modelos lo mejor es representar estas variables como ceros y unos. Esto se le conoce como one-hot encoding
El caso más simple es cuando tenemos dos casos posibles dentro de una variable categórica, como en la columna sex. Tenemos dos opciones que son equivalentes:
- Crear una nueva columna llamada male y asignar 1 si es hombre y 0 si es mujer.
- Crear una nueva columna llamada female y asignar 1 si es mujer y 0 si es hombre.
Hagamos la primera opción
ccd['male']=(ccd['sex']==1).astype(int)ccd.maleID
1 0
2 0
3 0
4 0
5 1
..
29996 1
29997 1
29998 1
29999 1
30000 1
Name: male, Length: 30000, dtype: int32
En otros contextos, como en econometria, estos tipos de variables se le conocen como variables dummy o variables binarias. También se le puede llamar variables indicadoras, porque el 1 indica la presencia de un atributo.
Asignar ceros y unos es muy conveniente matemáticamente para muchos tipos de modelos. Una de las formas en que podemos aprovechar estas asignaciones numéricas a variables categóricas es calcular la proporción de hombres que hay de una manera simple
ccd.male.mean()0.39626666666666666
Esto quiere decir que el 39,63% del dataset son hombres.
Ahora utilizaremos one-hot encoding en variables con más de dos categorías, por ejemplo el atributo education
# distribución del atributo education
ccd['education'].value_counts(sort=False)education 2 14030 1 10585 3 4917 5 280 4 123 6 51 0 14 Name: count, dtype: int64
Esto es extraño, porque supuestamente tenemos 4 categorías y se muestran 7. Las que no conocemos son el 0, 5 y 6 y no sabemos que representan, por lo que tendremos que utilizar nuestro criterio: pueden ser valores perdidos o pertenecer a otras categorias. Copmo son pocos los valores que no sabemos que representan, vamos a asumir que esos valores pertenecen a la categoría 4, es decir, otro nivel educacional.
Con eso en mente, realizamos la transformación de las variables categóricas.
# transformamos las tres categorías que no pertenecen a "otros"
ccd['grad_school'] = (ccd['education'] == 1).astype(int)
ccd['university'] = (ccd['education'] == 2).astype(int)
ccd['high_school'] = (ccd['education'] == 3).astype(int)No realizamos este cambio para la categoría "otros", porque implicitamente ya tenemos esa información: Cuando las tres categorías anteriores son ceros quiere decir que el cliente no pertenece a ninguno de esos niveles educacionales, es decir, cae en otra categoría, es decir, la categoría "otros".
# Vemos los ID que pertenecen a la categoría otros
ccd.loc[(ccd['grad_school'] == 0) &
(ccd['university'] == 0) &
(ccd['high_school'] == 0)]\
.loc[:,'education']ID
48 5
70 5
359 4
386 5
449 4
..
29837 6
29840 5
29848 4
29921 5
29967 5
Name: education, Length: 468, dtype: int64
Como vimos, para la variable de educación, tres nuevas columnas son necesarias para codificar las variables categóricas a numéricas. De la misma manera, para el atributo sexo solo una columna es necesaria: Si es 1 indica presencia del atributo y si es falsa, ausencia del atributo. Para muchos modelos tener variables redundantes causará problemas.
Esto significa que la suma de estas variables transformadas a numéricas siempre deben sumar 1.
male + female = 1
Cuando usamos one-hot encoding sobre un atributo con K categorías, las variables dummy deben ser K-1, de lo contrario tendremos una colinealidad. La categoría excluida se le conoce como categoria base, porque es la categoría que sirve como referencia o default cuando los indicadores son ceros.
Continuemos ahora con la categoría marriage
# cantidad para cada categoría
ccd['marriage'].value_counts(sort=False)marriage 1 13659 2 15964 3 323 0 54 Name: count, dtype: int64
Supuestamente debemos tener 3 categorías, pero el dataset tiene 4. En el libro esas 54 variables que están en cero aparecen en la categoria de casados, por lo que cambiaremos la categoria 0 por 1.
ccd['marriage'].replace(0,1,inplace=True)ccd['marriage'].value_counts(sort=False)marriage 1 13713 2 15964 3 323 Name: count, dtype: int64
Como tenemos tres categorías, tenemos que transformar la columna "marriage" a dos columnas numéricas. Utilizaremos las categorías "otros" y "soltero"
ccd['single']=(ccd['marriage']==2).astype(int)
ccd['marital_other']=(ccd['marriage']==3).astype(int)print('Proporción de solteros: ',ccd['single'].mean())
print('Proporción de otro estado civil: ',ccd['marital_other'].mean())Proporción de solteros: 0.5321333333333333 Proporción de otro estado civil: 0.010766666666666667
Los porcentajes de otros estados civiles son alrededor del 1%, lo que significa que cerca del 99% de las variables dummy son ceros. Este sesgo en general no produce ninguna información útil al modelo, porque es un atributo casi constante. Estas variables son conocidas como atributos de baja varianza, porque su valor casi nunca varía, por lo que su varianza es cercana a cero.
Si nos encontramos con un atributo que su varianza es muy cercana a cero, será mejor excluirla del dataset, porque no aportará información útil al modelo.
Cercano a la colinearidad
Podríamos pensar que es mejor utilizar solo las variables de casados y solteros para crear variables dummy, dado que deben tener una alta variabilidad entre ellas, vale decir, si no estás casado, debes estar soltero ¿verdad?. Esto quiere decir que married + single = 1 o expresado de otra manera married = 1 - single
Podríamos calcular la colinearidad entre estas dos categorías para comprobar en qué porcentaje se cumple esta igualdad.
ccd['married'] = (ccd['marriage'] == 1).astype(int)
(ccd['married'] == (1 - ccd['single'])).mean()0.9892333333333333
Tenemos que casi un 99% de los casos se cumple la igualdad anterior. En otras palabras, estas dos columnas contienen la misma información en casi el 99% de las observaciones. En este caso lo más apropiado es quedarse con solo un indicador para informar sobre el estado civil de los clientes. Perderiamos la información de 323 clientes que tienen otro estado civil, pero evitariamos el problema de tener atributos de baja varianza.
Introducción a la ingeniería de atributos
La ingeniería de atributos o feature engineering es el proceso de utilizar datos crudos para crear atributos que se utilizaran para el análisis predictivo. Usar, transformar y comnbinar atributos de un dataset para definir nuevos atributos son ejemplos de ingeniería de atributos.
Este proceso es clave y puede ser la diferencia entre un buen modelo o un mal modelo. Hay técnicas estándar para realizar este proceso, pero muchas veces depende de nuestro sentido común, intuición y conocimiento.
Para ejemplificar el uso de ingeniería de atributos, veamos primero la distribución del atributo pay_1
ccd['pay_1'].value_counts().sort_index()pay_1 -2 2759 -1 5686 0 14737 1 3688 2 2667 3 322 4 76 5 26 6 11 7 9 8 19 Name: count, dtype: int64
Recordar que para los valores positivos, el número corresponde a los meses que el cliente se ha atrasado en sus pagos. Sin embargo, están los valores -2 y 0 y desde la descripción del dataset no sabemos que representan, además de que el 0 es el que tiene mayor cantidad de observaciones.
Supongamos que le preguntamos al equipo de TFI para saber que significan esos valores y nos cuentan que -2, -1 y 0 son personas que no tienen atrasados sus pagos ese mes. Sin embargo, ¿deberiamos considerar estos atributos como categóricos o numéricos?
- Podremos transformar los valores -1 y -2 a 0, porque son personas que están atrasadas 0 meses, es decir, no están atrasadas. Este cambio, sin embargo, no es ingeniería de atributos; solo estamos limpiando la data.
- Transformar las variables categóricas a solo dos categorías pay y delayed si es ingeniería de atributos. En este paso reflexionamos que, como hay pocas personas con más de dos meses de atraso con respecto al resto de la data, tiene sentido transformar estas variables a dos categorías.
Desde la perspectiva del rendimiento del modelo, no hay opción de conocer a priori que opción es mejor. Primero comencemos limpiando los atributos pay y luego creamos un nuevo atributo indicando tiempo de atraso para el mes respectivo. En otras palabras, el atributo _delayedi indicará el atraso de un cliente "i" meses atrás.
# limpiamos los atributos pay_i
pay_features = ['pay_' + str(i) for i in range(1, 7)]
for x in pay_features:
ccd.loc[ccd[x] <= 0, x] = 0# producimos atributos de delay
delayed_features = ['delayed_' + str(i) for i in range(1, 7)]
for pay, delayed in zip(pay_features, delayed_features):
ccd[delayed] = (ccd[pay] > 0).astype(int)# Calculamos la proporción de los clientes que se han atrasado en sus pagos por cada mes
ccd[delayed_features].mean()delayed_1 0.227267 delayed_2 0.147933 delayed_3 0.140433 delayed_4 0.117000 delayed_5 0.098933 delayed_6 0.102633 dtype: float64
El resultado muestra que la proporción de atrasos en los pagos ha ido creciendo, especialmente en el último mes (septiembre). Veamos otro ejemplo de ingeniería de atributos: Nuestro sentido común nos dice que el número de meses que el cliente se ha atrasado en los últimos 6 meses puede ser un indicador de que el cliente no pagará el siguiente mes. A pesar de ser una buena hipótesis no sabremos si ese será el caso a menos de que examinemos los datos más cuidadosamente.
# Creamos un nuevo atributo
ccd['months_delayed'] = ccd[delayed_features].sum(axis=1)Estos nuevos atributos presentarán colinealidad en nuestro dataset por que no deberiamos utilizar los nuevos atributos delayed en nuestro modelo, sin embargo, estos nuevos atributos nos pueden ayudar a entender qué factores están detrás de los defaults.
Tercera parte: Explorando el Dataset
EDA Multivariado
Una exploración multivariable explora más de dos variables. Al igual que los otros tipos de exploración, hay formas comunes de trabajar con multivariables, como por ejemplo:
- Colorear un scatterplot para representar una variable categórica.
- Utilizar otra variable categórica en los boxplot
- Utilizar gráficos de celosía para dividir el análisis en diferentes categorías
- Gráficos paralelos.
- Mapas de calor (heatmaps)
# importamos las librerías necesarias para esta sección
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlineUtilizaremos una muestra del dataset para realizar las primeras aproximaciones de exploración para prevenir que los gráficos se vean visualmente muy desordenados. La muestra tomará valores aleatorios de la original.
sample_eda = ccd.sample(n=1000)
sample_eda.columnsIndex(['limit_bal', 'sex', 'education', 'marriage', 'age', 'pay_1', 'pay_2', 'pay_3', 'pay_4', 'pay_5', 'pay_6', 'bill_amt1', 'bill_amt2', 'bill_amt3', 'bill_amt4', 'bill_amt5', 'bill_amt6', 'pay_amt1', 'pay_amt2', 'pay_amt3', 'pay_amt4', 'pay_amt5', 'pay_amt6', 'default', 'male', 'grad_school', 'university', 'high_school', 'single', 'marital_other', 'married', 'delayed_1', 'delayed_2', 'delayed_3', 'delayed_4', 'delayed_5', 'delayed_6', 'months_delayed'], dtype='object')
Comenzaremos gráficando dos variables numéricas y una categórica: los facturas de agosto y septiembre junto con el default. Para gráficar las variables numéricas utilizaremos un diagrama de dispersión y para incluir la variable categórica dentro de este gráfico la distinguiremos por el color de cada observación.
sns.scatterplot(x='bill_amt1', y='bill_amt2', hue='default', data=sample_eda)
plt.show()
Otra aproximación en la exploración con más de dos variables es utilizar un boxplot de la siguiente manera:
sns.boxplot(x='male', y='limit_bal', hue='default', data=sample_eda)
plt.show()
Por otro lado, los gráficos condicionales o de celosía son utilizados para realizar visualizaciones complejas. Seaborn ofrece un método llamado FaceGrid que es perfecta para este tipo de gráficos. Esta opción es útil para comparar multiples variables simultáneamente en subplots o subgráficos.
# creamos la instancia de FacetGrid
p = sns.FacetGrid(sample_eda, col='months_delayed', row='male', hue='default')
# Seleccionar el gráfico que vamos a visualizar en cada subolot
p.map(plt.scatter, 'bill_amt1', 'bill_amt2')
p.add_legend()
plt.show()
Aunque puede ser que esta visualización sea o no sea útil, el punto es demostrar que se puede crear gráficos muy complejos con solo algunas líneas de código.
Como ejemplo final, digamos que queremos comparar la distribución de _limitbal para los clientes que están en default y los que no lo están, separando el análisis en nivel de educación y genero. Utilizaremos FacetGrid nuevamente para realizar este análisis.
edu_levels123 = sample_eda.loc[sample_eda['education'].isin([1, 2, 3])]
p = sns.FacetGrid(edu_levels123, row='male', col='education', hue='default')
p.map(sns.distplot, 'limit_bal', hist=False)
p.add_legend()
plt.show()
Como podemos apreciar en los gráficos, el cupo de la tarjeta de crédito se concentra más o menos en los mismos montos independiente del nivel educacional. Lo que si marca la diferencia en el nivel educaconal es que entre mayor sea el nivel educativo, menos probabilidad tiene el cliente de caer en default.
Cuarta parte: Prediciendo variables categóricas con ML
Cuando tenemos un vector objetivo que intentamos predecir y este vector son variables categóricas estamos ante un problema de clasificación. Este tipo de problemas son los más comunes y utiles en el mundo real.
Utilizaremos para este fin tres algoritmos muy populares y potentes:
- Regresión logística.
- Árboles de clasificación.
- Random Forest.
Prediciendo categorias y probabilidades
Los algoritmos ML de clasificación pueden generar dos tipos de outputs:
Clase predictiva: Por cada observación, el modelo nos dará directamente la predicción de la clase.
Probabilidades para cada clase: Por cada observación y clase, el modelo generará la probabilidad de que una observación pertenezca a cierta clase. Si por ejemplo tenemos tres clases A, B y C, el modelo nos arrojaría tres probabilidades, como [0.2, 0.7, 0.1], vale decir, las probabilidad de la observación de pertenecer a A es de un 20%, para B un 70% y para C un 10%. La clase predictiva en este caso sería B, dado que tiene la mayor probabilidad. Esto sería el funcionamiento por defecto, pero lo podemos modificar dependiendo de los objetivos de nuestro análisis predictivo.
Para clasificación binaria, como es el caso de este ejercicio, generalmente nombramos una clase como la clase positiva que representa un 1 y la otra clase representaría la clase negativa y sería representada con un 0. La clase positiva es la que intentamos predecir. Tener en cuenta que la clase positiva no quiere decir que sea bueno. En este ejercicio, por ejemplo, la clase positiva es que el cliente cayó en default, lo que desde el punto de vista financiero no es para nada bueno.
Ahora, preparamos los datos para el modelo. Por ahora solo utilizaremos una parte de las variables: excluiremos pay_i y delayed_i e incluiremos el months_delayed que es un resumen de las dos variables anteriores.
numerical_features = numerical_features + ['months_delayed']
binary_features = ['male', 'married', 'grad_school', 'university']
X = ccd[numerical_features + binary_features]
y = ccd['default'].astype(int)Partiremos la realización del modelo separando la data en conjunto de entrenamiento y de test. Tenemos 30.000 observaciones; utilicemos 5.000 para el testeo y el resto para entrenamiento.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=5/30, random_state=101)Finalmente, es una buena idea estandarizar las variables numéricas para que estén en la misma escala con un promedio de cero y una desviación estándar de 1.
# Importamos la clase que vamos a utilizar
from sklearn.preprocessing import StandardScaler
# Creamos una instancia de la clase
scaler = StandardScaler()
# Utilizamos el método fit a la instancia
scaler.fit(X_train[numerical_features])
# Utilizamos el método transform para realizar la tranformación
X_train.loc[:, numerical_features] = scaler.transform(X_train[numerical_features])Regresión Logística
Este es un modelo mandatorio cuando realizamos un modelo de clasificación, porque es simple y es utilizando en general como un primer benchmark para evaluar el rendimiento de modelos más complicados. Para clasificación binaria, este modelo produce la probabilidad condicionada de que una observación pertenezca a una clase positiva. Este modelo corresponde a un modelo paramétrico, es decir, el algoritmo intentará encontrar la mejor combinación (vector) de parámetros con el fin de que la probabilidad estimada produzca la siguiente ecuación:
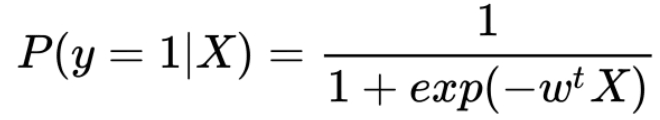
Estamos cerca de 1 si la observación pertenece a una clase positiva y cerca de cero si la observación corresponde a una clase negativa. Por definición este modelo predice probabilidades y utilizamos esta probabilidad para predecir clases. Para entender este algoritmo mejor, utilizemos un modelo simple de regresión lineal con una sola variable: months_delayed.
Modelo simple de Regresión Logística
from sklearn.linear_model import LogisticRegression
simple_log_reg = LogisticRegression(C=1e6)
simple_log_reg.fit(X_train['months_delayed'].values.reshape(-1,1), y_train)LogisticRegression(C=1000000.0)
El estimador fit de scikit-learn espera que X tenga dos dimensiones y no una. Cuando seleccionamos solo una variable estamos trabajando con una dimensión y es ahí donde el método reshape entra en juego. Como su nombre lo indica, cambia la forma de la serie para que sea de dos dimensiones. De la misma manera, cuando utilizamos el método predict también necesitamos que los datos sean de dos dimensiones.
La implementación de una regresión logística es en realidad más sofisticada que el modelo que acabamos de describir. Este incluye regularización para evitar el overfitting. Es por esto que utilizamos un parámetro C muy grande.
Luego de realizar un fit en el modelo calculamos el parámetro W.
print('WO: {}, W1: {}'.format(simple_log_reg.intercept_[0],
simple_log_reg.coef_[0][0]))WO: -1.3814655081995288, W1: 0.8189510522781234
Ahora tenemos todo lo que necesitamos para implementar la ecuación que nos dará la probabilidad de caer en default para un valor de months_delayed
def get_probs(months_delayed):
m = scaler.mean_[-1]
std = scaler.var_[-1]**.5
x = (months_delayed-m)/std
prob_default = 1/(1+np.exp(-simple_log_reg.intercept_[0] \
-simple_log_reg.coef_[0][0]*x))
return prob_defaultNotar que si queremos utilizar los valores originales de la variables debemos estandarizarlas utilizando los valores del objeto entrenado scaler.
Veamos ahora de las probabilidades que produce nuestro modelo.
months = np.arange(13)
pred_probs = get_probs(months)
pd.DataFrame({'months':months, 'pred_probs':pred_probs})| months | pred_probs | |
|---|---|---|
| 0 | 0 | 0.139070 |
| 1 | 1 | 0.214216 |
| 2 | 2 | 0.315105 |
| 3 | 3 | 0.437080 |
| 4 | 4 | 0.567170 |
| 5 | 5 | 0.688615 |
| 6 | 6 | 0.788681 |
| 7 | 7 | 0.862988 |
| 8 | 8 | 0.914014 |
| 9 | 9 | 0.947200 |
| 10 | 10 | 0.968026 |
| 11 | 11 | 0.980804 |
| 12 | 12 | 0.988536 |
Esta probabilidad hace mucho sentido, dado que, es lógico pensar de que entre más se atrase un cliente en hacer frente a sus pagos, más probabilidades tiene de caer en default, dado que los gastos se van acumulando en el tiempo. Según este modelo, cerca del 14% de los clientes que no se han atrasado en sus pagos en los últimos 6 meses entrarán eventualmente en default.
Un gráfico es útil para visualizar las probabilidades producidas por este modelo como una función de los meses atrasados.
fig, ax = plt.subplots()
ax.plot(months, pred_probs)
ax.set_xlabel('Months delayed')
ax.set_ylabel('Probability of default')
ax.grid()
Con esta visualización se enclarece un poco como la regresión logística produce las probabilidades.
Modelo completo de Regresión Logística
Ahora entrenemos un modelo utilizando todas las variables seleccionadas.
log_reg = LogisticRegression(C=1e6)
log_reg.fit(X_train, y_train)LogisticRegression(C=1000000.0)
Sabemos que el modelo recién entrenado produce probabilidades como output. Para ver estas probabilidades podemos utilizar el método predict_proba que producirá una matriz Numpy de dos dimensiones donde cada columna nos entrega la probabilidad de que la observación pertenezca a una de las clases. La primera columna está asociada a la probabilidad de que la observación pertenezca a la clase negativa (etiquetada como cero) y la segunda a la clase positiva (etiquetada como uno).
prob_log_reg = log_reg.predict_proba(X_train)
prob_log_reg[:10]array([[0.80598824, 0.19401176], [0.89229593, 0.10770407], [0.80277761, 0.19722239], [0.85895218, 0.14104782], [0.19880704, 0.80119296], [0.82365192, 0.17634808], [0.70963659, 0.29036341], [0.79608637, 0.20391363], [0.81817667, 0.18182333], [0.738365 , 0.261635 ]])
Como son probabilidades cada una de las filas de la matriz suma uno. Si no quisieramos la probabilidad, sino que quisieramos la predicción de la clase, podemos utilizar el método predict.
y_pred_log_reg = log_reg.predict(X_train)
y_pred_log_reg[:10]array([0, 0, 0, 0, 1, 0, 0, 0, 0, 0])
Como se mencionó anteriormente, estas clases son producidas por probabilidades: cuando la probabilidad es mayor a 0.5 en la segunda fila de predict_proba, el resultado es 1 o clase positiva. Podemos verificar esto con el siguiente código:
np.all(y_pred_log_reg == (prob_log_reg[:,1] > .5))True
Ahora que ya terminamos de construir el modelo veamos los coeficientes asociados a cada variable utilizada para modelar.
pd.Series(data=log_reg.coef_[0], index=X_train.columns).sort_values(ascending=False).round(2)months_delayed 0.75 bill_amt2 0.21 bill_amt3 0.18 married 0.17 grad_school 0.13 male 0.11 university 0.11 age 0.06 pay_amt3 -0.00 pay_amt4 -0.02 pay_amt5 -0.03 bill_amt5 -0.04 pay_amt6 -0.04 bill_amt6 -0.06 bill_amt4 -0.06 bill_amt1 -0.16 limit_bal -0.18 pay_amt1 -0.23 pay_amt2 -0.31 dtype: float64
Una interpretación cruda de estos coeficientes es que los positivos están relacionados directamente a la probabilidad lo que significa que entre mayores valores observados aumentará la probabilidad de default y valores pequeños tenderán a disminuir esa probabilidad.
Esta interpretación es valida si no hay una alta correlación entre estas variables, pero sabemos que las hay y por eso tenemos que tener cuidado con la interpretación de los números que se nos presentan. Sin embargo, hace sentido de que months_delayed sea la variable con mayor peso para que la probabilidad de default aumente.
Ahora que realizamos el modelo, veamos las primeras métricas para medir la calidad de este. Una de estas es el accuracy o exactitud. Esta es la métrica más simple para evaluar una clasificación. Es definida como la proporción o porcentaje de predicciones correctas. Una correcta predicción es cuando tenemos que la clase predicha es la misma que la clase observada.
from sklearn.metrics import accuracy_score
accuracy_log_reg = accuracy_score(y_true=y_train, y_pred=y_pred_log_reg)
accuracy_log_reg>0.80364
Obtuvimos una exactitud o accuracy del 0.80372, es decir, un 80.37% de las predicciones realizadas son correctas. Mientras reflexionamos si este resultado se ve bien, veamos otro famoso modelo.
Árboles de clasificación
Los árboles de clasificación o classification trees en inglés son también un algoritmo popular, porque son muy transparentes y fáciles de entender. Este algoritmo pertenece a la categoría de métodos no paramétricos y pueden ser utilizados tanto para regresiones como para clasificaciones. La manera de generar predicciones es creando una serie de reglas que son aplicadas consecutivamente hasta que lleguemos a una "hoja" o nodo que contiene la clasificación especifica.
Para que quede más claro como funciona, utilizaremos una visualización para ver el árbol que se forma luego de entrenar el modelo.
Por ahora no nos preocupemos por los hiperparámetros que utilizaremos para crear el árbol.
from sklearn.tree import DecisionTreeClassifier
class_tree = DecisionTreeClassifier(max_depth=3)
class_tree.fit(X_train, y_train)from sklearn import tree
plt.figure(figsize=(20, 10))
tree.plot_tree(class_tree,
filled=True, rounded=True,
feature_names = X_train.columns,
class_names = ['pay','default'],
fontsize=12)
plt.show()
Esto es una representación gráfica de las reglas que produce el modelo: se comienza arriba del árbol y se realiza una prueba condicional y si esta condición es cierta, se abre una hoja a la izquierda y a la derecha si es falsa. Es como contestar una serie de preguntas cerradas (si/no) de la información de un cliente. Suponga que tiene la información de una observación y luego comienza a responder preguntas de la siguiente manera:
- Es month_delayed <= 0.419. Sí --> vaya a a izquierda.
- Es month_delayed <= -0.22. No --> vaya a a derecha.
- Es month_delayed <= -0.696. Sí --> vaya a a izquierda y prediga lo que el consumidor pagará.
En el árbol podemos ver que los nodos predicen el pago, porque de 271 clientes, donde la respuesta fue la misma (ver tercer nodo en la tercera capa del árbol), 229 terminan pagando la tarjeta de crédito el mes siguiente.
Quizás sea más simple ver esto con proporciones en vez de con conteo. Podemos hacer esto seteando proportion a True.
plt.figure(figsize=(20, 10))
tree.plot_tree(class_tree,
filled=True, rounded=True,
feature_names = X_train.columns,
class_names = ['pay','default'],
fontsize=12,
proportion=True)
plt.show()
Como podemos ver en la hoja más a la izquierda, solo un 16,4% de los clientes terminan en default, comparando con la hoja más a la derecha que es de un 70,5% están en default. No hay duda que este modelo es muy util para obtener información importante acerca de las posibles causas que llevan al default.
¿Cómo funcionan los árboles?
Escencialmente, los árboles producen sus predicciones separando el espacio de las variables en regiones rectangulares. Sé que esa definición se entiende poco o nada, asi que es mejor que veamos un ejemplo.
El método de partición se llama división binaria recursiva y funciona así: Imagine que tenemos dos categorías que queremos clasificar: morado y amarillo. Imagine también que tenemos dos variables y queremos dividir una de ellas para que el espacio sea dividido en dos regiones. El objetivo es hacer que estas dos regiones sean lo más "puras" y homogeneas posibles. Primero, debemos responder a estas preguntas:
1) ¿Qué variable deberías separar primero?
2) ¿En qué punto se debería realizar la separación?
Respondiendo a estas dos preguntas nos dará la primera regla en en tronco del árbol o en la parte más alta de este.
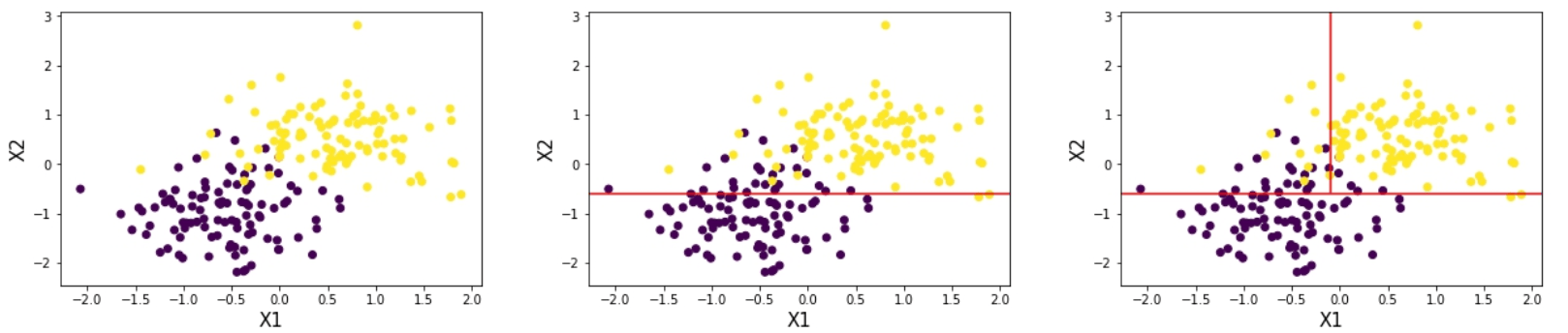
En la primera imagen, una buena conjetura para responder las preguntas anteriores seria:
1) ¿Qué variable deberías separar primero? X2
2) ¿En qué punto se debería realizar la separación? -0.6
Así tenemos nuestra primera partición correspondiente a X2 >= -0.6
Esto nos entrega la segunda imagen de izquierda a derecha.
Ahora, debemos responder exactamente la misma pregunta, pero ahora para la región de arriba de la segunda imagen. Tenemos las siguientes respuestas:
1) ¿Qué variable deberías separar primero? X1
2) ¿En qué punto se debería realizar la separación? -0.1
Esto nos entrega la tercera imagen de izquierda a derecha.
Por último, respondemos estas preguntas para la última división.
1) ¿Qué variable deberías separar primero? X1
2) ¿En qué punto se debería realizar la separación? 0.7
Esto nos entrega la tercera imagen de izquierda a derecha.
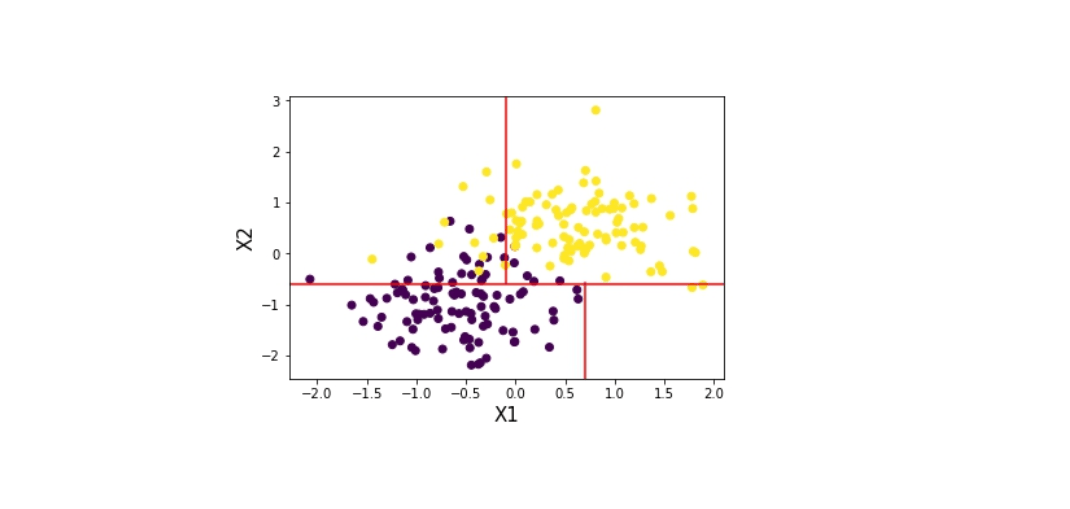
Ahora tenemos un pequeño árbol que puede estar representado de la siguiente manera: ¿Es X2 >= -0.6?
-
Si es verdad, ¿Es X1 >= -0.1?
- Si es verdad, (arriba a la derecha) predecir amarillo
- Si es falso, (arriba a la izquierda) predecir morado.
-
Si es falso, ¿Es X1 >= 0.7?
- Si es verdad, predecir amarillo.
- Si es falso, predecir morado.
Esta aproximación de partición de variables continua hasta que se alcance un criterio para detener la iteración, como el máximo tamaño del árbol o el mínimo número de hojas o muestras que consideramos en la caja donde realizamos las particiones. Este control del tamaño del árbol lo podemos ajustar nosotros en los parámetros del modelo. Los parámetros más comunes que podemos modificar son los siguientes:
- max_depth: Es la máxima profundidad del árbol. Si no se le entrega ningún valor, las hojas o nodos se expanden hasta que no puedan expandirse más o hasta que las hojas contengan una muestra menor a min_samples_split.
- min_samples_split(default=2): El mínimo número de muestras requerido para separar un nodo interno. Si es un número entero considera min_samples_split como el mínimo número de muestras, pero si es un número decimal min_samples_split es un porcentaje y el techo (min_samples_split * n_samples) es el número mínimo de muestras para cada separación.
- min_samples_leaf (default=1): Es el número mínimo de muestras necesarias para estar en un nodo hoja. Si es un número entero, considera min_samples_leaf como el número mínimo y si es un número decimal es un porcentaje y el techo (min_samples_leaf * n_samples) es el número mínimo de muestras para cada nodo.
Hay algunos parámetros que controlan el tamaño y la separación de los árboles, pero necesitamos tener un conocimiento más técnico para poder ajustarlos. El algoritmo de scikit-learn realiza la separación que nosotros pusimos a criterio llamado indice de Gini (Index Gini) u otro llamado entropía (entropy).
También tener en consideración que hay muchos tipos de variación de árboles, como el ID3, C4.5, C5.0 y CART. Cada uno tiene distintas técnicas y razones teóricas para construir los árboles entre una u otra manera. Es recomendable mirar Loh, W.Y. (2008) para un entendimiento más profundo del tema.
Lo bueno y lo malo de los árboles
Aquí se describen algunas ventajas de utilizar árboles de decisión:
1) Son fáciles de entender y explicar.
2) Las reglas son fáciles de implementar.
3) Es computacionalmente eficiente para producir predicciones.
4) Con un pequeño preprocesamiento, los árboles de decisión no están afectos a predictores a distintas escalas o sesgados.
Algunas desventajas son:
1) Su poder de predicción por lo general es menor a otros modelos, por lo que no podemos esperar un accuracy muy alto.
2) Pueden ser inestables: pequeños cambios en el dataset pueden llevar a diferentes reglas. Técnicamente, a eso se le conoce como modelos de alta varianza.
3) Pueden estar sobreajustados fácilmente.
4) Por su simplicidad de sus reglas if-then, hay algunas interacciones complejas que el modelo no puede aprender.
La documentación de scikit-learn para árboles de decisión muestra tips muy utiles para usos prácticos.>
Entrenando árboles de decisión más grandes
Ahora que sabemos como trabaja un árbol de decisión, veamos un árbol más grande. Para mantener las cosas simples, vamos a mantener los parámetros por defecto a excepción de max_depth y min_samples_split para controlar el tamaño del árbol.
class_tree = DecisionTreeClassifier(max_depth=6, min_samples_split=50)
class_tree.fit(X_train, y_train)
y_pred_class_tree = class_tree.predict(X_train)Para calcular la exactitud (accuracy) en el conjunto de entrenamiento, utilizamos lo siguiente:
accuracy_class_tree = accuracy_score(y_true=y_train, y_pred=y_pred_class_tree)
accuracy_class_tree0.80824
Obtuvimos un 80.8% un accuracy, lo que es similar a lo obtenido por la regresión logística.
Finalmente, otra característica de este modelo es que podemos obtener las variables importantes que permiten clasificar la variable objetivo utilizando el método featureimportances
pd.Series(data=class_tree.feature_importances_, index=X_train.columns).sort_values(ascending=False).round(3)>months_delayed 0.828 pay_amt2 0.042 bill_amt1 0.022 limit_bal 0.020 pay_amt1 0.018 bill_amt2 0.015 bill_amt6 0.011 pay_amt4 0.010 bill_amt5 0.007 pay_amt3 0.007 age 0.006 pay_amt6 0.004 pay_amt5 0.003 bill_amt3 0.003 grad_school 0.002 bill_amt4 0.002 male 0.000 married 0.000 university 0.000 dtype: float64>
La variable más importante por lejos para este modelo es months_delayed y no le da importancia al género, si se está casado(a) y la educación, entre otras variables.
pd.Series(data=class_tree.feature_importances_, index=X_train.columns).sort_values(ascending=False).plot(kind='bar')
plt.show()
Los árboles son la base para uno de los modelos más poderoso para realizar predicciones precisas: random forest.
Random Forest
Una de las cosas buenas de los árboles es su simplicidad, pero esto mismo causa sus problemas. A finales de 1980 dos investigadores (Kearns y Valiant) se preguntaron si un conjunto de aprendizajes débiles podrían crear un solo aprendizaje fuerte. Esta pregunta fue causa de gran investigación de lo que llamamos métodos ensamblasadores o aprendizaje ensamblazador. La idea detrás de esto es utilizar varios modelos individuales y combinar sus predicciones. Esta simple idea ha sido la llave de éxito para realizar modelos muy precisos.
Hay algunos conceptos importantes para un aprendizaje ensamblazador. Estos son:
- Muestreo de Bootstrap: Si tienes un dataset D de n observaciones, entonces el muestreo de bootstrap consiste en elegir al azar n muestras y reemplazarlas en D. Por ejemplo D = [1, 2, 3, 4, 5]; un muestreo bootstrap sería D* = [5, 5, 1, 2, 2]. Vemos valores repetidos, porque el proceso de muuestreo fue realizado con reemplazos.
- Bagging: Esta palabra viene de "bootstrap aggregating" y es el proceso de tomar K muestreos bootstrap y entrenar K modelos en cada uno de estos bootstrap. Luego, combinamos estas predicciones individuales promediando en el caso de regresión o con la regla de mayoria de voto en el caso de clasificación. Bagging es el proceso básico de random forest, pero aplica una pequeña variación para decorrelacionar los predictores individuales.
Un random forest o bosque aleatorio es un bosque porque se basa en predicciones individuales a través de árboles y es aleatorio, porque la decorrelación de cada predictor se basa en utilizar una muestra aleatoria de las variables cuando separamos los árboles. Por ejemplo, podemos tener 15 variables y para el primer árbol se eliguen las variables 1, 4 y 5, para el segundo árbol elegimos 5, 6, 7, 3 y 8 y así. Hay más detalles técnicos, pero esa es la idea general de su funcionamiento.
Como estamos trabajando tanto con árboles individuales como con varios árboles en su conjunto o ensamble debemos ingresar dos hiperparámetros para cada uno. Esto hace que los random forest sean más dificiles de optimizar. Sin embargo, los parámetros por defecto suelen ser buenos.
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators = 99,
max_features = 5,
max_depth = 4,
min_samples_split = 100,
random_state = 85)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_train)Ahora, veamos como el accuracy dentro del conjunto de entrenamiento.
accuracy_rf = accuracy_score(y_true=y_train, y_pred=y_pred_rf)
accuracy_rf0.79748
Nos dio un 79,74% que no es muy lejos de lo que nos ha resultado los otros modelos.
Este modelo también puede medir las variables principales del modelo.
pd.Series(data=rf.feature_importances_, index=X_train.columns).sort_values(ascending=False).round(3)months_delayed 0.608 pay_amt1 0.081 limit_bal 0.065 pay_amt2 0.050 pay_amt3 0.042 bill_amt2 0.027 pay_amt4 0.020 bill_amt4 0.019 bill_amt3 0.019 bill_amt1 0.015 pay_amt6 0.015 bill_amt5 0.012 bill_amt6 0.011 pay_amt5 0.010 age 0.003 grad_school 0.001 married 0.000 male 0.000 university 0.000 dtype: float64
Esto es similar a los resultados del árbol de decisión, donde months_delayed es el ganador indiscutido.
Entrenamiento vs Testing
Ahora que hemos visto y entrenado tres modelos, evaluaremos su accuracy o exactitud en el conjunto de entrenamiento y el conjunto de test. Estos modelos nos dieron un accuracy alrededor del 80%. Sin embargo, tenemos que tener un punto de referencia o benchmark para saber si un 80% es un buen o un mal número y para ello debemos responder la pregunta ¿En la ausencia de información acerca del cliente, cuál sería tu mejor conjetura acerca del status de pago del siguiente mes?. La respuesta a esta pregunta sería nuestro punto de referencia para saber si estamos ante un buen rendimiento. Como la mayoria de los clientes pagaron, nuestra mejor conjetura sería que el próximo mes el cliente va a pagar. Como tenemos que el 77,9% de las observaciones pertenecen a la categoría "pay" el modelo nulo (sin información) estaría correcto el 77,9% de las veces. Podemos verificar esto utilizando el conjunto de test.
y_pred_null = np.zeros_like(y_test)
accuracy_score(y_true=y_test, y_pred=y_pred_null)>0.782
En realidad obtuvimos un 78,2% y eso comparado con el 80% vemos que nuestros modelos no se ven muy bien. Sin embargo, esto no significa que el modelo sea inútil. Quizás no lo estamos juzgando apropiadamente. Veremos la evaluación de modelos de clasificación más adelante, pero por ahora vamos a calcular el accuracy en los conjuntos de entrenamiento y test para nuestros tres modelos.
# Estandarizamos los valores numéricos en nuestro conjunto de test.
X_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])
# Calculamos el accuracy o exactitud
accuracies = pd.DataFrame(columns=['train', 'test'], index=['LogisticReg', 'ClassTree', 'RF'])
model_dict = {'LogisticReg': log_reg, 'ClassTree': class_tree, 'RF': rf}
for name, model in model_dict.items():
accuracies.loc[name, 'train'] = accuracy_score(y_true=y_train,
y_pred=model.predict(X_train))
accuracies.loc[name, 'test'] = accuracy_score(y_true=y_test,
y_pred=model.predict(X_test))
accuracies| train | test | |
|---|---|---|
| LogisticReg | 0.80364 | 0.8058 |
| ClassTree | 0.80824 | 0.8074 |
| RF | 0.79748 | 0.7922 |
Los modelos se ven muy parecidos tanto en el conjunto de entrenamiento como el de test. Veamos como se ven gráficamente.
fig, ax = plt.subplots()
accuracies.sort_values(by='test', ascending=False).plot(kind='barh', ax=ax, zorder=3)
ax.grid(zorder=0)
Naive Bayes
Naive Bayes es un algoritmo de clasificación que basa su estrategia en el teorema de Bayes o probabilidad condicional, es decir, cuál es la probabilidad de que un evento B suceda si ya sucedió el evento A. Veamos un ejemplo con tres diferentes eventos.
- Evento A: Un cliente entra en default.
- Evento B: Un cliente es hombre.
- Evento C: Un cliente está entre los 30 y los 39 años.
Si elegimos un cliente aleatoriamente estamos asumiendo que podemos obtener la probabilidad de cada uno de los eventos descritos anteriormente.
N = ccd.shape[0]
Prob_A = (ccd['default']==1).sum()/N
Prob_B = (ccd['male']==1).sum()/N
Prob_C = ((ccd['age']>=30) & (ccd['age']<=39)).sum()/N
print("P(A) = {:0.4f}; P(B) = {:0.4f}; P(C) = {:0.4f}".format(Prob_A, Prob_B, Prob_C))P(A) = 0.2212; P(B) = 0.3963; P(C) = 0.3746
La probabilidad condicional se puede leer así: Si estamos buscando solo los clientes que son hombres (los hombres es un evento certero), la probabilidad de que entre en default está dado por un ratio entre dos probabilidades:
- numerador: La probabilidad de que ambos eventos pasen simultaneamente (intersección de ambos eventos)
- denominador: La probabilidad de que el cliente sea hombre.
Realicemos este cálculo.
numerator = ((ccd['default'] == 1) & (ccd['male'] == 1)).sum()/N
denominator = Prob_B
Prob_A_given_B = numerator / denominator
print("P(A|B) = {:0.4f}".format(Prob_A_given_B))P(A|B) = 0.2417
Entonces la probabilidad de que un hombre entre en default es de 24.17%. Obtendremos el mismo resultado si filtramos nuestro dataset para incluir solo los machos y luego calcular la proporción de clientes que están en default.
only_males = ccd.loc[ccd['male'] == 1]
only_males['default'].value_counts(normalize=True)0 0.758328 1 0.241672 Name: default, dtype: float64
Teorema de Bayes
La formula del teorema de Bayes es una formula que expresa la probabilidad condicional en términos de la distribución de probabilidad condicional del evento B dado A.
$P(A|B) = \frac{P(A|B)P(A)}{P(B)}$
Esta formular es muy util, pero no es tan obvia de entender. Lo primero que hay que entender es la relación existente entre P(A|B) y P(B|A). Veamos un ejemplo.
- P(A|B) = P(default|hombre) = probabilidad que un cliente hombre entre en default.
- P(B|A) = P(hombre|default) = probabilidad que un cliente en default sea hombre.
En la primera probabilidad condicional buscamos a hombres y luego calculamos la probabilidad que entren en default y en la segunda buscamos a los que están en default y calculamos la probabilidad de que sean hombres. Calculemos la probabilidad de ambos para comprobar de que no son lo mismo.
only_males = ccd.loc[ccd['male'] == 1]
Prob_default_given_male = (only_males['default']==1).sum()/only_males.shape[0]
Prob_default_given_male0.2416722745625841
Ahora calculemos la probabilidad condicional
only_defaults = ccd.loc[ccd['default'] == 1]
Prob_male_given_default = (only_defaults['male'] == 1).sum()/only_defaults.shape[0]
Prob_male_given_default0.43294153104279687
En otras palabras, si tenemos a un cliente que está en default, tenemos una probabilidad de un 43,29% que sea hombre.
Ahora que sabemos que el teorema de Bayes nos dará una relación entre la probabilidad de A si ocurre B y viceversa, podemos calcular directamente la probabilidad condicional
Prob_default = Prob_A
Prob_male = Prob_B
Prob_male_given_default * Prob_default / Prob_male0.24167227456258414
Este es el mismo número que habiamos calculado previamente. La utilidad del teorema de Bayes se da cuando conocemos una probabilidad condicional, como P(A|B) y queremos saber la probabilidad condicional inversa, es decir, P(B|A)
Utilizando el término Bayesiano
Tomando el ejemplo anterior, podemos desglosar el teorema de Bayes en sus distintas partes:
-
P(default|male): Es la probabilidad posterior o simplemente posterior, es la probabilidad de que ocurra un evento de interés después de que ya sepamos algunos hechos, en este caso que el consumidor es hombre.
-
P(default): A esto se le llama probabilidad previa o simplemente previo. Es la probabilidad del evento antes de considerar cualquier información.
-
P(male|default): Es la probablidad de que el evento de interés sea cierto, sabiendo que la información del segundo evento es cierta. Es el likelihood del evento.
-
P(male): Es la probabilidad de la información o del segundo evento. Esto es referido como la evidencia del segundo evento.
Con esto, tenemos que la formula es así: $posterior = \frac{likelihood*previo}{evidencia}$
En definitiva, lo que intentamos hacer cuando realizamos una clasificación con esta formula es saber la probabilidad posterior de un evento sabiendo que tenemos información nueva. Si no la tuvieramos, solo tendremos que la probabilidad que el cliente esté en default es de un 22.12%. Cuando tenemos información adicional eso cambia bastante el escenario para poder realizar predicciones de clases. No necesariamente nos limitaremos a un evento seguro o evidencia; podemos tener varios eventos que son verdaderos, como por ejemplo tener que la edad de un cliente es de 35 años y su cupo de tarjeta de crédito es de 150.000 dólares. Esto es un ejemplo de probabilidad conjunta dónde ambos eventos son verdaderos.
Cuando agregamos más eventos seguros a una probabilidad conjunta la formula de Bayes se va alargando siendo apenas legible. La complejidad que toma la resolución de la formula es cuando aparece Naive Bayes a realizar su rol. Suponemos, sin embargo, que todas las variables son independientes, es decir, no hay relación por ejemplo entre la edad y el cupo disponible del cliente. Esta asunción es ingenua dado que en casi todos los datasets las variables tienen algún grado de dependencia. Esta asunción nos permite simplificar la formula, porque la probabilidad conjunta de variables independientes es la multiplicación de estas probabilidades.
Ahora cuando calculemos las cantidades tal que P(age=35 | default) entraremos en otra asunción ingenua: En el caso de variables continuas, asumimos que podemos obtener la probabilidad de los eventos tal que P(age=35|default) asumiento que P(age|default) tiene una distribución normal.
# Este dataframe contiene solo valores default.
sns.distplot(only_defaults['age'], hist=False)
plt.title('P(age | default)')Text(0.5, 1.0, 'P(age | default)')

No se ve como una distribución normal, pero la asunción no es tan disparatada. Hacemos la misma asunción para las demás variables para calcular las probabilidades respectivas. Este miembro de la familia de Naive Bayes se llama Gaussian Naive Bayes.
Gaussian Naive Bayes
A pesar de sus asumpciones, este tipo de clasificador es muy eficiente en muchas tareas, como clasificación de documentos y filtros de spam en los correos. La formula de Gaussian Naive Bayes es la siguiente para la predicción de la variable dependiente.
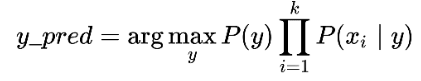
Donde se busca maximar el producto de las probabilidades condicionadas de Xi sabiendo la probabilidad de y.
Lo que hace scikit-learn internamente al entrenar este algoritmo es estimar los parámetros de la distribución Gaussiana de cada uno de las variables y luego calcula la multiplicación de cada probabilidad condicionada para finalmente darnos un predictor donde se maximiza la probabilidad de y.
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(X_train[numerical_features], y_train)
y_pred_gnb = gnb.predict(X_test[numerical_features])accuracy_score(y_true=y_test, y_pred=y_pred_gnb)0.4182
Un resultado muy malo, al menos desde el punto de vista del accuracy. Quizás Gaussian Naive Bayes no es un buen algoritmo para este problema, pero eso está bien, algunos algoritmos funcionan bien para ciertos problemas y mal para otros. Si tienes solo variables categóricas puedes usar otros miembros de la familia Naive Bayes, como Multinomial Naive Bayes o Bernoulli Naive Bayes para variables binarias. La formulación matemática sigue siendo la misma.
Introducción a las redes neuronales para el análisis predictivo.
Las redes neuronales forman parte del área de deep learning o lenguaje profundo. Son utilizados en general para resolver problemas complejos como autos autónomos, traductor, reconocimiento de voz, visión de computación, nivel sobrehumano en distintos juegos, etc. Para comenzar, veremos un tipo básico de red neuronal llamado MLP (multilayer perceptron) para realizar predicciones.
Deep Learning es una subárea de Machine Learning basados en modelos llamados redes neuronales. Estos modelos son construidos en una serie de capas dónde cada capa recoge un input que equivale a un output de la capa anterior. Cada capa exitosa en una red neuronal puede ser vista como una representación cada vez más significativa de las variables. La palabra "deep" en deep learning tiene relación con el número de capas que son utilizadas en una red neuronal. Algunos modelos arquitectónicos requieren decenas o incluso cientos de capas y son capaces de aprender tareas muy complejas, como las que mencionamos anteriormente. El éxito de estos modelos viene de la habilidad de aprender automáticamente representaciones útiles de datos no estructurados, como videos, audios, imagenenes, textos, entre otros.
No hay un concenso para definir cuántas capas se necesitan para que un modelo pueda ser considerado como deep learning, pero como referencia, 24 capas o más puede ser considerado para muchas personas como un modelo de deep learning.
Las redes neuronales son inspiradas por la estructura del cerebro. Al igual que las neuronas del cerebro que están conectadas entre si para realizar ciertas tareas, las neuronas de un modelo de machine learning también están conectadas y también realizan calculos, formando una red interconectada de neuronas llamada unidad. La comparación termina aquí, dado que el cerebro tiene una complicada estructura y hay muchas cosas del cerebro que aún no sabemos, por lo tanto el funcionamiento de un modelo de deep learning y el funcionamiento del cerebro está muy lejano aún.
Como nuestra base de datos es relativamente pequeña, no construiremos un modelo de deep learning muy complejo, si no que tendrá pocas capas. La idea es representar los conceptos fundamentales y aprender como entrenar el tipo más fundamental de una red neuronal: Las MLP.
Anatomía de los elementos en un MLP
Hay muchos términos que hay que conocer para entender el funcionamiento de una red neuronal. Algunos de estos elementos tienen que ver con los modelos de redes neuronales y otros con el proceso de entrenamiento. Comencemos describiendo la jerarquía que define un modelo: Las redes neuronales están hechas de capas y las capas están hechas de neuronas.
Neuronas
Las neuronas o neuronas artificiales son la unidad computacional de una red neuronal. Estas neuronas son funciones matemáticas que reciben n inputs o un vector y retorna un output.
$output = g(W_1X_1 + W_2X_2 + W_3X_3 + W_nX_n + b) = g(\sum_{i=1}^{n} W_iX_i + b)$
La visualización de una neurona con dos inputs se ve de esta manera:
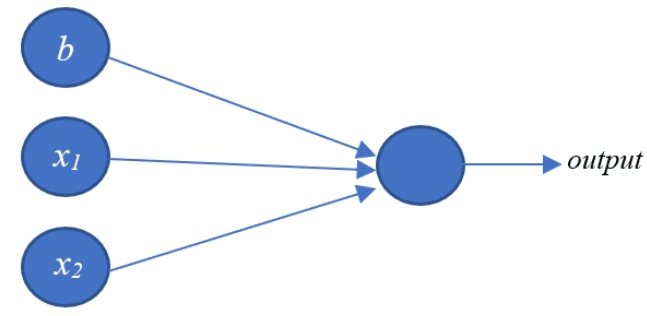
Estos tipos de neuronaes tienen tres elementos:
1) Peso: Son el set de las W que están en la formula y que están multiplicando a cada input.
2) Sesgo (bias): Es la letra "b" en la ecuación que es añadida a la suma. Hay una razón técnica de porque esta constante hará mejor el modelo.
3) Función de activación: En la formula es la "g" y es el componente que introduce la no-linealidad en el modelo. Hay activaciones estándares como la sigmoide, la tangente hiperbólica o el ReLu. A continuación podemos ver como se ven cada una de estas funciones de activación.
x = np.linspace(-5, 5, 200)
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(10, 4))
ax[0].plot(x, 1/(1+np.exp(-x)))
ax[0].set_title('Sigmoide')
ax[1].plot(x, np.tanh(x))
ax[1].set_title('Tangente Hiperbólica')
ax[2].plot(x, np.maximum(0, x))
ax[2].set_title('ReLu')
for p in ax:
p.grid()
Capas
Las capas son hechas de neuronas. Una capa es como un modulo de procesamiento de datos del modelo: este recibe un inputs y produce outputs. Matemáticamente, una capa puede ser considerada como una función que recibe k inputs y retorna m outputs. Las capas son los componentes que extraen representaciones útiles de los datos. Hay distintos tipos de capas y nosotros veremos el tipo de capa densa o totalmente conectada.
Red Neuronal
Este es el modelo que consiste en un número de capas exitosas. Dependiendo de su posición, las capas se definen de la siguiente manera:
- Capa de entrada: Esta es la capa que consiste en nuestros atributos del dataset.
- Capa oculta: Son las capas internas de una red neuronal. Aqui es donde el procesamiento y el aprendizaje se lleva a cabo.
- Capa de salida: Es la capa que produce el resultado. En el caso de una regresión, esta capa sería la predicción y en el caso de una clasificación sería usualmente la probabilidad de pertenecer a cada categoría.
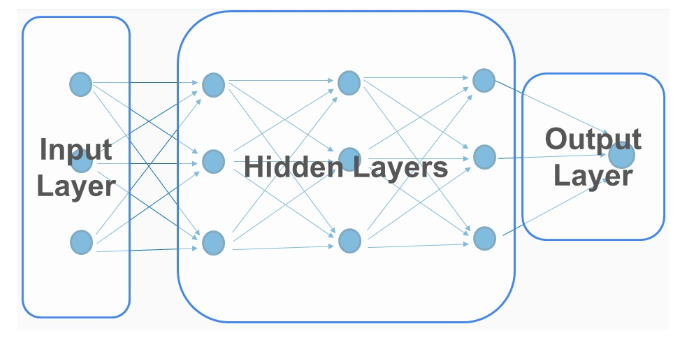
Como aprender los MLPs
Los MPL pueden ser considerados como los modelos paramétricos, asi como la regresión multiple, entrenar un MLP significa encontrar el conjunto correcto de pesos (W) y sesgos (b) de tal manera que el modelo aprenda a utilizar los atributos del dataset para producir el valor objetivo. En un modelo de regresión multiple, el conjunto de pesos hará que no haya otra combinación que minimice la sumatoria del error cuadrático. Con un modelo MLP intentamos hacer algo similar: encontrar la mejor combinación de peso para realizar buenas predicciones. Sin embargo, hay razones técnicas de porque no es posible encontrar el mejor conjunto de pesos, por lo que entrenar un modelo MLP significa encontrar el conjunto de pesos y sesgo que sea "suficientemente bueno" para que el modelor realice buenas predicciones.
El proceso de entrenamiento de un MLP comienza con definir aleatoriamente el conjunto de pesos. El sesgo generalmente comienza con 1. Hay algunas reglas y mejores prácticas para una inicialización aleatoria y estas mejores prácticas están construidas dentro de las librerías de deep learning. Luego de realizar esta inicialización aleatoria, podemos comenzar el entrenamiento que consta de los siguientes pasos:
1) Conseguir un lote: Conseguir un lote de muestras de entrenamiento y sus objetivos correspondientes. Generalmente, las redes neuronales trabajan con datasets muy grandes y por la forma en que son entrenados, no procesan todo el conjunto de entrenamiento de una sola vez. En vez de eso, los datos son divididos en lotes y los datos van pasando por la red neuronal uno a la vez. El tamaño del lote es el monto de muestras en el lote. Por convención, los lotes son en general en exponentes de dos, como 32, 64, 128, 256 o 512. Sin embargo, puedes usar cualquier valor, como 100. Hay una buena evidencia que es mejor utilizar números pequeños y no grandes como 512 (Sirish et al., 2017)
2) Pasar hacia adelante: Consiste en pasar el lote al MLP y obtener predicciones.
3) Calcular las pérdidas: Las perdidas se calculan con la función de pérdida una vez que ya tenemos las predicciones. Esta función mide que tan buenas son las predicciones realizadas. Esta produce la señal que le dira al modelo que tan cerca está la predicción al vector objetivo. Esta función tomará las predicciones y el vector objetivo y arrojará un número llamado la pérdida. En otras palabras, en este paso calculamos la pérdida del lote que corresponde a una medida de discordancia entre lo predicho y lo observado. Por ejemplo, en problemas de regresión, la función de pérdida más común es el MSE y es la que utilizaremos para este ejercicio.
4) Actualizar los pesos: Actualizar todos los pesos y los sesgos de la red de manera simultánea de una manera tal que reduzca la pérdida del lote actual. Este es un trabajo del optimizador. Este elemento del modelo está a cargo de tomar la señal de la función de pérdida y ajustar o actualizar los pesos para reducir esa pérdida. El mecanismo usual en que está tarea es realizada se llama propagación hacia atrás o backpropagation. Hay muchas elecciones para elegir un optimizador y los investigadores continuan realizando progresos en esta área, pero escencialmente todos los optimizadores son variaciones del algoritmo de gradiente descendiente. Para el presente problema de predicción de precios de diamantes, utilizaremos el optimizador Adam que se ha convertido muy popular, porque ha demostrado buenos resultados en una variedad de problemas.
El bucle de entrenamiento está complete en un epoch que es un ciclo completo sobre el conjunto de entrenamiento. Por ejemplo, supongamos que nuestro dataset tiene un tamaño de 6.400 y el lote tiene un tamaño de 64. El bucle de entrenamiento que describimos correrá 100 iteraciones para completar un epoch. Usualmente, se necesitan muchos epochs para entrenar una red neuronal. En este ejemplo la red neuronal es entrenado en 10 epochs, por lo que el peso inicial será actualizado 100 veces por epoch lo que nos da 1.000 actualizaciones de peso.
Hay que tener cuidado, porque si hay pocos epoch, la red no aprenderá muy bien y por el contrario, si hay muchos epoch, la red ocasionará un overfit a nuestro conjunto de entrenamiento.
Introducción a TensorFlow y Keras
Usualmente, los modelos de redes neuronales necesitan grandes cantidades de datos, superando a otros algoritmos de machine learning. Una gran ventaja es que el proceso de entrenamiento en una red neuronal puede hacer un trabajo paralelo en el hardware como en la unidad de proceso gráfico o graphical processing unit (GPU). La GPU entrena una red neuronal más rápida que una CPU tradicional y por lo mismo algunos frameworks han desarrollado la capacidad de utilizar las GPUs. Algunos de estos frameworks son Theano, Caffe y TensorFlow.Estos frameworks han permitido que los modelos de deep learning puedan ser utilizados por profesionales fuera del cículo académico.
TensorFlow
TensorFlow es una librería de Google especializada en aprendizaje profundo que permite el desarrollo a través de distintas plataformas, como en CPU, GPU y TPU. Hay dos versiones para TensorFlow: una versión para GPU y la otra para CPU.
-
TensorFlow solo para CPU: Si tu equipo no tiene una GPU NVIDIA debieses instalar esta versión. Esta versión es más fácil de instalar, por lo que, aunque tengas una GPU NVIDIA se recomienda instalar esta versión primero.
-
TensorFlow solo para GPU: Como mencionamos, los programas tipicamente corren más rápido en una GPU, por lo que, si cumples los requisitos computacionales y necesitas correr aplicaciones donde el rendimiento sea critico, deberías instalar esta versión, es especial si trabajas con grandes cantidades de datos.
En caso de que no tengas una GPU hay alternativas como FloydHub y PaperSpace que basicamente te arriendan el hardware necesario para que puedas entrenar tus modelos de aprendizaje profundo. De lo contrario, puedes instalar la versión GPU aunque su instalación es dificil. Para revisar los requisitos para la instalación de la versión con GPU la puedes revisar aquí.
Para instalar TensorFlow podemos utilizar el comando pip install --ignore-installed --upgrade tensorflow en un terminal.
TensorFlow incluye muchas capacidades computacionales avanzadas y esta basado en un paradigma llamado dataflow, lo que quiere decir que TensorFlow trabaja primero en construir grafos y luego correr el algoritmo realizado por los grafos dentro de objetos especializados llamados sesiones, que están a cargo de ubicar los algoritmos de los grafos a distintos dispositivos, como la CPU o la GPU. Este paradigma no es tan sencillo de usar y entender, por lo tanto, no utilizaremos TensorFlow directamente, sino como backend y será el que realice todos los calculos detrás del telón. La librería que utilizaremos como interfaz para construir una red neuronal se llama Keras.
Keras
Keras es una librería amigable que sirve como Front-End de TensorFlow u otras librerías de aprendizaje profundo, como Theano. El objetivo principal de Keras es acercar o democratizar la creación de modelos en aprendizaje profundo a las personas que no tienen mucho acercamiento a la informática. Como se explica en su sitio oficial, Keras es una API de alto nivel escrita en Python y capaz de ejecutarse sobre TensorFlow, CNTK y Theano. Fue desarrollado en un enfoque de la experimentación rápida para que desde la idea a la ejecución se pueda hacer en el menor tiempo posible, lo que ayuda a realizar buenas investigaciones.
Para instalar Keras, primero se debe instalar exitosamente TensorFlow. Con correr el siguiente comando en la terminal ya estaríamos listos: pip install keras
Clasificación con redes neuronales
Aunque MLP es un modelo muy comlicado para este problema y el dataset es pequeño, no hay razones para no utilizar MLP con el fin de resolverlo. Recordemos que los stakeholders quieren un modelo lo más preciso posible en realizar las predicciones, entonces veamos a qué tanto accuracy podemos llegar utilizando MLP.
Como los modelos de redes neuronales consisten en una secuencia de capas, Keras tiene una clase llamada Sequential que podemos usar para instanciar un modelo de red neuronal.
from keras.models import Sequential
nn_classifier = Sequential()Con esto creamos una red neuronal vacia llamada nn_reg. Ahora, tenemos que agregarle capas. Utilizaremos lo que se llama una conexión completa o capas densa (dense layers). Estas son capas hechas por neuronas que están conectadas a todas las neuronas de la capa anterior. En otras palabras, cada neurona en una capa densa recibe el output de todas las neuronas de la capa anterior. Como nuestra red neuronal estará hecha de capas densas, importamos la clase Dense.
from keras.layers import DenseComo se menciono anteriormente, la primera capa de un MLP es siempre la capa de entrada y es la que recibe los datos de los atributos y se los pasa a la primera capa oculta. Sin embargo, en Keras no hay necesidad de crear la capa de entrada, porque esta capa son basicamente los atributos. Por lo tanto explicitamente no veras la primera capa en el código, pero conceptualmente está. Dicho esto, la primera capa que añadiremos a nuestra red neuronal vacia es la primera capa oculta. Esta es una capa especial, porque tenemos que especificar con un tuple la forma del input. Desde la documentación de Keras, podemos leer que solo la primera capa en un modelo secuencial necesita recibir la información acerca del tamaño de la matriz.
n_input = X_train.shape[1]
n_units_hidden = 64
nn_classifier.add(Dense(units=n_units_hidden, activation='relu', input_shape=(n_input,)))Veamos que significa cada uno de los parámetros:
- units: Corresponde al número de neuronas en la capa. Estamos utilizando 64.
- activation: Esta corresponde a la función de activación que utilizaremos en cada neurona. Estamos utilizando relu como función de activación.
- input_shape: Este es el número de inputs que la red va a recibir que es equivalente al núimero de atributos en nuestro dataset. No necesitamos especificar el número de muestras que la red va a recibir, dado que puede trabajar con cualquier cantidad de muestra.
Ahora nuestra red neuronal tiene una capa oculta. Como este problema es simple y tenemos un dataset relativamente pequeño, añadiremos cuatro capas ocultas más. Pocas personas considerarían esto un aprendizaje profundo, dado que solo tendremos cinco capas, pero el proceso de construcción y entrenamiento es escencialmente el mismo con 5 o 500 capas. Añadiremos ahora 4 capas ocultas más.
# añadimos una segunda capa oculta
nn_classifier.add(Dense(units=n_units_hidden, activation='relu'))
# añadimos una tercera capa oculta
nn_classifier.add(Dense(units=n_units_hidden, activation='relu'))
# añadimos una cuarta capa oculta
nn_classifier.add(Dense(units=n_units_hidden, activation='relu'))
# añadimos una quinta capa oculta
nn_classifier.add(Dense(units=n_units_hidden, activation='relu'))Note que la cantidad de unidades que estamos utilizando en cada capa es de 64. Es una práctica común utilizar una potencia de dos para la creación de unidades y también notese que la forma de esta red neuronal es la misma para todas las capas.
Ahora bien, la última parte de nuestra red neuronal es la capa de salida. Como estamos trabajando con clasificación binaria, para la capa de salida nos gustaria tener la probabilidad que el cliente entre en default. Es decir, tendremos un output y como este es una probabilidad, tendremos una sigmoide como función de activación.
# añadimos la capa de salida
nn_classifier.add(Dense(units=1, activation='sigmoid'))Ahora que tenemos la arquitectura lista, podemos proceder a realizar el paso de compilación de la red neuronal diciendole a Keras la función de pérdida y optimizar que vamos a utilizar.
nn_classifier.compile(loss='binary_crossentropy', optimizer='adam')La función de pérdida llamada entropía cruzada binaria que viene del área de la teoría de información que mide la distancia entre dos distribuciones de probabilidad. Esta función de pérdida es baja cuando el modelo produce valores cercanos 1 cuando y_true es 1 y cuando los valores son cercanos a cero cuando y_true es 0. Esta función de pérdida es la más popular y estándar para clasificaciones binarias.
Si queremos mirar la arquitectura y el número de parámetros en el modelo, podemos utilizar el método summary.
nn_classifier.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 1280
dense_1 (Dense) (None, 64) 4160
dense_2 (Dense) (None, 64) 4160
dense_3 (Dense) (None, 64) 4160
dense_4 (Dense) (None, 64) 4160
dense_5 (Dense) (None, 1) 65
=================================================================
Total params: 17,985
Trainable params: 17,985
Non-trainable params: 0
_________________________________________________________________
Tenemos un total de 17.985 pesos y sesgos en nuestro modelo. Antes de continuar y realizar el paso de entrenamiento, guardemos el peso inicial de nuestra red neuronal. Veremos porqué en un momento.
nn_classifier.save_weights('class_initial_w.h5')Ahora, para el entrenamiento, probemos con 150 epochs y un lote de tamaño 64. Ahora estamos listos para entrenar el modelo utilizando el método fit.
batch_size = 64
n_epochs = 150
nn_classifier.fit(X_train, y_train, epochs=n_epochs, batch_size=batch_size)Epoch 1/150 391/391 [==============================] - 1s 1ms/step - loss: 0.4696 Epoch 2/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4478 Epoch 3/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4444 Epoch 4/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4421 Epoch 5/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4406 Epoch 6/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4396 Epoch 7/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4384 Epoch 8/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4373 Epoch 9/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4356 Epoch 10/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4338 Epoch 11/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4325 Epoch 12/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4327 Epoch 13/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4307 Epoch 14/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4299 Epoch 15/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4281 Epoch 16/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4265 Epoch 17/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4255 Epoch 18/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4234 Epoch 19/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4222 Epoch 20/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4198 Epoch 21/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4182 Epoch 22/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4158 Epoch 23/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4141 Epoch 24/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4108 Epoch 25/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4094 Epoch 26/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4074 Epoch 27/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4054 Epoch 28/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4009 Epoch 29/150 391/391 [==============================] - 0s 1ms/step - loss: 0.4002 Epoch 30/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3991 Epoch 31/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3958 Epoch 32/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3929 Epoch 33/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3887 Epoch 34/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3881 Epoch 35/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3821 Epoch 36/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3821 Epoch 37/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3763 Epoch 38/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3755 Epoch 39/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3713 Epoch 40/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3706 Epoch 41/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3652 Epoch 42/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3649 Epoch 43/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3612 Epoch 44/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3565 Epoch 45/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3577 Epoch 46/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3551 Epoch 47/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3509 Epoch 48/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3474 Epoch 49/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3468 Epoch 50/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3427 Epoch 51/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3435 Epoch 52/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3382 Epoch 53/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3345 Epoch 54/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3373 Epoch 55/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3345 Epoch 56/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3294 Epoch 57/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3253 Epoch 58/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3281 Epoch 59/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3249 Epoch 60/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3279 Epoch 61/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3161 Epoch 62/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3243 Epoch 63/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3151 Epoch 64/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3147 Epoch 65/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3105 Epoch 66/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3069 Epoch 67/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3054 Epoch 68/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3027 Epoch 69/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3084 Epoch 70/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3006 Epoch 71/150 391/391 [==============================] - 0s 1ms/step - loss: 0.3012 Epoch 72/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2980 Epoch 73/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2989 Epoch 74/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2942 Epoch 75/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2917 Epoch 76/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2935 Epoch 77/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2913 Epoch 78/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2922 Epoch 79/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2830 Epoch 80/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2880 Epoch 81/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2878 Epoch 82/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2867 Epoch 83/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2780 Epoch 84/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2834 Epoch 85/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2748 Epoch 86/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2733 Epoch 87/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2852 Epoch 88/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2723 Epoch 89/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2732 Epoch 90/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2760 Epoch 91/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2682 Epoch 92/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2686 Epoch 93/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2702 Epoch 94/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2612 Epoch 95/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2666 Epoch 96/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2662 Epoch 97/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2718 Epoch 98/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2570 Epoch 99/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2536 Epoch 100/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2566 Epoch 101/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2584 Epoch 102/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2624 Epoch 103/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2522 Epoch 104/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2530 Epoch 105/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2478 Epoch 106/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2605 Epoch 107/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2514 Epoch 108/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2570 Epoch 109/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2451 Epoch 110/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2437 Epoch 111/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2521 Epoch 112/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2392 Epoch 113/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2424 Epoch 114/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2480 Epoch 115/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2460 Epoch 116/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2403 Epoch 117/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2338 Epoch 118/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2366 Epoch 119/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2404 Epoch 120/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2364 Epoch 121/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2394 Epoch 122/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2369 Epoch 123/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2368 Epoch 124/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2297 Epoch 125/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2250 Epoch 126/150 391/391 [==============================] - 1s 1ms/step - loss: 0.2268 Epoch 127/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2308 Epoch 128/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2454 Epoch 129/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2227 Epoch 130/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2205 Epoch 131/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2355 Epoch 132/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2303 Epoch 133/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2270 Epoch 134/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2193 Epoch 135/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2174 Epoch 136/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2220 Epoch 137/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2167 Epoch 138/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2193 Epoch 139/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2288 Epoch 140/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2258 Epoch 141/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2268 Epoch 142/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2119 Epoch 143/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2048 Epoch 144/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2103 Epoch 145/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2144 Epoch 146/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2203 Epoch 147/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2085 Epoch 148/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2153 Epoch 149/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2154 Epoch 150/150 391/391 [==============================] - 0s 1ms/step - loss: 0.2147
keras.callbacks.History at 0x1dccdc57d60>
Evaluando las predicciones
Ahora que estamos listo con el proceso de entrenamiento, es momento de ver que tan bien le fue a nuestras predicciones. Estimaremos la probabilidad estimada tanto del conjunto de test, como del conjunto de entrenamiento. Utilizaremos el umbral de 0.5 para hacer predicciones.
# Obtenemos las probabilidades
y_pred_train_prob = nn_classifier.predict(X_train)
y_pred_test_prob = nn_classifier.predict(X_test)# Clasificamos las predicciones
y_pred_train = (y_pred_train_prob > 0.5).astype(int)
y_pred_test = (y_pred_test_prob > 0.5).astype(int)Ahora, veremos la puntuación accuracy para ambos conjuntos
train_acc = accuracy_score(y_true=y_train, y_pred=y_pred_train)
test_acc = accuracy_score(y_true=y_test, y_pred=y_pred_test)
print('Train Accuracy: {:0.3f} \nTest Accuracy: {:0.3f}'.format(train_acc, test_acc))Train Accuracy: 0.911 Test Accuracy: 0.759
En este caso, no estamos obteniendo buenos resultados. Esto demuestra que no hay garantías que los modelos más complicados entregan un mejor resultado que un modelo simple. Puede ser que también no estemos utilizando la red neuronal correcta. Bienvenidos al oscuro arte del entrenamiento de redes neuronales.
El oscuro arte del entrenamiento de redes neuronales
De los resultados que obtuvimos, podemos notar un claro síntoma de overfitting, dado que el accuracy en el conjunto de entrenamiento es muy alto (91%), mientras que en el conjunto de test es menor que incluso una elección al azar. Las principales causas de este resultado pueden estar dadas por las siguientes razones:
- El modelo tiene muchos parámetros.
- El modelo ha sido entrenado demasiado.
Como estamos sobreajustados, tenemos que intentar resolver esto con alguna técnica de regularización. Lo más simple es correr el modelo con menor cantidad de epochs. Iniciemos entonces con el peso y el sesgo de los valores iniciales.
nn_classifier.load_weights('class_initial_w.h5')Ahora que los pasos han sido receteados, entrenemos nuestro modelo nuevamente, pero esta vez con 50 epochs.
batch_size = 84
n_epochs = 50
nn_classifier.compile(loss='binary_crossentropy', optimizer='adam')
nn_classifier.fit(X_train, y_train, epochs=n_epochs, batch_size=batch_size)Epoch 1/50 298/298 [==============================] - 1s 1ms/step - loss: 0.4722 Epoch 2/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4468 Epoch 3/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4440 Epoch 4/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4413 Epoch 5/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4400 Epoch 6/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4390 Epoch 7/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4378 Epoch 8/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4359 Epoch 9/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4359 Epoch 10/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4339 Epoch 11/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4332 Epoch 12/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4317 Epoch 13/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4305 Epoch 14/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4288 Epoch 15/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4277 Epoch 16/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4260 Epoch 17/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4246 Epoch 18/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4231 Epoch 19/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4209 Epoch 20/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4196 Epoch 21/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4181 Epoch 22/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4151 Epoch 23/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4129 Epoch 24/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4130 Epoch 25/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4104 Epoch 26/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4067 Epoch 27/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4050 Epoch 28/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4024 Epoch 29/50 298/298 [==============================] - 0s 1ms/step - loss: 0.4018 Epoch 30/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3991 Epoch 31/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3949 Epoch 32/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3943 Epoch 33/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3903 Epoch 34/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3894 Epoch 35/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3871 Epoch 36/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3863 Epoch 37/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3826 Epoch 38/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3804 Epoch 39/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3781 Epoch 40/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3755 Epoch 41/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3725 Epoch 42/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3705 Epoch 43/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3661 Epoch 44/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3651 Epoch 45/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3630 Epoch 46/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3586 Epoch 47/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3579 Epoch 48/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3567 Epoch 49/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3512 Epoch 50/50 298/298 [==============================] - 0s 1ms/step - loss: 0.3486
keras.callbacks.History at 0x1dccdf758e0
Ahora, nuevamente, calculamos los resultados.
# Obtenemos las probabilidades
y_pred_train_prob = nn_classifier.predict(X_train)
y_pred_test_prob = nn_classifier.predict(X_test)
# Clasificamos las predicciones
y_pred_train = (y_pred_train_prob > 0.5).astype(int)
y_pred_test = (y_pred_test_prob > 0.5).astype(int)
# Calculamos el accuracy
train_acc = accuracy_score(y_true=y_train, y_pred=y_pred_train)
test_acc = accuracy_score(y_true=y_test, y_pred=y_pred_test)
print('Train Accuracy: {:0.3f} \nTest Accuracy: {:0.3f}'.format(train_acc, test_acc))Train Accuracy: 0.847 Test Accuracy: 0.792
Se ve que el problema, aunque en menor medida, se sigue presentando. Con el oscuro arte de las redes neuronales me refiero al arte de adivinar la configuración correcta.
Muchas decisiones en tan poco tiempo.
Este es el principal problema de utilizar redes neuronales en el análisis predictivo. Hay muchas decisiones que tomar donde es muy dificil adivinar una buena configuración cuando resolvemos un problema. Uno tiene que tomar decisiones en la arquitectura del modelo, como las siguientes:
1) Número de capas.
2) Número de unidades en cada capa.
3) La función de activación en cada capa.
4) El método utilizado para obtener el peso inicial.
Para el paso de compilación debemos tomar las siguientes decisiones:
1) La función de pérdida.
2) El optimizador.
3) Los parámetros del optimizador.
Para el paso de compilación debemos tomar las siguientes decisiones:
1) El tamaño del lote.
2) El número de epochs.
Finalmente, como las redes neuronales son muy susceptibles a sobreajustarse, casi siempre vamos a tener que realizar una regularización. Por lo tanto, tenemos que decidir sobre:
1) El tipo de regularización.
2) Los parámetros de regularización.
Para dimensionar más o menos lo complicado que es tomar en total 11 decisiones, imahinemos que tenemos tres opciones para cada decisión. El número total de combinaciones es $3^{11}$ lo que equivale a 117.147 posibles configuraciones para nuestro modelo. Digamos que solo considera el 10% de todas estas combinaciones, incluso si la red se demora un segundo en entrenar y evaluar (una asunción muy irrealista) sería muy impráctico probar muchas configuraciones uno a uno para encontrar la mejor connfiguración y puede incluso que la mejor condiguración, si es que la encontramos, no de buenos resultados. Las buenas noticias es que hay muchos tips prácticos, teóricos y resultados empiricos que disminuirían la dimensión de búsqueda y permitirá que eligas buenos valores de configuración para tu red neuronal. La mala noticia es que para entender algunos de estos resultados y como utilizarlos de manera efectiva requiere conocimientos técnicos avanzados e incluso de haber adquirido esos conocimientos aún existirá mucha prueba y error en el proceso.
Quinta parte: Evaluación de modelos
En cada proyecto de análisis predictivo es muy importante considerar que métricas utilizar para evaluar los modelos y como implementar la evaluación general de la estrategia y como conectarla con el problema de negocios que estamos intentando resolver.
Hasta ahora hemos utilizado la exactitud o accuracy como una métrica por defecto para evaluar modelos de clasificación y lo hemos hecho de esa manera, porque es la métrica más intuitiva: es simplemente la proporción de casos correctamente predichos por el clasificador, por lo que un accuracy del 75% significa que, en promedio, deberiamos esperar que el clasificador realice una predicción correcta el 75% de las veces. Aunque a veces es útil, esta métrica es muy limitada. Al evaluar un modelo de clasificación, incluso un modelo binario, es complicado.
Para ver otras métricas además de la que ya vimos, crearemos un nuevo modelo (random forest) para luego evaluarlo.
rf = RandomForestClassifier(n_estimators = 25,
max_features = 6,
max_depth = 4,
random_state = 61)
rf.fit(X_train, y_train)RandomForestClassifier(max_depth=4, max_features=6, n_estimators=25, random_state=61)
Matriz de Confusión
Una matriz de confusión no es más que una tabla con cuatro diferentes posibles casos que se nos presentan en un problema de clasificación binario. En el caso del presente problema de defaults en las tárjetas de crédito, hemos definido el default como un evento o clase positiva. Considerando este escenario, tenemos cuatro posibles casos:
1) Verdadero positivo: El modelo predice una clase positiva y la observación efectivamente pertenece a una clase positiva. Es cuando predecimos que el cliente cae en default y la clasificación real es default.
2) Verdadero negativo: El modelo predice una clase negativa y la observación efectivamente pertenece a una clase negativa. Es cuando predecimos que el cliente pagará el siguiente mes (no está en default) y en la realidad lo hace.
3) Falso positivo: El modelo predice una clase positiva, pero la observación pertenece a una clase negativa. Es cuando predecimos que el cliente entrará en default, pero en realidad este pagará el siguiente mes.
4) Falso negativo: El modelo predice una clase negativa, pero la observación pertenece a una clase positiva. Es cuando predecimos que el cliente pagará el mes siguiente, pero en realidad el cliente está en default.
Ahora que conocemos la terminología, podemos generar una matriz de confusión, pero para hacerla más entendible, crearemos una pequeña función para dicho fin.
from sklearn.metrics import confusion_matrix
def CM(y_true, y_pred):
M = confusion_matrix(y_true, y_pred)
out = pd.DataFrame(M, index=['Obs Paid', 'Obs Default'],
columns = ['Pred Paid', 'Pred Default'])
return outRecordar que un modelo de bosque aleatorio nos entrega la probabilidad estimada de que una observación pertenezca a una clase. Necesitamos usar un threshold o umbral para decidir en qué punto la observación será clasificada como positiva (default) o negativa (no hay default). El umbral que usaremos es 0.5 y con eso podemos generar las predicciones.
threshold = 0.5
y_pred_prob = rf.predict_proba(X_test)[:,1]
y_pred = (y_pred_prob > threshold).astype(int)Ahora, podemos ver la matriz de confusión para este modelo.
CM(y_test, y_pred)| Pred Paid | Pred Default | |
|---|---|---|
| Obs Paid | 3759 | 151 |
| Obs Default | 828 | 262 |
De las 5.000 observaciones del conjunto de test, podemos observar que:
- 3.759 observaciones son verdaderos negativos.
- 262 observaciones son verdaderos positivos.
Estas son las que pudimos clasificar correctamente. Por otro lado tenemos las que clasificamos mal:
- 151 observaciones son falsos positivos.
- 828 observaciones son falsos negativos.
Hay algunas métricas que podemos calcular para que estos números de la matriz de confusión hagan más sentido. A continuación tenemos las métricas más importantes que podemos extraer desde la matriz de confusión.
1) Exactitud o Accuracy: Proporción entre casos correctos y el total de observaciones, es decir, $\frac{TP + TN}{N}$
2) Precisión: Proporción entre verdaderos positivos y la suma de verdaderos positivos con falsos positivos, es decir, $\frac{TP}{TP + FP}$. En nuestro problema, esta es la proporción de casos cuando el modelo es correcto cuando clasifica a los clientes en default.
3) Recall, sensibilidad o ratio verdadaro positivo: Proporción de observaciones que fueron predecidas correctamente como positivas, es decir, $\frac{TP}{TP + FN}$. En nuestro problema, esta es la proporción de casos default que el modelo puede identificar correctamente.
4) Ratio falso positivo o ratio de falsa alarma: Proporción de observaciones que fueron predecidas como falso positivas, es decir, $\frac{TP}{TP + TN}$. En nuestro problema, esta es la proporción de casos donde los clientes pagan sus deudas y fieron acusados falsamente como si estuviesen en default (falsa alarma).
Hay muchas otras porporciones que se pueden calcular utilizando la matriz de confusión. Sin embargo, para cualquier clasificación binaria, estas cuatro métricas nos ayudarán a entender qué tipo de errores está cometiendo el modelo.
Ahora, calculemos el nivel de precisión y recall de nuestro modelo.
from sklearn.metrics import precision_score, recall_score
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print('Precision: {:0.1f}%, Recall: {:.1f}%'.format(100 * precision, 100 * recall))Precision: 63.4%, Recall: 24.0%
Cuando el modelo realiza una predicción positiva (default), esta es correcta el 63% del tiempo (precisión), esto no es malo. Sin embargo, el modelo es capaz de identificar solo el 24% de los default reales. Estas métricas nos dan una imagen muy util de lo que está pasando con nuestro modelo.
Métodos de visualización para evaluar modelos de clasificación
Es siempre una buena idea complementar el análisis numérico de las métricas con visualizaciones, dado que nos pueden ayudar a entender las predicciones y los errores que el modelo tiene. Podemos visualizar las probabilidades y relaciones entre las diferentes métricas que vienen desde la matriz de confusión.
Siempre es buena idea mirar como se distribuyen las probabilidades que fueron predichas por el modelo, en este caso, por Random Forest.
plt.hist(y_pred_prob, bins=25, ec='k')
plt.show()
Vemos que en muchos casos la probabilidad es cercana a cero, lo que significa que el modelo está confiando que esas observaciones no forman parte de la categoría default. Por otro lado, no vemos probabilidades cercanas a 1. Esto significa que cuando estamos clasificando a un cliente como default, el modelo no está seguro.
Otro gráfico que podemos encontrar muy útil es la distribución de probabilidades separada por clases positivas y negativas.
fig, ax = plt.subplots(figsize=(8, 5))
sns.kdeplot(y_pred_prob[y_test==1], shade=True,
color='red', label='Defaults', ax=ax)
sns.kdeplot(y_pred_prob[y_test==0], shade=True,
color='green', label='Paid', ax=ax)
ax.set_title('Distribution of predicted probabilities',
fontsize=16)
ax.legend()
plt.grid()
Como podemos ver, cuando el modelo predice una menor probabilidad, es mucho más seguro que el cliente esté sin default y cuando el modelo predice una probabilidad superior a 0.5, es más seguro que el cliente entre en default. Hay también una gran superposición en las distribuciones y es en donde provienen los errores. Lo ideal sería ver estas dos distribuciones con la menor superposición posible.
Característica operativa del receptor (ROC) y curvas de precisión y recall
Como mencionamos anteriormente, para obtener las predicciones finales de clasificación desde las probabilidades que nos arrojó el modelo, necesitamos un umbral de tolerancia (threshold). Si cambiamos este umbral, nos arrojará diferentes clasificaciones y por tanto una matriz de confusión distinta. Veamos que ocurre si cambiamos el umbral al 0.4.
Antes teniamos esto
CM(y_test, y_pred)| Pred Paid | Pred Default | |
|---|---|---|
| Obs Paid | 3759 | 151 |
| Obs Default | 828 | 262 |
Y con un umbral al 0.4 tenemos esto:
threshold = 0.4
y_pred_prob = rf.predict_proba(X_test)[:,1]
y_pred = (y_pred_prob > threshold).astype(int)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print('Precision: {:0.1f}%, Recall: {:.1f}%'.format(100 * precision, 100 * recall))
CM(y_test, y_pred)Precision: 59.1%, Recall: 38.0%
| Pred Paid | Pred Default | |
|---|---|---|
| Obs Paid | 3623 | 287 |
| Obs Default | 676 | 414 |
Con un umbral menor ahora tenemos más verdaderos positivos, pero también tenemos más falsos positivos. Por lo que el precio de tener más verdaderos positivos es tener más falsos positivos. Lo que está ocurriendo es que al bajar el umbral, estamos bajando la tolerancia de clasificar a un cliente como default, es decir, estamos acusando a más personas de estar en default. Algunos de ellos estará efectivamente en default, pero otros pagarán, lo que nos da un incremento en TP y en FP.
Las métricas de clasificación también cambian con una nueva matriz de confusión.
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
accuracy = accuracy_score(y_test, y_pred)
print('Precision: {:0.1f}%, Recall: {:.1f}%, Accuracy: {:.1f}%'\
.format(100 * precision, 100 * recall, 100 * accuracy))Precision: 59.1%, Recall: 38.0%, Accuracy: 80.7%
El modelo básicamente tiene la misma exactitud, observamos un mejor recall, pero la precisión disminuye.
En resumen, dadas las probabilidades predichas por el modelo, la elección del umbral determinará las predicciones. Estas predicciones junto con los valores observados determinarán la matriz de confusión y el rendimiento de las métricas que derivan de esta. Por lo tanto, hay una dependencia entre el umbral de clasificación y las métricas, como la precisión y el recall. Podemos ver esta relación utilizando la función precision_recall_curve
from sklearn.metrics import precision_recall_curve
precs, recs, ths = precision_recall_curve(y_test, y_pred_prob)fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(ths, precs[1:], label='Precision')
ax.plot(ths, recs[1:], label='Recall')
ax.set_title('Precision and recall for different thresholds',
fontsize=16)
ax.set_xlabel('Threshold', fontsize=14)
ax.set_ylabel('Precision, Recall', fontsize=14)
ax.set_xlim(0.1, 0.7)
ax.legend()
ax.grid()
Como podemos ver, hay una relación inversa entre precisión y recall. Mayor umbral implica mayor precisión, pero menor recall. Podemos observar esto directamente graficando la curva de precision-recall.
fig, ax = plt.subplots(figsize=(8,5))
ax.plot(precs, recs)
ax.set_title('Precision-recall curve',
fontsize=16)
ax.set_xlabel('Precision', fontsize=14)
ax.set_ylabel('Recall', fontsize=14)
ax.set_xlim(0.3, 0.7)
ax.grid()
La relación que observamos en el gráfico anterior puede ser explicado de dos formas:
- Si queremos que nuestras predicciones sean más confiables (mejor precisión) entonces utiliza un umbral alto. Esto implicará que el clasificador será más selectivo para asignar una observación a la clase positiva, lo que a su vez incrementará los falsos negativos, empeorando el recall.
- Si lo que queremos es detectar más clases positivas, entonces utilizamos un umbral bajo. Esto implica que el clasificador esté más dispuesto a clasificar las observaciones como positivas. En el caso de nuestro ejemplo, vimos que habia una probabilidad baja de acusar a un cliente como default y un umbral bajo aumentará esa probabilidad, lo que hará aumentar el caso de observaciones clasificadas como positivas, pero también hará aumentar el caso de falsos positivos, disminuyendo la precisión.
En resumen, hay una relación inversa entre la precisión y el recall.
Finalmente, a veces es util visualizar la relación entre recall (ratio de verdaderos positivos) y el ratio de los falsos positivos. Esto es otra perspectiva de la misma realidad: la relación inversa entre FP y FN. En otras palabras, dadas algunas probabilidades predichas por el modelo, para disminuir un tipo de error en las predicciones, necesariamente otro tipo de error será mayor.
Cuando graficamos el ratio de falsos positivos contra el recall obtenemos un gráfico llamado curva ROC (receiver operating characteristic)
from sklearn.metrics import roc_curve
fpr, tpr, ths = roc_curve(y_test, y_pred_prob)fig, ax = plt.subplots(figsize=(8,5))
ax.plot(fpr, tpr)
ax.set_title('ROC curve', fontsize=16)
ax.set_xlabel('False positive rate',
fontsize=14)
ax.set_xlabel('Recall, True positive rate',
fontsize=14)
ax.grid()
Esta curva comienza en el punto (0, 0). Esto es cuando todas las muestras son asignadas a la clase negativa. Como no hay positivos, no estamos clasificando a ningún positivo (recall = 0) y no habrían falsas alarmas (ratio falso positivo = 0). En el otro extremo, si todas las muestras son clasificadas como positivas (recall = 1), pero todos los errores que cometamos serán falsos positivos (ratio falso positivo = 1).
Entonces, ¿qué curva utilizamos? ¿La curva de precision-recall o la curva ROC? Eso depende en el problema que estamos trabajando y la forma en que lo estamos evaluando y analizando.
Definiendo una métrica personalizada
En problemas del mundo real como el que estamos trabajando, los dos tipos de errores que el clasificador puede hacer no son igual de importantes y casi siempre tienen diferentes consecuencias y costos para el problema del negocio que estamos enfrentando. Por lo tanto debemos preguntarnos ¿qué es peor?, ¿Un falso positivo, donde se cree que el consumidor no va a pagar cuando en realidad paga, o un falso negativo, donde se cree que el consumidor pagará, pero en realidad entra a default?
Cuando nos hacemos estas preguntas ya estamos fuera del campo de Machine Learning y dentro del contexto del negocio. Nunca olvidemos que la efectividad del análisis predictivo es aquel que resuelve el problema del negocio y no aquel que tiene el modelo más cool.
Hay veces que podemos asignar un costo a cada uno de los errores que hace el modelo. Si ese fuese el caso, podemos asignarle un costo a cada clasificador dependiendo de los valores de FP y FN que se generan. Desarrollemos una función que nos entrega valores predichos y observados y calcula un costo normalizado utilizando la matriz de confusión.
def class_cost(y_true, y_pred, cost_fn=1, cost_fp=1):
M = confusion_matrix(y_true, y_pred)
N = len(y_true)
FN = M[1, 0]
FP = M[0, 1]
return (cost_fn * FN + cost_fp * FP) / NLo que hacemos en la función es simplmemente multiplicar los respectivos costos de falso positivo y falso negativo por un número fijo (por defecto 1 en ambos errores). También notar que estamos normalizando el resultado por el número de observaciones que estamos utilizando para evaluar el modelo.
Por ejemplo, para la última predicción que realizamos, con un umbral de 0.4, obtenemos el siguiente costo.
class_cost(y_test, y_pred)0.1926
Utilizando esta función y diferentes niveles de umbral, podemos calcular los diferentes costos asociados para cada umbral. En este ejemplo, estamos asumiento que un falso negativo cuesta tres veces más que un falso positivo.
thresholds = np.arange(0.05, 0.95, 0.01)
costs = []
for th in thresholds:
y_pred = (y_pred_prob > th).astype(int)
costs.append(class_cost(y_test, y_pred, cost_fn=3, cost_fp=1))
costs = np.array(costs)Una vez calculado los costos por cada umbral, veamos como se ve esto gráficamente.
fig, ax = plt.subplots(figsize=(8,5))
ax.plot(thresholds, costs)
ax.set_title('Cost vs threshold', fontsize=16)
ax.set_xlabel('Threshold', fontsize=14)
ax.set_ylabel('Cost', fontsize=14)
ax.grid()
Si este fuese el escenario, donde el falso positivo cuesta 3 veces más que el falso negativo, entonces el umbral que minimiza el costo es 0.24.
min_cost_th = thresholds[costs.argmin()]Finalmente, la matriz de confusión, la presición y el recall correspondiente a este umbral es el siguiente:
y_pred = (y_pred_prob > min_cost_th).astype(int)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print('Precision: {:0.1f}%, Recall: {:.1f}%'.format(
100 * precision, 100 * recall))
CM(y_test, y_pred)| Pred Paid | Pred Default | |
|---|---|---|
| Obs Paid | 2994 | 916 |
| Obs Default | 388 | 702 |
Este tipo de evaluación tendría más sentido para las partes involucradas en el negocio.
Optimizando los hiperparámetros
En muchos modelos, incluidos los que hemos usado hasta ahora, hay algunos parámetros o inputs que no son aprendidos de los datos. Necesitamos elegir sus valores que son llamados hiperparámetros. Hasta ahora, hemos utilizado los hiperparámetros que vienen por defecto en los modelos, que son en general buenos valores basados en las buenas prácticas del análisis predictivo. Sin embargo, si queremos que nuestro modelo tenga un mejor desempeño, necesitamos un ajuste de hiperparámetros que es la actividad de encontrar buenos valores de hiperparámetros para nuestro modelo.
Por ahora, calculemos el puntaje de las métricas utilizando una validación cruzada k-fold. Utilizaremos para este ejemplo el área bajo la curva, más bien conocido como AUC (area under curve).
La idea detrás de la validación cruzada k-fold es simple: dividimos el dataset en K partes iguales (pliegues o folds). En la primera iteración, utilizamos la primera parte para testear y el resto para entrenar y obtenemos las métricas. Luego, utilizamos la segunda parte de K como test y el resto para entrenar, obteniendo nuevas métricas, y así sucesivamente. De esta manera, obtendremos K estimaciones de las métricas. En la siguiente imagen se puede ver que utilizamos K=4, es decir, obtendremos una métrica con cuatro valores distintos.
Los valores más comúnes para K son 5 o 10. Implementemos 10 validaciones cruzadas K-fold para obtener un mejor AUC para nuestro modelo de random forest. La función cross_validate usa una métrica de puntuación para calcular la validación cruzada K-fold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
ref_rf = RandomForestClassifier(n_estimators=25,
max_features=6,
max_depth=4,
random_state=61)
ref_rf_scores = cross_val_score(ref_rf, X, y, scoring='roc_auc', cv=10)
ref_rf_scores.mean()0.7635287932449385
Esto no dió un AUC promedio de 0.7635. Este es el resultado de utilizar algunos hiperparámetros de manera arbitraria. Los hiperparámetros que utilizamos para este modelo son los siguientes:
1) n_estimators: El número de árboles en el bosque.
2) max_depths: La máxima profundidad que los árboles pueden tomar.
3) max_features: El número máximo de atributos a considerar cuando buscamos la mejor separación.
Para el algoritmo de random forest hay más hiperparámetros que utilizar, pero para este ejercicio, utilizaremos solo esos tres.
El método que utilizaremos se llama búsqueda exhaustiva de grillas. Esta prueba todas las combinaciones posibles de hiperparámetros que nosotros queremos probar, por ejemplo, si probamos dos valores de n_estimators y tres valores de max_depths, tendremos 6 (2x3) diferentes pares de hiperparámetros que podremos probar para elegir aquella combinación que sea la mejor opción para optimizar una métrica.
La búsqueda exhaustiva de grillas puede ser muy costoso computacionalmente, porque si queremos probar muchos hiperparámetros, con muchos valores cada uno, la combinación a probar puede llegar a ser muy alta y el modelo probará cada una de estas combinaciones. Además, como siempre es recomendable utilizar validación cruzada k-fold, este método utilizará K modelos para cada pliegue, lo que podría generar muchísima demora.
Utilizaremos GridSearchCV ára definir una grilla de parámetros que es un diccionario que contiene una lista de los posibles valores que nos gustaría probar para cada hiperparámetro.
from sklearn.model_selection import GridSearchCV
param_grid = {'n_estimators': [25, 100, 200, 400],
'max_features': [4, 10, 19],
'max_depth': [4, 8, 16, 20]}También podriamos crear una guilla de parámetros que sea una lista de diccionarios para definir mejor que combinaciones de parámetros quisieramos probar. Por ejemplo, si quisieramos probar sólo árboles profundos, pero pocos o muchos árboles pequeños, pero muchos, podríamos definir la grilla de parámetros de la siguiente manera:
param_grid_ = [{'n_estimators': [25, 100], 'max_depth': [16, 20], 'max_features': [4, 10, 19]},
{'n_estimators': [200, 400], 'max_depth': [4, 8], 'max_features': [4, 10, 19]}, ]En este ejemplo tenemos cuatro valores para n_estimators, tres valores para max_features y cuatro valores para max_depths, haciendo un total de 48 combinaciones de diferentes hiperparámetros (4x3x4). Notar que ambos param_grid son lo mismo, solo que están declarados de distintas maneras.
Una vez que hayamos definido nuestra grilla de parámetros, creamos una instancia de la clase GridSearchCV.
rf = RandomForestClassifier(random_state=17)
grid_search = GridSearchCV(estimator=rf,
param_grid=param_grid,
scoring='roc_auc',
cv=5,
verbose=1,
n_jobs=-1)Lo que hemos hecho fue pasarle a GridSearchCV un estimador base (RandomForestClassifier), la grilla de parámetros anteriormente definida, la métrica que usaremos para medir el rendimiento (AUC) y el número de pligues en la validación cruzada k-fold, cinco en este caso. Una vez que fue creado, podemos utilizar el método fit para comenzar el procedimiento.
grid_search.fit(X_train, y_train)Fitting 5 folds for each of 48 candidates, totalling 240 fits>
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 6 concurrent workers.
[Parallel(n_jobs=-1)]: Done 38 tasks | elapsed: 34.0s
[Parallel(n_jobs=-1)]: Done 188 tasks | elapsed: 8.3min
[Parallel(n_jobs=-1)]: Done 240 out of 240 | elapsed: 13.5min finished
GridSearchCV(cv=5, estimator=RandomForestClassifier(random_state=17), n_jobs=-1,
param_grid={'max_depth': [4, 8, 16, 20],
'max_features': [4, 10, 19],
'n_estimators': [25, 100, 200, 400]},
scoring='roc_auc', verbose=1)
Una vez que el proceso este completo, podemos acceder al diccionario grid_search.cvresults que contiene los valores estadísticos acerca de los resultados del ajuste del modelo y de la validación cruzada. Nosotros estamos interesados en el mean_test_score. Para ver los resultados asociados a la combinación de todos los parámetros, creemos la siguiente Serie con Pandas.
gs_results = pd.Series(grid_search.cv_results_['mean_test_score'],
index=grid_search.cv_results_['params'])
gs_results.sort_values(ascending=False){'max_depth': 8, 'max_features': 10, 'n_estimators': 200} 0.773830
{'max_depth': 8, 'max_features': 10, 'n_estimators': 400} 0.773820
{'max_depth': 8, 'max_features': 10, 'n_estimators': 100} 0.773360
{'max_depth': 8, 'max_features': 19, 'n_estimators': 400} 0.772927
{'max_depth': 8, 'max_features': 19, 'n_estimators': 200} 0.772813
{'max_depth': 8, 'max_features': 4, 'n_estimators': 400} 0.772255
{'max_depth': 8, 'max_features': 19, 'n_estimators': 100} 0.772137
{'max_depth': 8, 'max_features': 4, 'n_estimators': 200} 0.771630
{'max_depth': 8, 'max_features': 4, 'n_estimators': 100} 0.771423
{'max_depth': 8, 'max_features': 10, 'n_estimators': 25} 0.770863
{'max_depth': 8, 'max_features': 19, 'n_estimators': 25} 0.770834
{'max_depth': 16, 'max_features': 4, 'n_estimators': 400} 0.770046
{'max_depth': 16, 'max_features': 4, 'n_estimators': 200} 0.768988
{'max_depth': 8, 'max_features': 4, 'n_estimators': 25} 0.768737
{'max_depth': 16, 'max_features': 10, 'n_estimators': 400} 0.768248
{'max_depth': 16, 'max_features': 10, 'n_estimators': 200} 0.767655
{'max_depth': 20, 'max_features': 4, 'n_estimators': 400} 0.767565
{'max_depth': 16, 'max_features': 4, 'n_estimators': 100} 0.767457
{'max_depth': 16, 'max_features': 19, 'n_estimators': 400} 0.766977
{'max_depth': 4, 'max_features': 10, 'n_estimators': 400} 0.766790
{'max_depth': 4, 'max_features': 10, 'n_estimators': 200} 0.766684
{'max_depth': 20, 'max_features': 4, 'n_estimators': 200} 0.766618
{'max_depth': 16, 'max_features': 19, 'n_estimators': 200} 0.766571
{'max_depth': 4, 'max_features': 10, 'n_estimators': 100} 0.766496
{'max_depth': 4, 'max_features': 19, 'n_estimators': 400} 0.766000
{'max_depth': 4, 'max_features': 10, 'n_estimators': 25} 0.765978
{'max_depth': 4, 'max_features': 19, 'n_estimators': 200} 0.765900
{'max_depth': 4, 'max_features': 19, 'n_estimators': 100} 0.765294
{'max_depth': 16, 'max_features': 10, 'n_estimators': 100} 0.764977
{'max_depth': 20, 'max_features': 10, 'n_estimators': 400} 0.764637
{'max_depth': 20, 'max_features': 4, 'n_estimators': 100} 0.764416
{'max_depth': 4, 'max_features': 19, 'n_estimators': 25} 0.764406
{'max_depth': 16, 'max_features': 19, 'n_estimators': 100} 0.764138
{'max_depth': 4, 'max_features': 4, 'n_estimators': 200} 0.763807
{'max_depth': 4, 'max_features': 4, 'n_estimators': 400} 0.763663
{'max_depth': 4, 'max_features': 4, 'n_estimators': 100} 0.763459
{'max_depth': 20, 'max_features': 10, 'n_estimators': 200} 0.763321
{'max_depth': 20, 'max_features': 19, 'n_estimators': 400} 0.762414
{'max_depth': 20, 'max_features': 19, 'n_estimators': 200} 0.761797
{'max_depth': 4, 'max_features': 4, 'n_estimators': 25} 0.761478
{'max_depth': 20, 'max_features': 10, 'n_estimators': 100} 0.760430
{'max_depth': 20, 'max_features': 19, 'n_estimators': 100} 0.758521
{'max_depth': 16, 'max_features': 4, 'n_estimators': 25} 0.758265
{'max_depth': 16, 'max_features': 19, 'n_estimators': 25} 0.757708
{'max_depth': 16, 'max_features': 10, 'n_estimators': 25} 0.755681
{'max_depth': 20, 'max_features': 4, 'n_estimators': 25} 0.749161
{'max_depth': 20, 'max_features': 19, 'n_estimators': 25} 0.748148
{'max_depth': 20, 'max_features': 10, 'n_estimators': 25} 0.746734
dtype: float64
Del resultado podemos ver que el mejor conjunto de parámetros es max_depth = 8, max_features = 10 y n_estimators = 200. Sin embargo, notar que la siguiente combinación de parámetros nos da un valor muy cercano al mejor valor. Notar también todo el Top 10 de parámetros tiene una profundidad máxima de 8. Esto es una señal que nos dice que el ocho es un buen valor para este parámetro.
Cuando realizamos un ajuste de parámetros es importante dejar afuera al conjunto de test para confirmar que las estimaciones de las métricas que obtendremos al usar el modelo sean de datos que el modelo nunca ha visto antes.
Como podemos ver en los resultados, los parámetros que seleccionamos arbitrariamente (max_depth:4, max_features:6, n_estimators:25) no entregan un resultado tan bueno como el top 10 de las mejores combinaciones de parámetros. Para comparar y analizar cuánto hemos ganado al ajustar los hiperparámetros, comparemos la curva precision-call para ambos modelos, es decir, el modelo utilizando los parámetros arbitrarios y el modelo con ajuste de hiperparámetros.
# Entrenamos el modelo inicial
ref_rf.fit(X_train, y_train)
# Obtenemos las probabilidades
y_prob_tuned = grid_search.predict_proba(X_test)[:,1]
y_prob_not_tuned = ref_rf.predict_proba(X_test)[:,1]
# Valores resultantes para graficar las curvas.
prec_tuned, recall_tuned, _ = precision_recall_curve(y_test, y_prob_tuned)
prec_not_tuned, recall_not_tuned, _ = precision_recall_curve(y_test, y_prob_not_tuned)Ahora que tenemos ambas curvas para el modelo con ajuste y sin ajuste, podemos graficar ambos gráficos.
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(prec_tuned, recall_tuned, label='Tuned Model')
ax.plot(prec_not_tuned, recall_not_tuned, label='Not Tuned Model')
ax.set_title('Precision-recall curves', fontsize=16)
ax.set_xlabel('Precision', fontsize=14)
ax.set_ylabel('Recall', fontsize=14)
ax.set_xlim(0.3, 0.7)
ax.set_ylim(0.1, 0.9)
ax.legend()
ax.grid()
Podemos ver que, a pesar que están muy cerca una de la otra, el modelo ajustado está un poco más a la izquierda que el otro modelo, lo que significa que da una mayor precisión con un recall dado. Aunque en este caso la diferencia no es mucha, en situaciones del mundo real, como un scoring de crédito, una diferencia de precisión del 1% o 2% puede significar miles o millones dólares.
Finalmente, es importante mencionar que el método de búsqueda exhaustiva de grillas no es el único método para ajustar muchos hiperparámetros al mismo tiempo. Podemos ver más métodos para ajustar hiperparámetros en la documentación de scikit-learn, como el método de optimización de parámetros aleatorios.
Deja un comentario